Sarsa(λ)
1. Sarsa(λ) 是基于Sarsa算法的一种提速算法,为什么是提速呢?
Sarsa算法:
-
属于
单步更新
行为准则Q-table -
每走一步都在更新Q-table,虽然每步都更新,但是只有获得宝藏时,
前一步才会有有效的更新
(图中大脚丫),其他的都没关联(图中小脚丫)
Sarsa(λ) 算法:(假设λ=n,n为所有步的步数)
-
属于
回合更新
行为准则Q-table -
等到回个结束做更新,但是
所有步都和获得宝藏有关系
(图中大脚丫),所以下回合走到宝藏的效率就会高一些

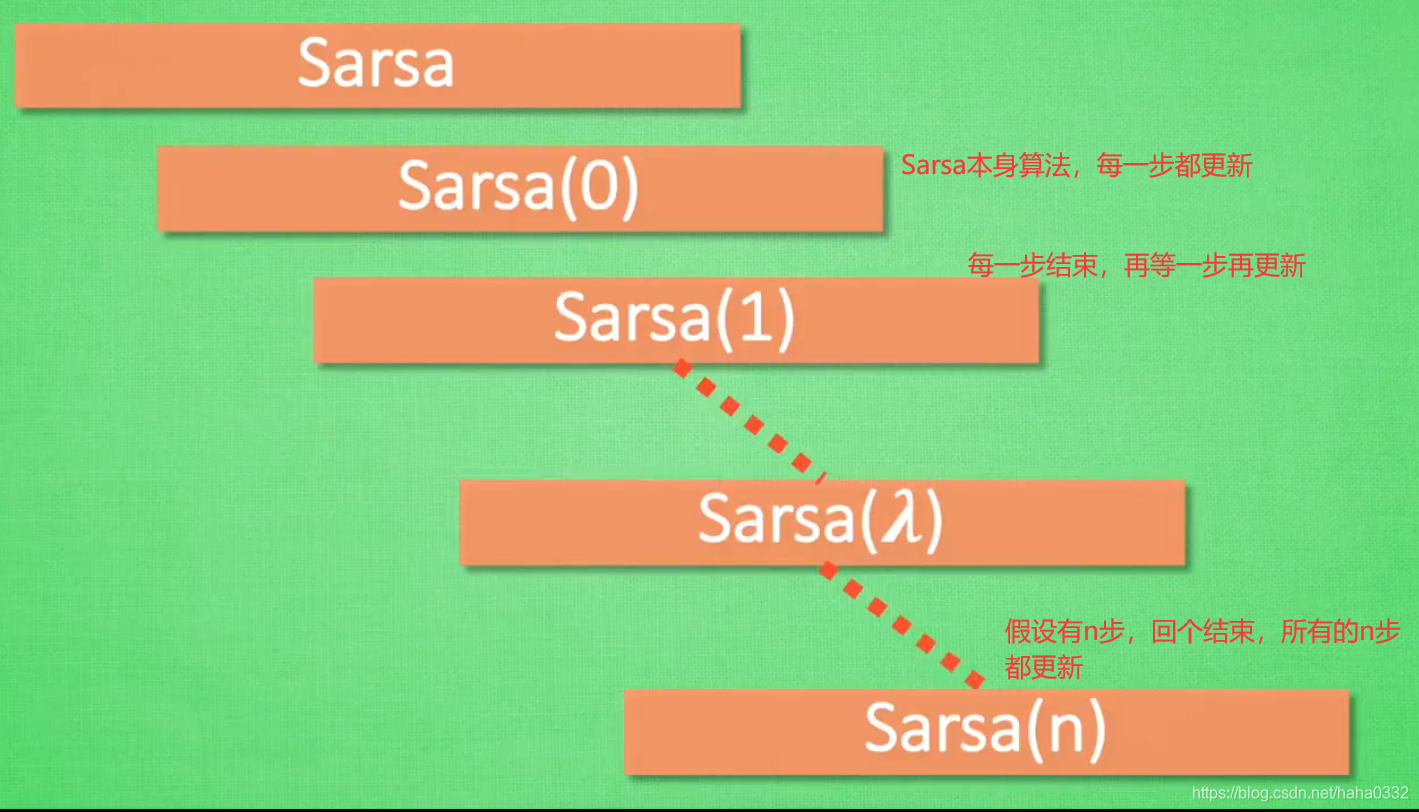
2. 如何理解Sarsa(λ)中的 λ?
-
Sarsa算法:每走一步都在更新行为准则Q-table,因为走完一步直接更新,没有间隙,我们可以称之为
Sarsa(0)
-
如果每一步结束,在等一步再更新行为准则Q-table,我们可以称之为
Sarsa(1)
- …
-
如果该行为有n步,回个结束再更新所有的n步的行为准则Q-table,则称之为
Sarsa(n)
因此,我们为了统一流程,选择 λ 来表示我们需要选择的步数,于是有了
Sarsa(λ)
所以
Sarsa(λ)
里的
λ
可以理解为:
-
脚步衰减值
(类似于我们之前提到的奖励衰减值 γ ) - 属于[0,1]之间
- 它可以让我们了解到离奖励越远的步可能并不是让我们最快能拿到奖励的步
从宝藏角度来看,离宝藏越近的步我们看的越清楚,越远的步越渺小,因此离奖励越近的步越重要,越需要更新它的行为准则Q-table
-
λ=0
,就是单步更新,本身的Sarsa算法 -
λ=1
,就是回合更新 -
0<λ<1
,表示离奖励越近的步行为准则更新力度越大

案例分析
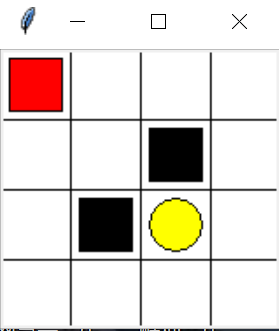
寻路案例:
建议先学习
Q-Learning 案例分析
、
Sarsa案例分析
- 红色为可移动的寻路个体
- 黑色为惩罚位置【奖励= -1】
- 黄色为目标位置【奖励= +1】
- 其他区域为常规状态【奖励= 0】
寻路个体其实位置如图中所示的左上角,目标是移动到黄色位置,采用算法,能够让个体自主探索,最后找到最好的可以从起始点到终点位置的路径,同时绕过黑色区域
程序
基于
Sarsa案例分析
,该案例的程序分为三个部分:
-
maze_env.py : 该案例的
环境部分
,即:该图片以及这些颜色块的搭建,采用了Tkinter,这部分暂时不细说 -
RL_brain.py:该案例的算法大脑,智能体的
大脑部分
,所有决策都在这部分 -
run_Sarsa.py:该案例的主要
实施流程以及更新
1. maze_env.py
与
Sarsa案例分析
里相同,暂不列出
2. RL_brain.py
基于
Sarsa案例分析
,集成RL类,与SarsaTable类很相似
建立SarsaLambdaTable类,与SarsaTable类最大的区别在于:
- def __init__方法中,加入lambda与eligibility_trace
-
lambda是脚步衰减值
λ
,eligibility_trace用来记录状态行为的影响度的表 - def check_state_exist 方法中,加入表eligibility_trace的初始化
- def learn 方法中,不只是单纯的更新Q-table,还要考虑eligibility_trace表中记录的影响
重点介绍一下eligibility_trace的用处
- eligibility_trace是一个与Q-table表头(状态,行为)一样的表
- 重点用来记录与获得奖励有关的那些状态和行为(这里可以成为步)
- 获得奖励时经历了哪些步,就给这些步做个标记并存储在eligibility_trace表中
- eligibility_trace记录的值是随着时间衰减的

class SarsaLambdaTable(RL): # 继承 RL class
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.5):
super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy) # 表示继承关系
self.lambda_ = trace_decay
self.eligibility_trace = self.q_table.copy()
# 检查状态是否存在,若不存在将作为索引添加在 q-table中,行为的值初始化为0
def check_state_exist(self, state):
if state not in self.q_table.index:
# 如果该状态不在q-table的索引里存在,则将该状态添加到q-table中,
# q-table是dataframe类型,字典的索引为状态,值的表头有四种【0,1,2,3】,分别代表前、后、左、右的行为
to_be_append = pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state,
)
self.q_table = self.q_table.append(to_be_append)
# 同样需要给eligibility表加上纯零的序列
self.eligibility_trace = self.eligibility_trace.append(to_be_append)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # q_target 基于选好的 a_ 而不是 Q(s_) 的最大值
else:
q_target = r # 如果 s_ 是终止符
error = q_target - q_predict
# Method 1:状态影响程度无封顶,采用+1
# self.eligibility_trace.loc[s, a] += 1
# Method 2: 状态影响程度最大为1
self.eligibility_trace.loc[s, :] *= 0 # 其他行为设为0
self.eligibility_trace.loc[s, a] = 1 # 采取行为为1
# 更新Q-table,与之前不同的是需要乘上elibigility_trace的影响
self.q_table += self.lr * error * self.eligibility_trace
# eligibility的值衰变更新
# 随着时间衰减 eligibility trace 的值, 离获取 reward 越远的步, 他的"不可或缺性"越小
self.eligibility_trace *= self.gamma * self.lambda_
3. run_SarsaLambda.py
与
Sarsa案例分析
里run_Sarsa.py 很相似,最大区别就是需要更新eligibility_trace
from maze_env import Maze
from RL_brain import SarsaLambdaTable
def update():
for episode in range(100):
print('回合数:' + str(episode + 1))
observation = env.reset() # 初始化环境
# Sarsa 根据 state 观测选择行为
action = RL.choose_action(str(observation))
# 新回合, 清零
RL.eligibility_trace *= 0
while True:
env.render() # 刷新环境
observation_, reward, done = env.step(action) # 在环境中采取行为, 获得下一个 state_ (obervation_), reward, 和是否终止
action_ = RL.choose_action(str(observation_)) # 根据下一个 state (obervation_) 选取下一个 action_
# 从 (s, a, r, s, a) 中学习, 更新 Q_tabel 的参数 ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# 将下一个当成下一步的 state (observation) and action
observation = observation_
action = action_
# 终止时跳出循环
if done:
break
# 大循环完毕
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = SarsaLambdaTable(actions=list(range(env.n_actions)))
env.after(100, update)
env.mainloop()
完成之后,在
run_SarsaLambda.py
里运行就可以看到 Sarsa(λ) 算法的学习探索路径的过程了
最后可以看看Sarsa(λ) 的伪代码,可以看到与Sarsa最大的几个区别,都有在上述程序里体现:

代码以及学习过程来源:
莫烦Python教学
(十分感谢莫烦大佬的教学视频)