

清华大学计算机系副教授裴丹于运维自动化专场发表了题为《基于机器学习的智能运维》的演讲,上篇参看“
科研角度谈“如何实现基于机器学习的智能运维”
文章,此为下篇。从百度运维实践谈基于机器学习的智能运维。以下为演讲实录,内容包括基于机器学习的智能运维的案例、挑战和思路。下面先讲一下实际的
三个百度案例
。

第一个场景
,横轴是时间,纵轴是百度的搜索流量,大概是一天几亿条的级别,随着时间的变化,每天早上到中午上升,到下午到晚上下去,我们要在这个曲线里面找到它的异常点,要在这样一个本身就在变化的曲线里面,能够自动化的找到它的坑,并且进行告警。
那么多算法,如何挑选算法?如何把阈值自动设出来?
这是第一个场景。
第二个场景
,我们要秒级。对于搜索引擎来说,就是要1秒的指标,这个时候有30%超过1秒,我们的目标是要降到20%及以下,如何找到具体的优化方法把它降下来?我们有很多优化工具,但是不知道到底用哪个,因为数据太复杂了,这是第二个应用场景。
第三个场景
,自动关联KPI异常与版本上线。上线的过程中,随时都有可能发生问题,发生问题的时候,如何迅速判断出来是你这次上线导致发生的问题?有可能是你上线导致的,也有可能不是,那么多因素,刚才说了几十万台机器,你怎么判断出来?这是百度实际搜索广告的收入,我们看到有一个上线事件,收入在上线之后掉下来了。
下面这个是我们一个学生在百度实习的时候做出来的一个方案,基于
机器学习的KPI自动化异常检测
。
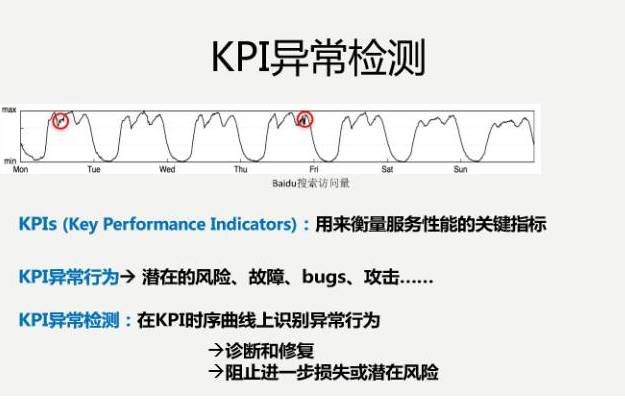
横轴是时间,纵轴是流量,要找到异常。
我们要迅速识别出来,并且准确识别出来,帮助我们迅速进行诊断和修复,进一步阻止潜在风险。
我们学术界,包括其他的领域,包括股票市场,已经研究几十年了,如何根据持续的曲线预测到下一个值是多少?有很多算法。我们的运维人员,就是我们的领域专家,会对自己检测的KPI进行负责,但是我们有海量的数据,这KPI又是千变万化各种各样的,三个曲线就很不一样,如何在这些具体的KPI曲线里取得良好的匹配?这是非常难的一件事情。
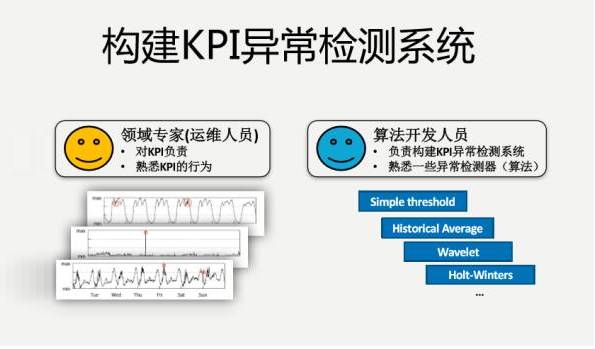
我们看看为什么是这样的?
有一个运维人员负责检测这样的曲线,假如说要试用一下算法,学术界的常规算法,要跟算法开发人员进行一些描述。算法开发人员说,你看我这儿有三个参数,把你的异常按照我的三个参数描述一下,运维人员肯定不干这个事情。开发人员还不了解KPI的专业知识,就想差不多做一做吧,做完了之后说你看看效果怎么样?往往效果差强人意,再来迭代一下,可能几个月就过去了。
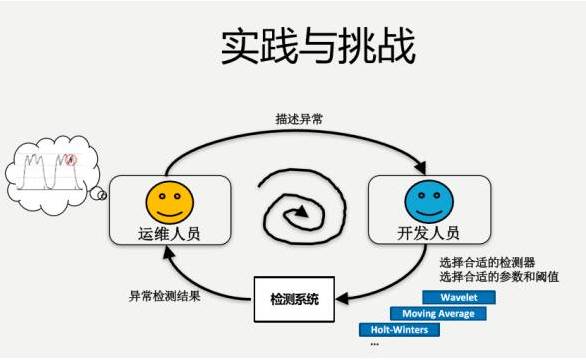
运维人员难以事先给出准确、量化的异常定义;对于开发人员来说,选择和综合不同的检测器需要很多人力;检测器算法复杂,参数调节不直观,这些都是存在的问题。
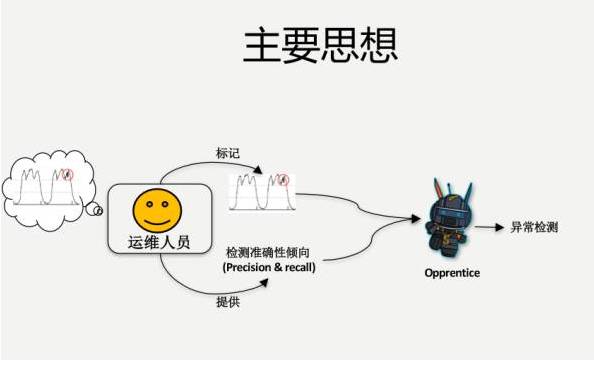
所以我们方法的主要思想是,做一个机器学习的工具。我们跟着运维人员学,做一个案例学一个,把他的知识学下来,不需要挑具体的检测算法,把这个事情做出来,根据历史的数据以及它的异常学到这个东西。
运维人员需要做什么事情?
我看着这些KPI的曲线,这段是异常,标注出来,就有了标注数据。本身就是有特征数据的,提供一下,说你这个小徒弟,你要想把它做好,我有一个要求,准确率要超过80%,小徒弟就拼命的跟师傅学。
具体做的时候,比如说KPI的具体曲线,假如说这里有一个异常点,我们把能拿到的理论界上,学术界上的各种算法都已经实现了,它还有各种参数,把参数空间扫一遍,大概100多种,用集体的智慧把KPI到底是不是异常,通过跟运维人员去学,把这个学出来。
为什么能够工作?
就是因为它的基本工作原理,就是我会学历史信息,学到了之后生成一些信号,对于同样的异常会有预测值,红色是检测出来的信号。检测出来的信号略有不同,但是我们觉得集体的智慧,能够最后给出一个非常好的效果,这就是一个基本的思路。
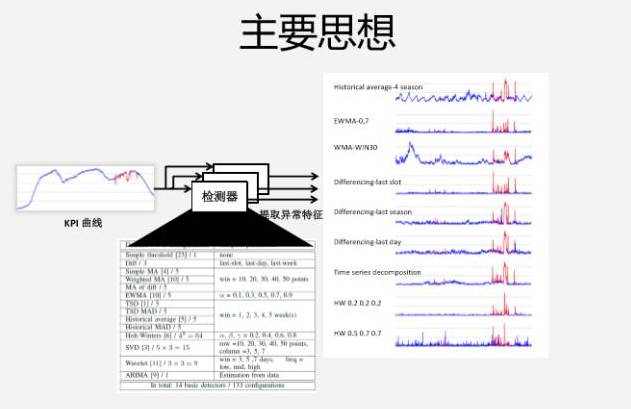
如何把它转化成机器学习的问题?
我们有特征数据、有标注,想要的就是它是异常还是非异常,就是一个简单的监督机器学习分类的问题。运维人员进行标注,产生各种特征数据,这就是刚才100多种检测器给出的特征数据,然后进行分类,效果还是比较理想的。
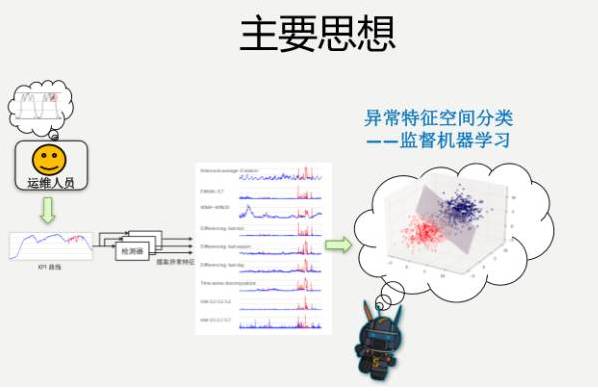
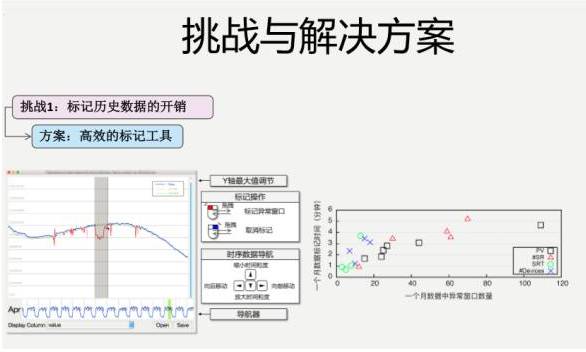
但是,还是有很多实际的挑战,我们简单提一个挑战。第一个挑战,我们运维人员需要标注,
我得花多长时间去标注?
在实际运维过程中,那些真正的异常并没有那么多,本身数量相对比较少。如果能做出一些比较高效的标记工具,是能够很好的帮助我们的。
如果把这个标注工具像做一个互联网产品一样,做得非常好,能够节省标注人员很多的时间。我们做了很多工作,鼠标加键盘,浏览同比、环比的数据,上面有放大缩小,想标注一个数据,拿着鼠标拖一下就OK了。一个月里面的异常数据,最后由运维人员实际进行标注,大概一个月也就花五六分钟的时间,就搞定了。
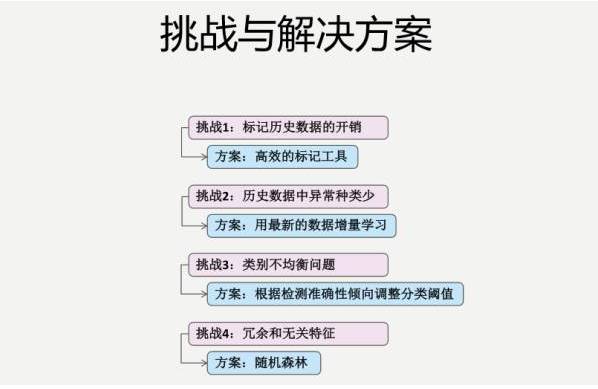
还有很多其他的挑战,比如说历史数据中异常种类比较少,类别不均衡问题,还有冗余和无关特征等。
下面是一个整体的设计。那么,
拿实际运维的数据进行检测的时候效果怎么样呢?

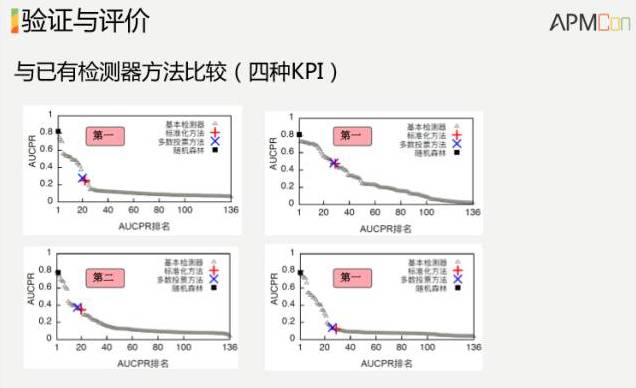
这里拿了四组数据,
三组是百度的,一组是清华校园网的。
一般的操作,分别对这些数据配一组阈值。我们不管这个数据是什么样的,就是用一种算法把它搞定,就拿刚才给出的运维小徒弟这样的算法,把100多种其他的算法都跑了一遍,比较了一下,在四组数据里面,我们算法的准确率不是第一就是第二,而且我们的好处是不用调参数。超过我们这个算法,普通的可能要把100多种试一下,我们这个不用试,直接就出来。
为了让运维更高效,可以让告警工作更智能,无需人工选择繁杂的检测器,无需调参,把它做得像一个互联网产品一样好。
这是第一个案例,关于智能告警的。
理论上学术界有很多漂亮的算法,如何在实际中落地的问题,在这个过程中我们使用的是机器学习的方案。
我们看一下第二个案例,刚才说的秒级。先看一个概念,搜索响应时间。
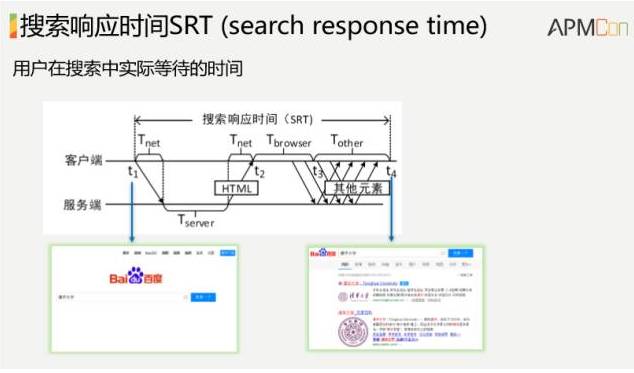
搜索响应时间,这个就是首屏时间了。对于综合搜索来说,用户在浏览器上输入一个关键字,点一下按纽,直到首屏搜索结果返回来,当然这里面有一些过程。
这个为什么很重要?
这就是钱。对于亚马逊来说,如果响应时间增加100毫秒,销量降低1%。对于谷歌来说,每增加100毫秒到400毫秒搜索,用户数就会下降0.2%到0.6%,所以非常重要。
看一下在实际中搜索响应时间是什么样的?
横轴是搜索响应时间,纵轴是CDF。70%的搜索响应时间是低于1秒,是符合要求的。30%的时间是高于1秒的,是不达标的。
那怎么办呢?
大于1秒的搜索原因到底是什么?如何改进?这里面也是一个机器学习的问题。各种日志非常多,答案就藏在日志里面,问题是如何拿到日志分析出来。我们看一下日志的形式:

对于用户每一次搜索,都有他来自于哪个运营商,浏览器内核是什么,返回结果里面图片有多少,返回结果有没有广告,后台负载如何等信息。这次响应,它的响应时间是多少,大于1秒就是不理想,小于1秒就是比较理想,我们有足够多的数据,一天上亿,还有标注,这个标注比较简单了。
我们现在来回答几个问题,在这么多维度的数据里边,
如何找出它响应时间比较高的时候,高响应时间容易发生的条件是什么?
哪些HSRT条件比较流行?如果找出流行的条件,我们就找到了一些线索,就知道如何去优化。我们能不能在实际优化之前,事先看一下,有可能优化的结果是什么?基本上想做的就是这么一个事情。这里面有些细节我们就跳过,想表达的意思是说对于多维度数据,如果只看单维度的数据,会有各种各样的问题。
在分析多维属性搜索日志的时候也会有很多挑战
-
第一,单维度属性分析方法无法揭示不同条件属性的组合带来的影响。
-
第二,属性之间还存在着潜在的依赖关系,所以单维度分析的结论可能是片面的。
-
第三,得到的HSRT条件可重叠,每次HSRT被计算多次,不易理解。你如果单维度看,图片数量大于30%,贡献了50%的响应时间,看一下其他的维度,加起来发现120%,这都是单维度看存在的问题。
因为每个维度有各种各样的取值,一旦组合,空间就爆炸了,人是不可能做的,就算是做了可视化的工具,人是不可能一个个试来得出结论,必须靠机器学习的方法,所以我们把这个问题
建模成分类问题
,利用
监督机器学习算法
,
决策树得到直观分类模型
。
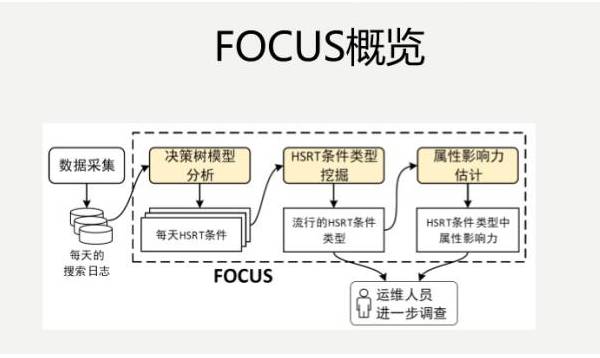
下面这个是我们当时设计的一个架构图,每天日志来了之后,输入到机器学习决策树的模型里面,分析出每天高响应时间的条件,跨天进行分析,之后再去做一些准实验,最后得出一些结果。
下面这个是我们第一步完成了之后,得出的一个决策树,生成决策树的过程,基本上拿一些现成的工具,把数据导进去,调一些参数就可以了。
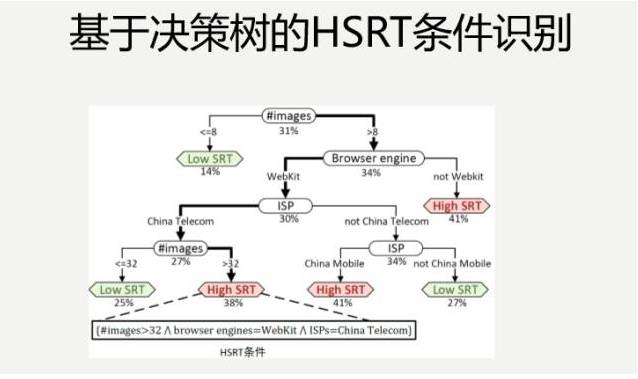
我们会看一个月的时间内,每天都获得的数据,我们得出一个月里面,哪些条件比较流行,然后,在此基础上,做一些准实验。不是说分析出来了之后,就真的上线调这些优化条件,比如说得出这样的组合,当图片数量大于10,它的浏览器引擎不是WebKit,里面没有打广告,它会容易响应时间比较高。
给了我们一些启示,具体哪个条件导致的?优化哪个维度会产生比较好的结果?
这不知道。我如果把每个条件调一下,这个大于10,变成小于10,这个条件的组合,在实际的日志数据里面就是存在的,把这个数据取出来,看一下它的响应延迟到底是高还是低,这就是准实验,诸如此类都做一些,很容易得出一些结论。
我们针对当时的场景,图片数量过多是导致响应时间比较长的主要瓶颈,是当时最重要的瓶颈,具体对这个进行了优化,大家可能就比较熟悉了,部署了base64 encoding来提高“数量多、体积小”的图片传输速度。
这里想强调一点,这个优化方式,大家都知道,但是在没有这样分析的情况下,你并没有把握上线之后,就有效果。假如说你运维部门的KPI指标,超过20%就不达标,如果低于20%就达标了,上线这一个就达标了。各种比较都很清晰,就是这样的一个工具,有很多日志,你做一些基于机器学习的分析,找到目前最重要的瓶颈,把这些瓶颈跟拿到手的各种优化的方式方法,应用一下,就能得到很好的效果,这个效果是很不错的,通用性也比较高。
第三个案例跳过去吧,大概意思是说自动更新会产生很多问题,我简单直接把案例给出来就好了。
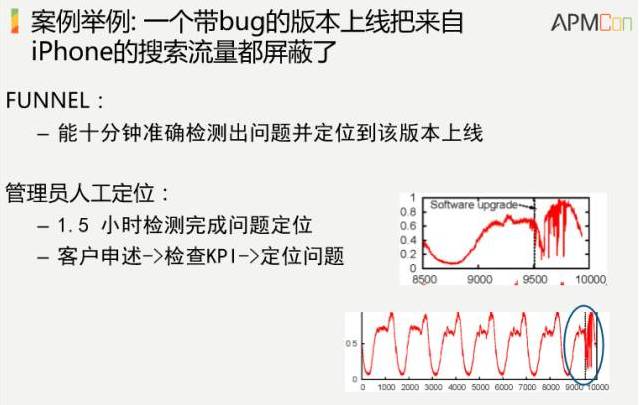
最后给出一个案例
,这个案例就是说百度上线了一个反点击作弊的版本,上线之后,广告收入就出现了下降,实际上用我们这个系统做了一下,10分钟能够准确检测出问题。而人在具体做的时候,要客户申述、检查KPI、定位问题,要一个半小时,差异还是很大的。
刚才举了几个具体的案例,其实还有其他的很多案例,如异常检测之后的故障定位、故障止损建议、故障根因分析、数据中心交换机故障预测、海量Syslog日志压缩成少量有意义的事件、基于机器学习的系统优化(如TCP运行参数)。
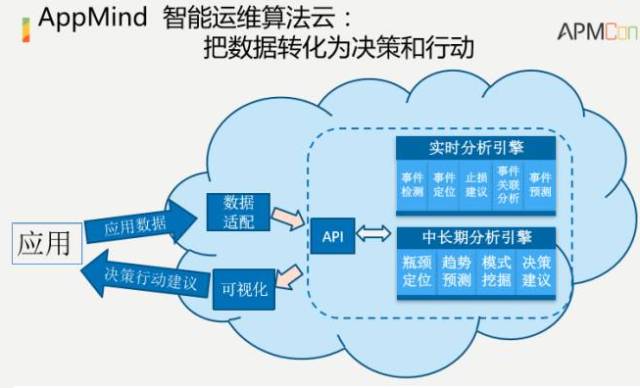
我们在学术界来说,我们也不做产品,我们是针对一线生产环境中遇到的各种有挑战性的问题,做一些具体的算法。我们的目标就是做一些智能运维算法的集合,运行在云上面,它会有一些标准的API。标准的API支持任意时序数据,它有一个时间戳,有一个关键指标,这个关键指标针对不同场景会不一样,有销售额、利润、订单数、转化率等等不同属性,经过这样的分析之后,跑到云里面,就能得出一些通用性的结果。
这里我想给大家一些具体的启示,包括我们自己的一些思考。
智能运维到底有哪些可行的目标?我们的步子不能迈得太大,又不能太保守,我们到底想达到什么样的效果?谁拿着枪,谁就处于主导地位。像R2-D2是运维人员的可靠助手,最后还是人来起主导作用。
1、很重要的就取决于人工智能本身发展到哪个地步,
人工智能解决了一些问题,知其然,又知其所以然。
知其然,不知其所以然,这个其我知道它下的好,但是为什么好,计算机算出来的,我并不知道。人工智能发展到现在的阶段,比较可靠的是这个地步:知其然,而不知其所以然,技术方面,通过机器学习相对成熟,在一定条件下比人好。到后面既不知其然,又不知其所以然,以及连问题都不知道,人工智能还没有到那个地步。我们要自动化那些“知其然而不知其所以然”的运维任务。
2、
如何更系统的应用机器学习技术。
机器学习纷繁复杂,简单说一下。特征选取的时候,早期可以用一些全部数据 容忍度高的算法,如随机森林,还有特征工程、自动选取(深度学习);不同机器学习算法适用不同的问题;一个比较行之有效的方法,大家做日常运维过程中,可以跟学术界进行具体探讨,针对眼前问题一起探讨一下,可能比较容易找到适合的起点。工业界跟学术界针对具体问题进行密切合作是一个有效的策略。
3、如何从现有ticket数据中提取有价值信息。我们可以把ticketing系统作为智能运维的一部分来设计。
4、
如何把智能运维延伸到智能运营?
我们有各种各样的数据,数据都在那儿,企业的痛点是,光有海量数据,缺乏真正精准的运营和行动之间有效转化的工具。其实我们思考一下,我们看的那些KPI,如果抽象成时序数据,跟电商的销售数据,跟游戏的KPI指标没有本质的区别。如果抽象成算法层面,可能都有很好的应用场景,具体还会有一些额外的挑战,但是如果在算法层面进行更多投入,可以跳出运维本身到智能运营这块。
总结一下今天的内容,基于机器学习的智能运维,
在今后几年会有飞速的发展,因为它有得天独厚的数据、标注和应用。
智能运维的终极可行目标,是运维人员高效可靠的助手。智能运维能够更系统应用机器学习技术,学术界和工业界应能够在一些具体问题上密切合作。更系统的数据采集和标注会帮助智能运维更快发展。下一步把智能运维的技术延伸到智能运营里面。
相关阅读
温馨提示:
请搜索
“ICT_Architect”
或
“扫一扫”
二维码关注公众号,点击
原文链接
获取更多
技术资料
。

求知若渴, 虚心若愚—
Stay hungry,
Stay foolish
