一、简介
Python语言多用于爬虫及工具的开发,人生苦短,我用python。这篇文章我将简要讲述一下python爬虫的用法及思路。
所谓爬虫,简单来说就是开发者为了提高信息收集的效率,而用python语言去实现请求网页并且把自己需要的内容返回到一个文本或者其他储存数据的库里。也就是说,你想要知道这个网站所有需要的信息,你不可能一个个点击查看,这时候使用python语言编写出的爬虫,那么收集信息的效果也就事半功倍了。
二、原理
模拟用户 -> 合理请求 -> 解析部分 ->返回结果
python爬虫分为四个部分,作为网站的运营商来说,肯定是不希望除搜索引擎爬虫去爬取网站资源,因为这样会让服务器的带宽和性能减少,所以他们是希望把这些带宽花费到给用户去请求,那么这里也就使用了反爬机制,而作为爬虫和用户请求网站最本质的区别:是否为用户所使用的浏览器头,这是识别网络爬虫还是用户的根本
三、模拟用户
方法有两种一个是python库自带的一个模块,一个是直接从浏览器信息复制过来
方法一:
pip install fake-useragent 模块安装
from fake_useragent import UserAgent
import requests
ua = UserAgent() //实例化一个对象
headers = {
"User-Agent" : ua.ie //随机获取ie的浏览器头
}
url = 'http://xx.xx.xx.xx/xx'
resp = requests.get(url,headers=headers)
print(resp.text)
方法二:
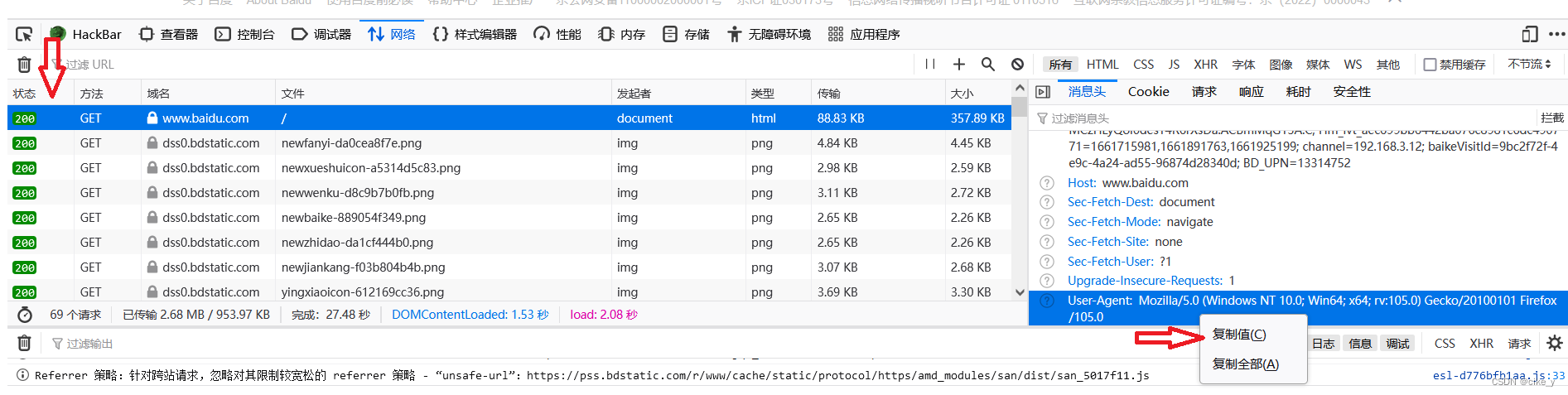
访问百度网站,这里以火狐浏览器为例,按F12键,如图点击第一个流量包,然后复制该值
四、合理请求
有的网站反爬机制做的很好,如果你的爬虫的请求速度没有控制的好,那么会直接封你的ip。
导入模块:import time
一般使用for 循环中请求中将使用time.sleep(3)三秒请求一次
五、解析部分
一般使用正则表达式,扣取返回原始页面的关键内容
代码演示:
resp = requests.get(url,headers=headers).text
obj = re.compile(r'azyload" href="(?P<lj>.*?)".*?title="(?P<title>.*?)".*?data-original="(?P<picture>.*?)".*?')
result = obj.finditer(resp)
for j in result:
print(j.group(“title”))
break
六、返回结果
为了让结果返回正确而不报错,考验到代码的逻辑问题并且不出现报错,通常这些做好了,返回结果也不会出现问题
请求完之后,为了避免连接不关闭的浪费资源,通常再for循环之后,在顶格使用关闭函数
e.close()
img_resp.close()