前言
在上一篇博客中,重点介绍了sparkSQL的由来,以及sparkSQL读取不同的数据源进行数据。我们知道,sparkSQL通过获取数据源中的数据形成SchemaRDD。在这篇博客中,我们就通过相应的查询命令读取数据。
通过方法查询
创建一个DataFrame对象,进行具体演示:

1)基础查询:
>tab1.select(“id”,”name”).show();—->select参数列表中的参数为列名
具体效果为:

2)带条件的查询
查询id为3的信息
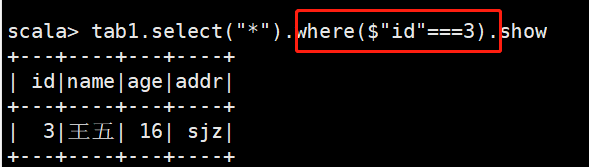
注意:这里在进行相等比较时,必须用三个”=”号,其中select函数中的”*”表示显示所有的列。
3)排序查询
orderBy/sort($”列名”)升序排序
orderBy/sort($”列名”.desc)降序排序
orderBy/sort($”列1″,$”列2″.desc)按两列排序
举个例子:
按照id进行升序排序,按照age进行降序排序

4)分组查询
groupBy(“列名”,。。。。).max(列名)求最大值
groupBy(“列名”,。。。。).min(列名)求最小值
groupBy(“列名”,。。。。).avg(列名)求平均值
groupBy(“列名”,.。。。。).sum(列名)求和
groupBy(“列名”,。。。。).count()求个数
groupBy(“列名”,。。。。).agg可以将多个方法进行聚合使用
在这里创建新的DataFrame进行演示。


5) 连接查询
创建新的DataFrame对象进行演示。

>dept.join(emp,$”deptid”===$”did”).show—->内连接

>dept.join(emp,$”deptid”===$”did”).show—>左外连接

左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
>dept.join(emp,$”deptid”===$”did”,”right”)—–>右外连接

6)执行运算

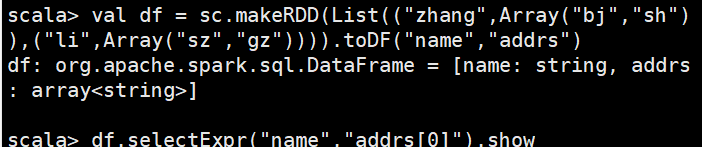
7)使用列表
8)使用结构体
{“name”:”陈晨”,”address”:{“city”:”西安”,”street”:”南二环甲字1号”}}
{“name”:”娜娜”,”address”:{“city”:”西安”,”street”:”南二环甲字2号”}}
>import org.apache.spark.sql.SQLContext
>val ssc=new SqlContext(sc)
>val df=ssc.read.json(“/home/software/users.json”)
>val result=df.select(“name”,”address.street”).show

9)其他
df.count//获取记录总数
val row=df.first()//获取第一条记录
val value=row.getString(1)//获取当前行的第一列的数据
df.collect//
获取当前
df
对象中的所有数据为一个
Array
其实就是调用了
df
对象对应的底层的
rdd
的
collect
方法