
1、窗口(Window)
1.1 Group Window(老版本)
在 Flink 1.12 之前的版本中,Table API 和 SQL 提供了一组“分组窗口”(Group Window)函数,常用的时间窗口如滚动窗口、滑动窗口、会话窗口都有对应的实现;
-
TUMBLE(time_attr, interval)
-
HOP(time_attr, interval, interval)
-
SESSION(time_attr, interval)
这里的 ts 是定义好的时间属性字段,窗口大小用“时间间隔”INTERVAL 来定义。
在进行窗口计算时,分组窗口是将窗口本身当作一个字段对数据进行分组的,可以对组内的数据进行聚合。基本使用方式如下:
Table groupWindowTable = tableEnv.sqlQuery("SELECT\n" + " user_name,\n" + " TUMBLE_START(ts, INTERVAL '5' SECOND) AS window_start,\n" + " count(url) \n" + "FROM my_student\n" + "GROUP BY\n" + " TUMBLE(ts, INTERVAL '5' SECOND),\n" + " user_name");tableEnv.toChangelogStream(groupWindowTable).print();
结果
# 第一个窗口+I[张三, 1970-01-01T08:00, 1]+I[李四, 1970-01-01T08:00, 1]+I[王五, 1970-01-01T08:00, 1]# 第二个窗口+I[张三, 1970-01-01T08:00:05, 2]+I[李四, 1970-01-01T08:00:05, 1]# 第三个窗口+I[王五, 1970-01-01T08:00:10, 2]+I[李四, 1970-01-01T08:00:10, 1]# 第四个窗口+I[李四, 1970-01-01T08:00:15, 1]
1.2 Windowing TVFs(新版本)
从 1.13 版本开始,Flink 开始使用窗口表值函数(Windowing table-valued functions,Windowing TVFs)来定义窗口。窗口表值函数是 Flink 定义的多态表函数(PTF),可以将表进行扩展后返回。表函数(table function)可以看作是返回一个表的函数。
目前 Flink 提供了以下几个窗口 TVF:
-
Tumble Windows
-
Hop Windows
-
Cumulate Windows
-
Session Windows (will be supported soon)
窗口表值函数可以完全替代传统的分组窗口函数。窗口 TVF 更符合 SQL 标准,性能得到了优化,拥有更强大的功能;可以支持基于窗口的复杂计算,例如窗口 Top-N、窗口联结(window join)等等。目前窗口 TVF 的功能还不完善。
在窗口 TVF 的返回值中,除去原始表中的所有列,还增加了用来描述窗口的额外 3 个列:
-
“窗口起始点”(window_start)
-
“窗口结束点”(window_end)
-
“窗口时间”(window_time)
起始点和结束点比较好理解,这里的“窗口时间”指的是窗口中的时间属性,它的值等于window_end – 1ms,所以相当于是窗口中能够包含数据的最大时间戳。
在 SQL 中的声明方式,与以前的分组窗口是类似的,直接调用 TUMBLE()、HOP()、CUMULATE()就可以实现滚动、滑动和累积窗口,不过传入的参数会有所不同。
1.2.1 滚动窗口(TUMBLE)
滚动窗口在 SQL 中的概念与 DataStream API 中的定义完全一样,是长度固定、时间对齐、无重叠的窗口,一般用于周期性的统计计算。
在 SQL 中通过调用 TUMBLE()函数就可以声明一个滚动窗口,只有一个核心参数就是窗口大小(size)。在 SQL 中不考虑计数窗口,所以滚动窗口就是滚动时间窗口,参数中还需要将当前的时间属性字段传入;另外,窗口 TVF 本质上是表函数,可以对表进行扩展,所以还应该把当前查询的表作为参数整体传入。具体声明如下:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
Flink SQL> SELECT * FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
Flink SQL> SELECT * FROM TABLE(
TUMBLE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SIZE => INTERVAL '10' MINUTES));
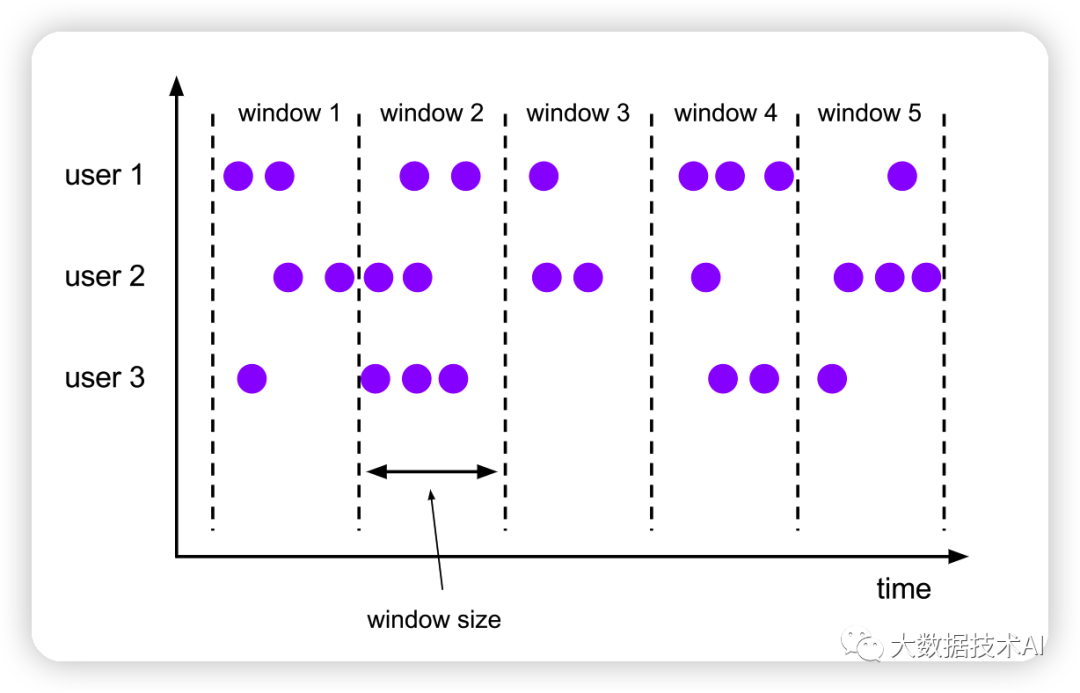
1.2.2 滑动窗口(HOP)
滑动窗口的使用与滚动窗口类似,可以通过设置滑动步长来控制统计输出的频率。在 SQL中通过调用 HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size)和滑动步长(slide)两个参数。
> SELECT * FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
HOP(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SLIDE => INTERVAL '5' MINUTES,
SIZE => INTERVAL '10' MINUTES));
1.2.3 累积窗口(CUMULATE)
滚动窗口和滑动窗口,可以用来计算大多数周期性的统计指标。
不过在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。
例如,我们按天来统计网站的 PV(Page View,页面浏览量),如果用 1 天的滚动窗口,那需要到每天 24 点才会计算一次,输出频率太低;如果用滑动窗口,计算频率可以更高,但统计的就变成了“过去 24 小时的 PV”。所以我们真正希望的是,还是按照自然日统计每天的PV,不过需要每隔 1 小时就输出一次当天到目前为止的 PV 值。这种特殊的窗口就叫作“累积窗口”(Cumulate Window)。
> SELECT * FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
CUMULATE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
STEP => INTERVAL '2' MINUTES,
SIZE => INTERVAL '10' MINUTES));
2、聚合(Aggregation)
2.1 分组聚合(Group Aggregation)
SQL 中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及 COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于“多对一”的转换以通过 GROUP BY 子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计,这种聚合方式,就叫作“分组聚合”(group aggregation)
从概念上讲,SQL 中的分组聚合可以对应 DataStream API 中 keyBy 之后的聚合转换,它们都是按照某个 key 对数据进行了划分,各自维护状态来进行聚合统计的。在流处理中,分组聚合同样是一个持续查询,而且是一个更新查询,得到的是一个动态表;每当流中有一个新的数据到来时,都会导致结果表的更新操作。因此,
想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式
;如果在代码中直接转换成 DataStream 打印输出,需要调用 toChangelogStream()。
另外,在持续查询的过程中,由于用于分组的 key 可能会不断增加,因此计算结果所需要维护的状态也会持续增长。为了防止状态无限增长耗尽资源,Flink Table API 和 SQL 可以在表环境中配置状态的生存时间(TTL):
// 获取表环境的配置
TableConfig tableConfig = tableEnv.getConfig();
// 配置状态保持时间
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));
或者也可以直接设置配置项 table.exec.state.ttl:
TableEnvironment tableEnv = ...
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.state.ttl", "60 min");
(1) GROUP BY
SELECT COUNT(*) FROM Orders GROUP BY order_id
(2) DISTINCT Aggregation
SELECT COUNT(DISTINCT order_id) FROM Orders
(3) GROUPING SETS
SELECT supplier_id, rating, COUNT(*) AS totalFROM (VALUES ('supplier1', 'product1', 4), ('supplier1', 'product2', 3), ('supplier2', 'product3', 3), ('supplier2', 'product4', 4))AS Products(supplier_id, product_id, rating)GROUP BY GROUPING SETS ((supplier_id, rating), (supplier_id), ())
+-------------+--------+-------+
| supplier_id | rating | total |
+-------------+--------+-------+
| supplier1 | 4 | 1 |
| supplier1 | (NULL) | 2 |
| (NULL) | (NULL) | 4 |
| supplier1 | 3 | 1 |
| supplier2 | 3 | 1 |
| supplier2 | (NULL) | 2 |
| supplier2 | 4 | 1 |
+-------------+--------+-------+
(4) HAVING
SELECT SUM(amount)FROM OrdersGROUP BY usersHAVING SUM(amount) > 50
2.2 窗口聚合(Window Aggregation)
1.13 版本开始使用了“窗口表值函数”(Windowing TVF),窗口本身返回的是就是一个表,所以窗口会出现在 FROM后面,GROUP BY 后面的则是窗口新增的字段 window_start 和 window_end。比如,我们将分组窗口的聚合,用窗口 TVF 重新实现一下
Table tvfWindowTable = tableEnv.sqlQuery("SELECT \n" + " user_name, window_start, window_end, count(url) cnt \n" + " FROM TABLE(\n" + " TUMBLE(TABLE my_student, DESCRIPTOR(ts), INTERVAL '5' SECOND))\n" + " GROUP BY user_name, window_start, window_end");tableEnv.toChangelogStream(tvfWindowTable).print();
结果
+I[张三, 1970-01-01T08:00, 1970-01-01T08:00:05, 1]+I[李四, 1970-01-01T08:00, 1970-01-01T08:00:05, 1]+I[王五, 1970-01-01T08:00, 1970-01-01T08:00:05, 1]+I[张三, 1970-01-01T08:00:05, 1970-01-01T08:00:10, 2]+I[李四, 1970-01-01T08:00:05, 1970-01-01T08:00:10, 1]+I[王五, 1970-01-01T08:00:10, 1970-01-01T08:00:15, 2]+I[李四, 1970-01-01T08:00:10, 1970-01-01T08:00:15, 1]+I[李四, 1970-01-01T08:00:15, 1970-01-01T08:00:20, 1]
Flink SQL 目前提供了滚动窗口 TUMBLE()、滑动窗口 HOP()和累积窗口(CUMULATE)三种表值函数(TVF)
累积窗口(CUMULATE)
Table cumulateWindowTable = tableEnv.sqlQuery("SELECT \n" + " window_start, window_end, count(url) cnt \n" + " FROM TABLE(\n" + " CUMULATE(TABLE my_student, DESCRIPTOR(ts), INTERVAL '5' SECOND, INTERVAL '5' SECOND))\n" + " GROUP BY window_start, window_end");tableEnv.toChangelogStream(cumulateWindowTable).print();
+I[1970-01-01T08:00, 1970-01-01T08:00:05, 3]+I[1970-01-01T08:00:05, 1970-01-01T08:00:10, 3]+I[1970-01-01T08:00:10, 1970-01-01T08:00:15, 3]+I[1970-01-01T08:00:15, 1970-01-01T08:00:20, 1]
相比之前的分组窗口聚合,Flink 1.13 版本的窗口表值函数(TVF)聚合有更强大的功能。除了应用简单的**聚合函数**、**提取窗口开始时间(window\_start)和结束时间(window\_end)之外**,窗口 TVF 还提供了一个 **window\_time** 字段,用于表示**窗口中的时间属性**;这样就可以方便地进行**窗口的级联(cascading window)**和计算了。另外,窗口 TVF 还支持 **GROUPING SETS**,极大地扩展了窗口的应用范围。
基于窗口的聚合,是流处理中聚合统计的一个特色,也是与标准 SQL 最大的不同之处。在实际项目中,很多统计指标其实都是基于时间窗口来进行计算的,所以窗口聚合是 Flink SQL中非常重要的功能;基于窗口 TVF 的聚合未来也会有更多功能的扩展支持,比如**窗口 Top N**、会话窗口、窗口联结等等。
### **2.3 开窗(Over)聚合**
在标准 SQL 中还有另外一类比较特殊的聚合方式,可以针对每一行计算一个聚合值。比如说,我们可以以每一行数据为基准,计算它之前 1 小时内所有数据的平均值;也可以计算它之前 10 个数的平均值。就好像是在每一行上打开了一扇窗户、收集数据进行统计一样,这就是所谓的“开窗函数”。
开窗函数的聚合与之前两种聚合有本质的不同:分组聚合、窗口 TVF聚合都是“多对一”的关系,将数据分组之后每组只会得到一个聚合结果;而开窗函数是对每行都要做一次开窗聚合,因此聚合之后表中的行数不会有任何减少,是一个“多对多”的关系。与标准 SQL 中一致,Flink SQL 中的开窗函数也是通过 OVER 子句来实现的,所以有时开窗聚合也叫作“OVER 聚合”(Over Aggregation)。基本语法如下:
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, …]]
ORDER BY time_col
range_definition),
…
FROM …
这里 OVER 关键字前面是一个聚合函数,它会应用在后面 OVER 定义的窗口上。在 OVER子句中主要有以下几个部分:
* **PARTITION BY(可选)**
用来指定分区的键(key),类似于 GROUP BY 的分组,这部分是可选的;
* **ORDER BY**
OVER 窗口是基于当前行扩展出的一段数据范围,选择的标准可以基于时间也可以基于数量。不论那种定义,数据都应该是以某种顺序排列好的;而表中的数据本身是无序的。所以在OVER 子句中必须用 ORDER BY 明确地指出数据基于那个字段排序。在 Flink 的流处理中,目前只支持按照时间属性的升序排列,所以这里 ORDER BY 后面的字段必须是定义好的时间340属性。
* **开窗范围**
对于开窗函数而言,还有一个必须要指定的就是开窗的范围,也就是到底要扩展多少行来做聚合。这个范围是由 BETWEEN <下界> AND <上界> 来定义的,也就是“从下界到上界”的范围。**目前支持的上界只能是 CURRENT ROW**,也就是定义一个“从之前某一行到当前行”的范围,所以一般的形式为:BETWEEN ... PRECEDING AND CURRENT ROW前面我们提到,开窗选择的范围可以基于时间,也可以基于数据的数量。所以开窗范围还应该在两种模式之间做出选择:范围间隔(RANGE intervals)和行间隔(ROW intervals)。
(1)范围间隔
范围间隔以 RANGE 为前缀,就是基于 ORDER BY 指定的时间字段去选取一个范围,一般就是当前行时间戳之前的一段时间。例如开窗范围选择当前行之前 1 小时的数据:
RANGE BETWEEN INTERVAL ‘30’ MINUTE PRECEDING AND CURRENT ROW
(2)行间隔
行间隔以 ROWS 为前缀,就是直接确定要选多少行,由当前行出发向前选取就可以了
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
案例:
Table over1WindowTable = tableEnv.sqlQuery(“SELECT user_name, ts,\n” + ” COUNT(url) OVER (\n” + ” PARTITION BY user_name\n” + ” ORDER BY ts\n” + ” RANGE BETWEEN INTERVAL ‘10’ SECOND PRECEDING AND CURRENT ROW\n” + ” ) AS cnt\n” + “FROM my_student”);tableEnv.toChangelogStream(over1WindowTable).print();
第一个10秒
+I[张三, 1970-01-01T00:00:01Z, 1]
+I[李四, 1970-01-01T00:00:02Z, 1]
+I[王五, 1970-01-01T00:00:03Z, 1]
+I[张三, 1970-01-01T00:00:05Z, 2]
+I[张三, 1970-01-01T00:00:06Z, 3]
+I[李四, 1970-01-01T00:00:08Z, 2]
10秒内,王五2次
+I[王五, 1970-01-01T00:00:11Z, 2]
10秒内,王五3次
+I[王五, 1970-01-01T00:00:12Z, 3]
10秒内,李四2次,第一次时间02,现在时间13
+I[李四, 1970-01-01T00:00:13Z, 2]
10秒内,李四3次
+I[李四, 1970-01-01T00:00:15Z, 3]
开窗聚合与窗口聚合(窗口 TVF 聚合)本质上不同,不过也还是有一些相似之处的:它们都是在无界的数据流上划定了一个范围,截取出有限数据集进行聚合统计;这其实都是“窗口”的思路。事实上,在 Table API 中确实就定义了两类窗口:分组窗口(GroupWindow)和窗窗口(OverWindow);而在 SQL 中,也可以用 WINDOW 子句来在 SELECT 外部单独定义一个 OVER 窗口:
SELECT order_id, order_time, amount,
SUM(amount) OVER w AS sum_amount,
AVG(amount) OVER w AS avg_amount
FROM Orders
WINDOW w AS (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL ‘1’ HOUR PRECEDING AND CURRENT ROW)
Table over2WindowTable = tableEnv.sqlQuery(“SELECT user_name, url,ts,\n” +
” COUNT(url) OVER w AS cnt,\n” +
” MAX(CHAR_LENGTH(url)) OVER w AS avg_amount\n” +
“FROM my_student\n” +
“WINDOW w AS (\n” +
” PARTITION BY user_name\n” +
” ORDER BY ts\n” +
” RANGE BETWEEN INTERVAL ‘10’ SECOND PRECEDING AND CURRENT ROW)”);
tableEnv.toChangelogStream(over2WindowTable).print();
+I[张三, ./home, 1970-01-01T00:00:01Z, 1, 6]+I[李四, ./cart, 1970-01-01T00:00:02Z, 1, 6]+I[王五, ./prod?id=1, 1970-01-01T00:00:03Z, 1, 11]+I[张三, ./home, 1970-01-01T00:00:05Z, 2, 6]+I[张三, ./home, 1970-01-01T00:00:06Z, 3, 6]+I[李四, ./cart, 1970-01-01T00:00:08Z, 2, 6]# 10s内,王五2次,url最大11+I[王五, ./prod?id=1, 1970-01-01T00:00:11Z, 2, 11]# 10s内,王五3次,url最大11+I[王五, ./prod?id=1, 1970-01-01T00:00:12Z, 3, 11]# 10s内,李四3次,url最大11+I[李四, ./prod?id=7, 1970-01-01T00:00:13Z, 3, 11]# 10s内,李四四次,url最大11+I[李四, ./prod?id=7, 1970-01-01T00:00:15Z, 4, 11]
### **2.4 Top N**
理想的状态下,我们应该有一个 TOPN()聚合函数,调用它对表进行聚合就可以得到想要选取的前 N 个值了。不过仔细一想就会发现,这个聚合函数并不容易实现:对于每一次聚合计算,都应该都有多行数据输入,并得到 N 行结果输出,这是一个真正意义上的“多对多”转换。这种函数相当于把一个表聚合成了另一个表,所以叫作“表聚合函数”(Table Aggregate Function)。表聚合函数的抽象比较困难,目前只有窗口 TVF 有能力提供直接的 Top N 聚合,不过也尚未实现。所以目前在 Flink SQL 中没有能够直接调用的 Top N 函数,而是提供了稍微复杂些的变通实现方法。
#### **2.4.1 普通Top N**
在 Flink SQL 中,是通过 OVER 聚合和一个条件筛选来实现 Top N 的。具体来说,是通过将一个特殊的聚合函数ROW\_NUMBER()应用到OVER窗口上,统计出每一行排序后的行号,作为一个字段提取出来;然后再用 WHERE 子句筛选行号小于等于 N 的那些行返回
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2…]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]…]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]
**2.4.2 Window Top-N**
除了直接对数据进行 Top N 的选取,我们也可以针对窗口来做 Top N。例如电商行业,实际应用中往往有这样的需求:统计一段时间内的热门商品。这就需要先开窗口,在窗口中统计每个商品的点击量;然后将统计数据收集起来,按窗口进行分组,并按点击量大小降序排序,选取前 N 个作为结果返回。
我们已经知道,Top N 聚合本质上是一个表聚合函数,这和窗口表值函数(TVF)有天然的联系。尽管如此,想要基于窗口 TVF 实现一个通用的 Top N 聚合函数还是比较麻烦的,目前Flink SQL尚不支持。不过我们同样可以借鉴之前的思路,使用OVER窗口统计行号来实现。具体来说,可以先做一个窗口聚合**,将窗口信息 window\_start、window\_end 连同每个商品的点击量一并返回,这样就得到了聚合的结果表,包含了窗口信息、商品和统计的点击量**。
接下来就可以像一般的 Top N 那样定义 OVER 窗口了,按窗口分组,按点击量排序,用ROW\_NUMBER()统计行号并筛选前 N 行就可以得到结果。所以窗口 Top N 的实现就是窗口聚合与 OVER 聚合的结合使用。
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1…]
ORDER BY col1 [asc|desc][, col2 [asc|desc]…]) AS rownum
FROM table_name) – relation applied windowing TVF
WHERE rownum <= N [AND conditions]
Table topWindowTable = tableEnv.sqlQuery(“SELECT *\n” + ” FROM (\n” + ” SELECT *, \n” + ” ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY cnt DESC) as rownum\n” + ” FROM (\n” + ” SELECT window_start, window_end, user_name, COUNT(url) as cnt\n” + ” FROM TABLE(\n” + ” TUMBLE(TABLE my_student, DESCRIPTOR(ts), INTERVAL ‘10’ SECOND))\n” + ” GROUP BY window_start, window_end, user_name\n” + ” )\n” + ” ) WHERE rownum <= 2″);tableEnv.toChangelogStream(topWindowTable).print();
0-10s窗口内,张三3次,排第一
+I[1970-01-01T08:00, 1970-01-01T08:00:10, 张三, 3, 1]
+I[1970-01-01T08:00, 1970-01-01T08:00:10, 李四, 2, 2]
10-20s窗口内,王五2次,排第一
+I[1970-01-01T08:00:10, 1970-01-01T08:00:20, 王五, 2, 1]
+I[1970-01-01T08:00:10, 1970-01-01T08:00:20, 李四, 2, 2]
