STL其他内容解析:
关于C++中STL的理解和应用
unordered_map介绍
无序映射是关联容器,用于存储由键值和映射值组合而成的元素,并允许基于键快速检索各个元素。
在unordered_map中,键值通常用于唯一标识元素,而映射值是与该键关联的内容的对象。键和映射值的类型可能不同。
在内部,unordered_map中的元素没有按照它们的键值或映射值的任何顺序排序,而是根据它们的散列值组织成桶以允许通过它们的键值直接快速访问单个元素(具有常数平均时间复杂度)
unordered_map容器比映射容器更快地通过它们的键来访问各个元素,尽管它们通过其元素的子集进行范围迭代通常效率较低。
无序映射实现直接访问操作符(operator []),该操作符允许使用其键值作为参数直接访问映射值。
容器中的迭代器至少是前向迭代器。
unordered_map用法
unordered_map和map的用法完全一致
,这里仅写出一个代码实例,具体可看:
C++STL中map的底层实现和使用
#include<iostream>
#include<string>
#include<unordered_map>
using namespace std;
int main(){
unordered_map<string,int> s; //map定义
unordered_map<string,int>::iterator it; //迭代器
//插入元素的三种方法
s.insert(make_pair("Amey",99));
s.insert(pair<string,int>("Maroon",100));
s["Tom"]=88;
//查找的两种方法 count和find
cout<<s.count("Tom")<<endl;
it=s.find("Thm");
if (it==s.end()) cout<<"No"<<endl;
else cout<<it->first<<" "<<it->second<<endl;
//删除的两种方法
s.erase("Tom");
it=s.find("Amey");
s.erase(it);
//迭代器遍历方法
for(it=s.begin(); it!= s.end(); it++){
cout<<it->first<<" "<<it->second<<endl;
}
}
unordered_map底层实现
unordered_map底层是用
开链法
来解决
哈希冲突
的,用
哈希桶
实现的。
如图:
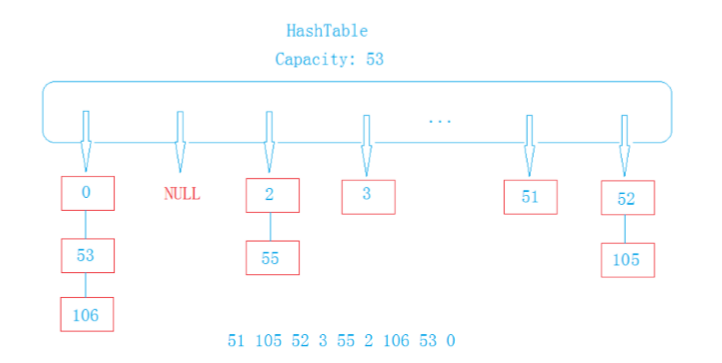
底层结构代码:
template<typename K, typename V> //每个节点的结构
struct HashNode
{
pair<K, V> _kv;
HashNode<K,V>* _next;
HashNode(pair<K,V> p)
:_next(NULL)
, _kv(p)
{}
};
template<typename K, typename V, class HashFunc = _HashFunc<K>> //哈希表的结构,第三个参数是仿函数,为了实现可以存储string
class HashTable
{
protected:
vector<Node*> _table;
size_t _size;
};
1.用一个
vector
来作为一个
指针数组
来存储节点的指针,_size来保存当前哈希表中的有效元素个数。
2.由于是K/V结构,所以选择一个pair的结构来存储K/V。
3.vector中的每一个元素都指向一个
链表
,所有节点中需要一个next域的指针来指向下一个节点(采用单链表表结构)。
4.采用模板来实现哈希表可以存储任意数据类型的目的。
5.使用了仿函数技术(为了实现可以存储string)。
unordered_map的扩容机制与vector类似。
map和unordered_map的比较:
map
优点:
map内部实现是红黑树,有序性是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作,其复杂度为logN。
缺点:
空间占用率高,因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间。
适用处:
对于那些有顺序要求的问题,用map会更高效一些。
unordered_map
优点:
内部实现是哈希表,因此其查找速度非常的快,复杂度为O(1)。
缺点:
更改哈希表的大小,重构哈希表比较耗费时间。
适用处:
对于查找问题,unordered_map会更加高效一些。
使用时map的key需要定义operator<。unordered_map要求传入的数据能够进行大小比较,“==”关系比较;所以自定义数据需要定置hash_value仿函数同时重载operator==。