人工智能三学派,tf.cast ,tf.reduce_mean,tf.convert_to_tensor,tf.data.Dataset.from_tensor_slices, tf.GradientTape( ),tf.nn.softmax( )
tf.Variable,assign_sub ,enumerate, tf.one_hot, tf.argmax,
参数初始化,利用鸢尾花数据集,实现前向传播、反向传播,可视化loss曲线,本地读取csv数据,生成规则张量,输入标准化。
- 人工智能三学派:1.行为主义:一个感知,动作的控制系统。2.符号主义:就是专家系统。3.联结主义:深度学习。
- tf.cast (张量名,dtype=数据类型)强制将 Tensor 转换为该数据类型
- tf.reduce_mean (张量名,axis=操作轴)计算张量沿着指定维度的平均值;可用 f.reduce_sum (张量名,axis=操作轴)计算张量沿着指定维度的和,如不指定 axis,则表示对所有元素进行操作。
import tensorflow as tf
x1 = tf.constant([[1.,2.,3.],[4.,5.,6.]],tf.float32)
print("x1:", x1)
x2 = tf.cast(x1,tf.int32)
print("x2", x2)
print("minimum of x2:", tf.reduce_min(x2))
print("maxmum of x2:", tf.reduce_max(x2))
print("minimum of x2:", tf.reduce_min(x1,axis=0))
print("maxmum of x2:", tf.reduce_max(x2,axis=1))
out:
x1: tf.Tensor(
[[1. 2. 3.]
[4. 5. 6.]], shape=(2, 3), dtype=float32)
x2 tf.Tensor(
[[1 2 3]
[4 5 6]], shape=(2, 3), dtype=int32)
minimum of x2: tf.Tensor(1, shape=(), dtype=int32)
maxmum of x2: tf.Tensor(6, shape=(), dtype=int32)
minimum of x2: tf.Tensor([1. 2. 3.], shape=(3,), dtype=float32)
maxmum of x2: tf.Tensor([3 6], shape=(2,), dtype=int32)
Process finished with exit code 0
- 为了更好的理解axis的含义
import tensorflow as tf
x = tf.constant([[1, 2, 3], [2, 2, 3]])
print("x:", x)
print("mean of x:", tf.reduce_mean(x)) # 求x中所有数的均值
print("sum_[2,(3)] of x:", tf.reduce_sum(x, axis=1)) # 求每一行的和
print("sum_[(2),3] of x:", tf.reduce_sum(x, axis=0)) # 列
out:
x: tf.Tensor(
[[1 2 3]
[2 2 3]], shape=(2, 3), dtype=int32)
mean of x: tf.Tensor(2, shape=(), dtype=int32)
sum_[2,(3)] of x: tf.Tensor([6 7], shape=(2,), dtype=int32)
sum_[(2),3] of x: tf.Tensor([3 4 6], shape=(3,), dtype=int32)
Process finished with exit code 0
import numpy as np
import tensorflow as tf
test = np.array([[1, 2, 3], [2, 3, 4], [5, 4, 3], [8, 7, 2]])
print("test:\n", test)
print("每一列的最大值的索引:", tf.argmax(test, axis=0)) # 返回每一列最大值的索引
print("每一行的最大值的索引", tf.argmax(test, axis=1)) # 返回每一行最大值的索引
out:
每一列的最大值的索引: tf.Tensor([3 3 1], shape=(3,), dtype=int64)
每一行的最大值的索引 tf.Tensor([2 2 0 0], shape=(4,), dtype=int64)
- tf.data.Dataset.from_tensor_slices((输入特征, 标签))切分传入张量的第一维度,生成输入特征/标签对,构建数据集,此函数对 Tensor 格式与 Numpy格式均适用,其切分的是第一维度,表征数据集中数据的数量,之后切分 batch等操作都以第一维为基础。
import tensorflow as tf
features = tf.constant([12, 23, 10, 17])
labels = tf.constant([0, 1, 1, 0])
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
for element in dataset:
print(element)
out:
(<tf.Tensor: id=9, shape=(), dtype=int32, numpy=12>, <tf.Tensor: id=10, shape=(), dtype=int32, numpy=0>)
(<tf.Tensor: id=11, shape=(), dtype=int32, numpy=23>, <tf.Tensor: id=12, shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: id=13, shape=(), dtype=int32, numpy=10>, <tf.Tensor: id=14, shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: id=15, shape=(), dtype=int32, numpy=17>, <tf.Tensor: id=16, shape=(), dtype=int32, numpy=0>)
Process finished with exit code 0
- 可利用 tf.GradientTape( )函数搭配 with 结构计算损失函数在某一张量处的梯度。
- 可利用 tf.Variable(initial_value,trainable,validate_shape,name)函数可以将变量标记为“可训练”的,被它标记了的变量,会在反向传播中记录自己的梯度信息。
- 利用 assign_sub 对参数实现自更新。使用此函数前需利用 tf.Variable定义变量 w为可训练(可自更新)。
import tensorflow as tf
w = tf.Variable(tf.constant(5.,tf.float32))
lr = 0.2
epochs = 20
for epoch in range(epochs):
with tf.GradientTape() as tape:
loss = tf.square(w+1)
grads = tape.gradient(loss,w)
w.assign_sub(lr*grads)
print("After %s epoch,w is %f,loss is %f" % (epoch, w.numpy(), loss))
out:
After 0 epoch,w is 2.600000,loss is 36.000000
After 1 epoch,w is 1.160000,loss is 12.959999
After 2 epoch,w is 0.296000,loss is 4.665599
After 3 epoch,w is -0.222400,loss is 1.679616
After 4 epoch,w is -0.533440,loss is 0.604662
After 5 epoch,w is -0.720064,loss is 0.217678
After 6 epoch,w is -0.832038,loss is 0.078364
After 7 epoch,w is -0.899223,loss is 0.028211
After 8 epoch,w is -0.939534,loss is 0.010156
After 9 epoch,w is -0.963720,loss is 0.003656
After 10 epoch,w is -0.978232,loss is 0.001316
After 11 epoch,w is -0.986939,loss is 0.000474
After 12 epoch,w is -0.992164,loss is 0.000171
After 13 epoch,w is -0.995298,loss is 0.000061
After 14 epoch,w is -0.997179,loss is 0.000022
After 15 epoch,w is -0.998307,loss is 0.000008
After 16 epoch,w is -0.998984,loss is 0.000003
After 17 epoch,w is -0.999391,loss is 0.000001
After 18 epoch,w is -0.999634,loss is 0.000000
After 19 epoch,w is -0.999781,loss is 0.000000
Process finished with exit code 0
- enumerate(列表名)函数枚举出每一个元素,并在元素前配上对应的索引号,常在 for 循环中使用。
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i, element)
out:
0 one
1 two
2 three
- 可用 tf.one_hot(待转换数据,depth=几分类)函数实现用独热码表示标签,在分类问题中很常见。
import tensorflow as tf
classes = 3
labels = tf.constant([1, 0, 2]) # 输入的元素值最小为0,最大为2
output = tf.one_hot(labels, depth=classes)
print("result of labels1:", output)
print("\n")
out:
result of labels1: tf.Tensor(
[[0. 1. 0.]
[1. 0. 0.]
[0. 0. 1.]], shape=(3, 3), dtype=float32)
Process finished with exit code 0
- 可利用 tf.nn.softmax( )函数使前向传播的输出值符合概率分布,进而与独热码形式的标签作比较。熵的概念:熵越大不确定性越大,那么以熵作为损失函数,使其最小化的过程就是提高确定性的过程,用在分类问题中。交叉熵是在熵的基础上引进预测概率与真实标签的相似度作为第二度量,所以softmax很有必要。
import tensorflow as tf
y = tf.constant([1.01, 2.01, -0.66])
y_pro = tf.nn.softmax(y)
print("After softmax, y_pro is:", y_pro) # y_pro 符合概率分布
print("The sum of y_pro:", tf.reduce_sum(y_pro)) # 通过softmax后,所有概率加起来和为1
out:
After softmax, y_pro is: tf.Tensor([0.25598174 0.69583046 0.0481878 ], shape=(3,), dtype=float32)
The sum of y_pro: tf.Tensor(1.0, shape=(), dtype=float32)
- 利用 tf.argmax (张量名,axis=操作轴)返回张量沿指定维度最大值的索引。
- numpy类型和tensor类型不能混淆。
import tensorflow as tf
import numpy as np
b = np.array((1.,2.))
a = tf.constant((1.,2.),tf.float32,shape=(1,2))
print("a:", a)
print("a.dtype:", a.dtype)
print("a.shape:", a.shape)
print("b:", b)
print("b.dtype:", b.dtype)
print("b.shape:", b.shape)
out:
a: tf.Tensor([[1. 2.]], shape=(1, 2), dtype=float32)
a.dtype: <dtype: 'float32'>
a.shape: (1, 2)
b: [1. 2.]
b.dtype: float64
b.shape: (2,)
Process finished with exit code 0
- 将numpy类型转换为Tensor才可以包入求梯度的结构,使用函数tf.convert_to_tensor
import tensorflow as tf
import numpy as np
a = np.array((1.,2.))
b = tf.convert_to_tensor(a,tf.float32)
print("a:", a)
print("b:", b)
out:
a: [1. 2.]
b: tf.Tensor([1. 2.], shape=(2,), dtype=float32)
- 升成规则向量
import tensorflow as tf
a = tf.zeros((3,3))
b = tf.ones(3)
c = tf.fill((3,3),6)
print("a:", a)
print("b:", b)
print("c:", c)
out:
a: tf.Tensor(
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]], shape=(3, 3), dtype=float32)
b: tf.Tensor([1. 1. 1.], shape=(3,), dtype=float32)
c: tf.Tensor(
[[6 6 6]
[6 6 6]
[6 6 6]], shape=(3, 3), dtype=int32)
Process finished with exit code 0
- 在大型网络中初始化参数至关重要,几种初始化方式
import tensorflow as tf
#正态分布
a = tf.random.normal((3,3),mean=0.5,stddev=1)
print('a:',a)
#除去极端值的正态分布
b = tf.random.truncated_normal((3,3),mean=0.5,stddev=1)
print('b',b)
#均匀分布
c = tf.random.uniform((3,3),minval=1,maxval=10)
print('c',c)
out:
a: tf.Tensor(
[[ 2.0502691 -0.4864539 -0.9238609 ]
[ 2.5715983 0.12885198 0.21011427]
[ 0.8705125 0.02991194 0.5630778 ]], shape=(3, 3), dtype=float32)
b tf.Tensor(
[[-0.23354083 0.5798591 -0.04059154]
[ 0.6093621 0.78364 -0.962304 ]
[-0.91057456 1.8721603 0.5093775 ]], shape=(3, 3), dtype=float32)
c tf.Tensor(
[[1.9081112 9.149175 6.655161 ]
[5.4855995 3.8445973 9.56315 ]
[1.3791453 8.24509 6.923629 ]], shape=(3, 3), dtype=float32)
Process finished with exit code 0
- 综合运用!利用鸢尾花数据集,实现前向传播、反向传播,可视化loss曲线
- 认识数据集
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
print("x_data from datasets: \n", x_data)
print("y_data from datasets: \n", y_data)
x_data = DataFrame(x_data,columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度'])
pd.set_option('display.unicode.east_asian_width',True)
print("x_data add index: \n", x_data)
x_data['类别'] = y_data
print("x_data add index: \n", x_data)
out:
x_data add index:
花萼长度 花萼宽度 花瓣长度 花瓣宽度 类别
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2
[150 rows x 5 columns]
Process finished with exit code 0
- 实例:
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
np.random.seed(1)
np.random.shuffle(x_data)
np.random.seed(1)
np.random.shuffle(y_data)
tf.random.set_seed(1)
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
x_train = tf.cast(x_train,tf.float32)
x_test = tf.cast(x_test,tf.float32)
train_db = tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
w1 = tf.Variable(tf.random.truncated_normal((4,3),stddev=0.1))
b1 = tf.Variable(tf.random.truncated_normal([3],stddev=0.1))
lr = 0.1
train_loss_results = []
test_acc = []
epoch = 500
loss_all = 0
for epoch in range(epoch):
for step,(x_train,y_train) in enumerate(train_db):
with tf.GradientTape() as tape:
y = tf.matmul(x_train,w1) + b1
y = tf.nn.softmax(y)
y_ = tf.one_hot(y_train,depth=3)
loss = tf.reduce_mean(tf.square(y_-y))
loss_all += loss
grads = tape.gradient(loss,[w1,b1])
w1.assign_sub(lr*grads[0])
b1.assign_sub(lr*grads[1])
print("Epoch {}, loss: {}".format(epoch, loss_all / 4))
train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中
loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备
total_correct, total_number = 0, 0
for x_test,y_test in test_db:
y = tf.matmul(x_test,w1)+b1
y = tf.nn.softmax(y)
pred = tf.argmax(y,axis=1)
pred = tf.cast(pred,y_test.dtype)
correct = tf.cast(tf.equal(pred,y_test),tf.int32)
correct = tf.reduce_sum(correct)
total_correct += int(correct)
total_number += x_test.shape[0]
acc = total_correct / total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("--------------------------")
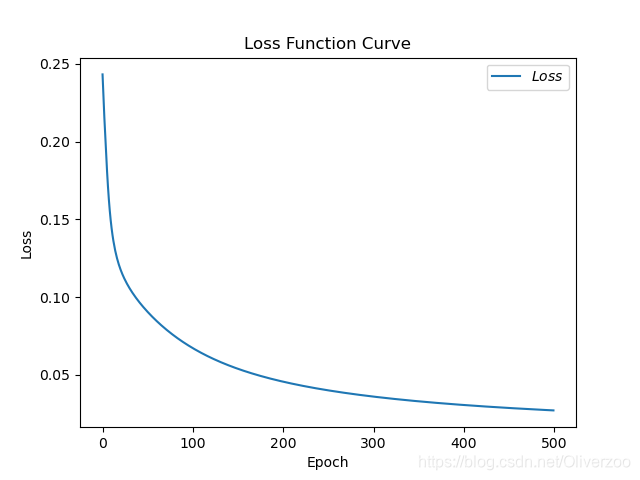
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()
out:
Epoch 496, loss: 0.027312560006976128
Test_acc: 0.9666666666666667
--------------------------
Epoch 497, loss: 0.027283424511551857
Test_acc: 0.9666666666666667
--------------------------
Epoch 498, loss: 0.027254387736320496
Test_acc: 0.9666666666666667
--------------------------
Epoch 499, loss: 0.02722545713186264
Test_acc: 0.9666666666666667
--------------------------
Process finished with exit code 0

- 本地读取数据:数据集收费了????
df = pd.read_csv(iris.txt,header=None)
data = df.values
x_data = [line[0:4] for line in data]
x_data = np.array(x_data,float)
y_data = [line[4] for line in data]
for i in range(len(y_data)):
if y_data[i] == 'aaa':
y_data[i] = 0
elif:
..........
y_data = np.array(y_data)
- 对于输入,不要太大,否则在梯度弥散(激活函数在输入多大或过小时梯度接近零),还会不收敛,每次更新太大。所以要标准化输入从而减小梯度。
def normalize(data):
x_data = data.T # 每一列为同一属性,转置到每一行
for i in range(4):
x_data[i] = (x_data[i] - tf.reduce_min(x_data[i])) /
(tf.reduce_max(x_data[i]) - tf.reduce_min(x_data[i]))
return x_data.T # 转置回原格式
版权声明:本文为Oliverzoo原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。