目录
什么是多租户:
多租户技术(英语:multi-tenancy technology)或称多重租赁技术,是一种软件架构技术,它是在探讨与实现如何于多用户的环境下共用相同的系统或程序组件,并且仍可确保各用户间数据的隔离性。
多租户带来的好处:
第一,系统维护成本低
多租户系统在系统升级时,只需要更新一次。
维护人员不需要对每个用户更新,节省了很大的运维成本!
经济:因为通过一个软件实例被多个组织共享,从而减低了整体资源的消耗,也同时减低应用运行的成本和相应的管理开支。
第二,提高了数据安全性
在云计算环境下,很多应用都放到了云端,导致在应用入口,敏感数据泄露、数据访问无详细记录、应用冒名访问开放接口;
在运维入口,开发人员账号混用、操作无详细记录、高危险误操作无法控制、敏感数据泄露
通过多租户数据资源隔离机制,就可以保证数据的安全性。
三、管理方便:
首先,通过使用了多租户架构能减少物理资源和软件资源,这将简化管理,其次。由于多租户软件主要由有经验的云供应商运营,所以能依赖那些非常经验的管理人员来提升效率。
多租户的几种模式
模式一:
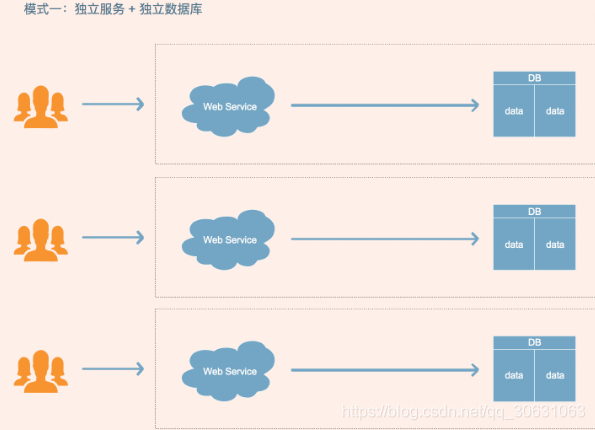
特点:
这个模型中,应用层和数据层都是隔离的。
应用程序的每个实例都是独立实例。
租户拥有自己独立的数据库,每个应用程序实例只需要一个数据库。
对租户的管理独立于系统之外,对于每一个租户,整个应用程序需要重复安装一次。供应商都可以为租户管理软件。每个应用程序实例都配置为连接到其相应的数据库。
优点:为不同的租户提供独立的应用实例和数据库,有助于简化数据模型和业务模型的扩展设计,满足不同租户的独特需求;如果出现故障,恢复系统或数据均比较简单,系统间也不会相互影响。
缺点:数据库层面,每个租户数据库都作为独立数据库进行部署。该模型提供了最大的数据库隔离。但隔离需要为每个数据库分配足够的资源来处理其高峰负载。这里重要的是, 弹性池不能用于部署在不同资源组或不同订阅中的数据库。这种限制使得这种独立的单租户应用程序模型成为从整体数据库成本角度来看最昂贵的解决方案;应用层面,每个租户若存在个性化定制,则需要对项目进行横向扩展,扩展时务必需要保证与主干版本的兼容性问题。运维层面,应用和数据库的安装数量会随租户的数量线性递增,随之带来维护成本和购置成本的增加。
模式二:(本公司的项目就是使用这种模式)
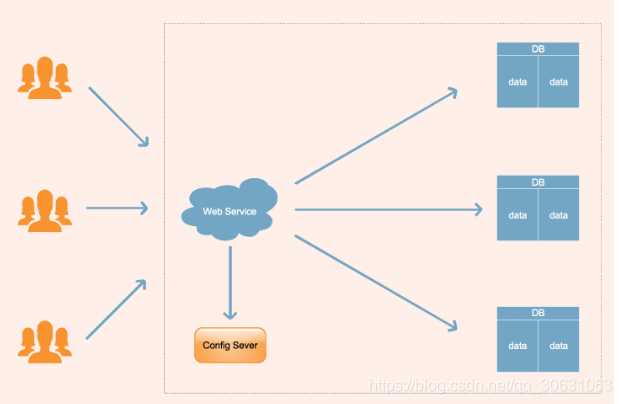
这个模型中,应用层是共享的,数据层都是隔离的。
应用程序仅部署一套,所有租户实例共享。
租户仍拥有自己独立的数据库,应用程序需对接多个租户的数据库。
对租户的管理由配置中心(Config Server)管理,配置中心提供了配置,监视和管理共享所需的功能,供应商使用这些工具为租户管理软件。对于每一个租户,整个应用程序仅需要安装一次,应用程序实际请求结合配置中心请求相应的数据库。
优点:为不同的租户提供独立数据库,有助于简化数据模型扩展设计,满足不同租户的独特需求;如果出现故障,数据恢复均比较简单,也可以自动将单个租户恢复到较早的时间点。因为恢复只需要恢复存储租户的一个单租户数据库。这种恢复对其他租户没有影响,这证实了管理运营处于每个租户的细粒度级别。应用层面的维护成本和购置成本有所减少。
模式三:

共享数据库,独立Schema
即多个或所有租户共享Database,但一个Tenant一个Schema。将每个租户关联到同一个数据库的不同 Schema,租户间数据彼此逻辑不可见,上层应用程序的实现和独立数据库一样简单,但备份恢复稍显复杂;
优点:为安全性要求较高的租户提供了一定程度的逻辑数据隔离,并不是完全隔离;每个数据库可以支持更多的租户数量。
缺点: 如果出现故障,数据恢复比较困难,因为恢复数据库将牵扯到其他租户的数据;如果需要跨租户统计数据,存在一定困难。
模式四:
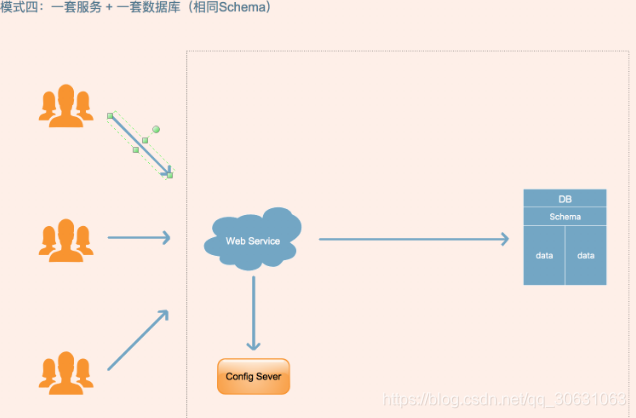
共享数据库,共享数据表
所有的租户都用同一个数据库,共同用相同的表,使用不同的租户id来标识
优点: 维护和购置成本最低,允许每个数据库支持的租户数量最多
缺点: 隔离级别最低,安全性最低,数据备份和数据恢复最困难,需要逐表来备份和还原,以牺牲隔离级别换取降低成本
下面我们讲讲如何实现模式二的多租户
业务场景:
本公司的项目是服务给多个高校随堂练习和考试用的,所以数据量比较大,而且不同的高校之间是互相隔离的,所以我们采用了模式二(共用同一个服务实例,但是每个租户都有自己的数据库,这种方案对于维护和数据恢复来说都很方便,而且隔离级别也很高)
如何实现多租户?
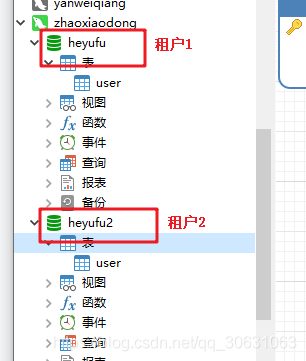
1. 配置两个租户的数据库:
2. 配置mycat:(对于mycat中schemal中如何配置不了解的可以先去查查,否则你可能看不懂)
每一个租户都是一个逻辑库,并且每个逻辑库都有唯一对应的实际数据库
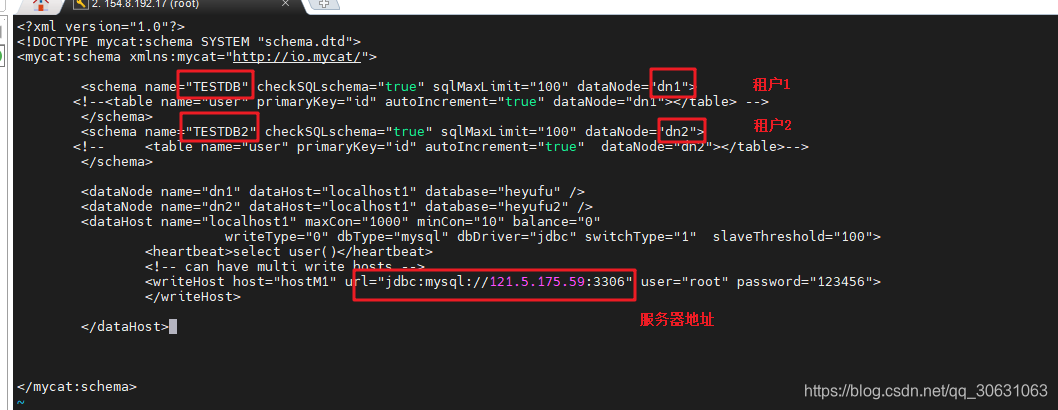
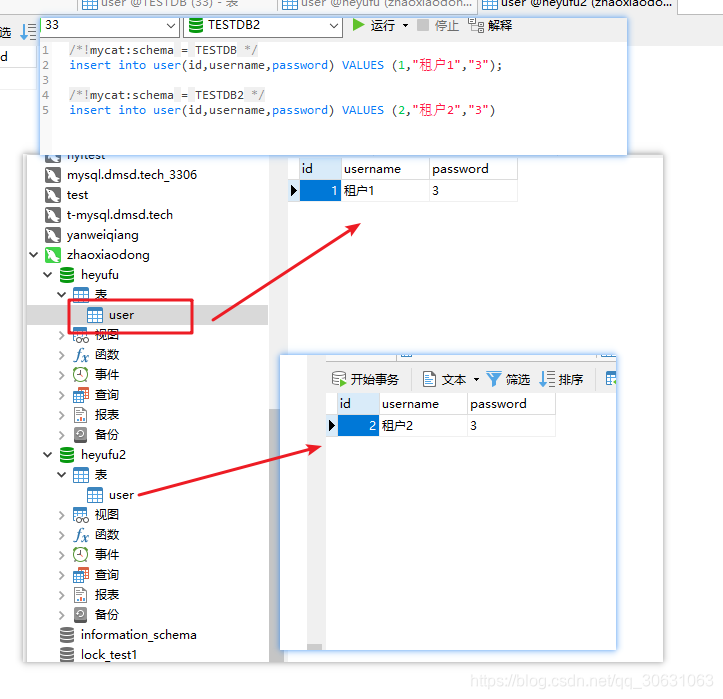
3. 实现:在sql语句前面指定mycat 的逻辑库,就可以实现动态的根据逻辑库名来操作不同租户的数据库
项目中的技术方案:
前端传递租户id后端通过过滤器获取请求参数得到租户id,放入ThreadLocal中(ThreadLocal线程隔离安全性高)利用 mybatis的插件拦截器,拦截Executor 的 query方法 或者 statementHandler的prepare方法 修改sql的头,在sql语句的前面指定mycat的逻辑库名,最后成功实现多租户
实现步骤:
步骤一:(传递租户id)
(方案一)前端根据用户名和密码访问权限系统,权限系统根据用户名来确定当前用户是哪个租户,将当前的租户id返回给前端,前端存入本地cookie中,后面的请求都携带cookie
(方案二)我们可以根据浏览器的域名来判断不同的租户,本公司给不同的租户设定的域名是不同的
步骤二: 拦截浏览器发来的请求,根据域名来判断当前用户的租户id ,并放到ThreadLocal中
public class MyCatFilter implements Filter {
public static ThreadLocal<String> SCHEMA_LOCAL=new ThreadLocal<>();
public static String getSchema(){
String schema=SCHEMA_LOCAL.get();
if(StringUtil.isNotEmpty(schema)){
return schema;
}
return "BASE";
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
try{
HttpServletRequest req=(HttpServletRequest) servletRequest;
//获取服务名
String requestURI=req.getServerName();
//租户1的域名
if(requestURI.indexOf("tfjy2")>-1){
SCHEMA_LOCAL.set("TESTDB2");
//租户2的域名
}else if(requestURI.indexOf("tfjy1")>-1){
//设置租户库id
SCHEMA_LOCAL.set("TESTDB");
}
filterChain.doFilter(servletRequest,servletResponse);
}finally {
SCHEMA_LOCAL.remove();
}
}
}步骤三: 那么我们获取到了租户id,这次是不是只要在sql语句的前面加上逻辑库的名字即可?
我们模仿mybatis的pageHelper的功能来做一个拦截器,拦截sql语句。
如果你了解过mybatis中关于插件的源码你就会知道 我们的分页插件 pageHelper就是做了拦截器,将我们的sql语句后面加上了 limit ,我们这个多租户和分页类似,只需要在sql语句前面加上 /
*!mycat:schema = logic_10001 */ 即可实现
我们写一个拦截器:
//拦截StatementHandler 的prepare方法
@Intercepts(value = {
@Signature(type = StatementHandler.class,
method = "prepare",
args = {Connection.class})})
public class ChangeUserInterceptor implements Interceptor {
// 修改sql,添加前后缀
private static final String preState="/*!mycat:schema=";
private static final String afterState="*/";
@Override
public Object intercept(Invocation invocation) throws Throwable {
//获取代理对象的真实对象
StatementHandler statementHandler=(StatementHandler)invocation.getTarget();
MetaObject metaStatementHandler=SystemMetaObject.forObject(statementHandler);
Object object=null;
//获取sql
String sql=(String)metaStatementHandler.getValue("delegate.boundSql.sql");
//获取租户id
String node=getSchema();
if(node!=null) {
//重写sql,适配mycat
sql = preState + node + afterState + sql;
}
System.out.println("sql is "+sql);
metaStatementHandler.setValue("delegate.boundSql.sql",sql);
//代理对象继续干自己的事情
Object result = invocation.proceed();
System.out.println("Invocation.proceed()");
return result;
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
}
}这个拦截器的功能就是,当mybatis执行statement的prepare方法(在sql预编译的时候会走的方法)的时候就会被拦截,先走拦截器然后才继续执行其他的
步骤四: 在mybatis的配置文件中加入plugin:
<plugins>
<!-- 分页插件-->
<!-- <plugin interceptor="com.github.pagehelper.PageInterceptor">-->
<!--<!– 忽略配置文件中的空格–>-->
<!-- <property name="reasonable" value="true"/>-->
<!-- </plugin>-->
<plugin interceptor="com.cn.mybatistest.interceptor.ChangeUserInterceptor">
</plugin>
</plugins>即可实现!
如果想了解mybatis关于插件的源码如何实现,请敬请期待 下篇博客!