目录
1、glances:监听系统CPU、内存、磁盘I/O等使用情况
1、top命令的使用
查看Linux系统性能命令。top命令可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具,TOP命令是Linux下常用的性能分析工具,
能够实时显示系统中各个进程的资源占用状况
,有点像window系统的任务管理器。
语法格式:
top 【param】
param可以为:
| -b | 以处理模式操作 |
| -c | 显示完整的命令行而不只是显示命令名。 |
| -d | 屏幕刷新间隔时间。 |
| -l | 忽略失效过程。 |
| -s | 保密模式。 |
| -S | 累积模式。 |
| -u【用户名】 | 指定用户名。 |
| -p【进程号】 | 指定进程。 |
| -n【次数】 | 循环显示的次数。 |
| -H | 查看进程下面的子线程。 |
top命名信息详解:
[root@sc-master ~]# top
top - 22:34:45 up 3 days, 8:28, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 122 total, 3 running, 119 sleeping, 0 stopped, 0 zombie
%Cpu(s): 4.3 us, 30.4 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995896 total, 77508 free, 320024 used, 598364 buff/cache
KiB Swap: 2097148 total, 2096884 free, 264 used. 415608 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 R 4.5 0.0 0:17.40 rcu_sched
1 root 20 0 125588 4076 2604 S 0.0 0.4 0:45.18 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 1:14.37 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0.0 0.0 0:04.79 watchdog/0
13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs top命令分为上下两个部分:
- 系统统计信息
- 系统进程信息
1、系统统计信息
top - 22:34:45 up 3 days, 8:28, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 122 total, 3 running, 119 sleeping, 0 stopped, 0 zombie
%Cpu(s): 4.3 us, 30.4 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995896 total, 77508 free, 320024 used, 598364 buff/cache
KiB Swap: 2097148 total, 2096884 free, 264 used. 415608 avail Memrow1:任务队列信息,同 uptime 命令的执行结果。
top - 22:34:45 up 3 days, 8:28, 3 users, load average: 0.00, 0.01, 0.05- 22:34:45(当前系统时间)
- up 3 days,8:28(系统运行时间)
- 3 user (当前登录用户数)
- load average: 0.00, 0.01, 0.05(系统的平均负载数,表示 1分钟、5分钟、15分钟到现在的平均数)
row2:进程统计信息。
Tasks: 122 total, 3 running, 119 sleeping, 0 stopped, 0 zombie- 122 total:系统当前总进程总数
- 3 running:正在运行的进程数
- 119 sleeping :睡眠进程数
- 0 stopped:停止进程数
- 0 zombie:僵尸进程数
row3:CPU统计信息
%Cpu(s): 4.3 us, 30.4 sy, 0.0 ni, 65.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st- 4.3 us:用户空间CPU占用率
- 30.4 sy:内核空间CPU占用率
- 0.0 ni :用户进程空间改变过优先级的进程CPU的占用率
- 65.2 id:空闲CPU占有率。
- 0.0 wa:等待输入输出的CPU时间百分比。
- 0.0%hi (硬件中断请求)
- 0.0%si (软件中断请求)
- 0.0%st (分配给运行在其它虚拟机上的任务的实际 CPU时间)
row 4:内存状态
KiB Mem : 995896 total, 77508 free, 320024 used, 598364 buff/cache- 995896 total (物理内存总量 )
- 77508 used (已使用的内存 )
- 320024 free (空闲内存 )
- 598364 buffers (内核缓存使用)
以k为单位。
row5:swap交换分区信息。
KiB Swap: 2097148 total, 2096884 free, 264 used. 415608 avail Mem- 4063228 total (交换分区总量 )
- 2096884 used (已使用交换分区内存 )
- 2096884 free (空闲交换分区 )
- 415603 cached (缓冲交换区 )
2、系统进程信息
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9 root 20 0 0 0 0 R 4.5 0.0 0:17.40 rcu_sched
1 root 20 0 125588 4076 2604 S 0.0 0.4 0:45.18 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 1:14.37 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0.0 0.0 0:04.79 watchdog/0
13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs - PID :进程id
- USER :进程所有者的用户名
- PR :进程优先级
- NI :nice值。负值表示高优先级,正值表示低优先级
- VIRT :进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES :进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR :共享内存大小,单位kb
- S :进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
- %CPU :上次更新到现在的CPU时间占用百分比
- %MEM :进程使用的物理内存百分比
- TIME+ :进程使用的CPU时间总计,单位1/100秒
- COMMAND :进程名称[命令名/命令行]
1、按“1”键,可打开或关闭显示详细CPU统计信息:

2、按字母“B”键,可打开或关闭当前进程的显示效果。
top -H -p pid
,查看进程pid下面的子线程。
2、free命令使用:内存
free 查看内存的使用情况(接m表示以兆的形式显示),这个命令能够显示系统中物理上的空闲和已用
内存
,还有交换内存,同时,也能显示被内核使用的缓冲和缓存。
语法格式:
free 【param】
param可以表示为:
| -b | 以BYte为单位显示内存使用情况。 |
| -k | 以KB为单位显示内存使用情况。 |
| -m | 以MB为单位显示内存使用情况。 |
| -o | 不显示缓冲区调节列。 |
| -s【间隔秒数】 | 持续观察内存使用情况。 |
| -t | 显示内存总和列。 |
| -V | 显示版本信息。 |
free -m
命令的使用:
[root@sc-master ~]# free -m
total used free shared buff/cache available
Mem: 972 308 79 25 583 409
Swap: 2047 0 2047
Mem:表示物理内存统计。
Swap:表示硬盘上交换分区的使用情况。
total:表示物理内存总数(total=used+free)
used:表示系统分配给缓存使用的数量(这里的缓存包括buffer和cache)
free:表示未分配的物理内存总数。
shared:表示共享内存。
buffers:系统分配但未被使用的buffers数量。
cached:系统分配但未被使用的cache数量。
-/+ buffers/cache:表示物理内存的缓存统计
- (-buffers/cache) 内存数: (指的第一部分Mem行中的used – buffers – cached)
- (+buffers/cache) 内存数: (指的第一部分Mem行中的free + buffers + cached)
(-buffers/cache)表示真正使用的内存数, (+buffers/cache) 表示真正未使用的内存数
3、df命令的使用:磁盘
df命令用于显示磁盘分区上的可使用的磁盘空间。默认显示单位为KB。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
语法结构:
df(选项)(参数)
选项为:
|
-a |
-all,包含全部的文件系统。 |
| -h | -human,以人类可读的方式来显示信息。 |
| -H/si | 与-h参数相同,但在计算时是以1000 Bytes为换算单位而非1024 Bytes; |
| -i | -inode,显示inode的信息; |
| -k | -kilobytes,指定区块大小为1024字节; |
| -l | -local,仅显示本地端的文件系统; |
| -m | –megabytes,指定区块大小为1048576字节; |
| -no | 在取得磁盘使用信息前,不要执行sync指令,此为预设值; |
| -P | -portability,使用POSIX的输出格式; |
| -sync | 在取得磁盘使用信息前,先执行sync指令; |
| -t<文件系统类型> | 仅显示指定文件系统类型的磁盘信息; |
| -T | 显示文件系统的类型 |
| -x<文件系统类型> | 不要显示指定文件系统类型的磁盘信息; |
| –help | 显示帮助。 |
| -version | 显示版本信息。 |
常用指令为:
- df -a 查看全部的文件系统
- df -h查看磁盘使用情况
- df -i 查看inode使用情况
4、ps命令的使用
ps 命令用于查看进程统计信息。
常用参数:
| -a | 显示当前终端下的所有进程信息,包括其他用户的进程。 |
| -u | 使用以用户为主的格式输出进程信息。 |
| -x | 显示当前用户在所有终端下的进程。 |
| -e | 显示系统内的所有进程信息。 |
| -l | 使用长格式显示进程信息。 |
| -f | 使用完整的(full)格式显示进程信息。 |
| -T | 查看进程下面的子线程。 |
在使用中可以加上grep命令一起使用,也可以单独使用。
# ps命令单独使用:
ps -ef 、ps -aux
[root@sc-master ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 8月27 ? 00:00:45 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0 0 8月27 ? 00:00:00 [kthreadd]
root 3 2 0 8月27 ? 00:01:16 [ksoftirqd/0]
[root@sc-master ~]# ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.4 125588 4076 ? Ss 8月27 0:45 /usr/lib/systemd/systemd --switched-root --system --dese
root 2 0.0 0.0 0 0 ? S 8月27 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 8月27 1:17 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 8月27 0:00 [kworker/0:0H]
root 7 0.0 0.0 0 0 ? S 8月27 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S 8月27 0:00 [rcu_bh]
# 结合管道操作和grep命令进行过滤,用于查询某一个进程的信息。
ps -ef|grep nginx ps -aux|grep nginx
[root@sc-master ~]# ps -ef|grep nginx
root 6808 1 0 8月27 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 6809 6808 0 8月27 ? 00:00:00 nginx: worker process
root 76672 76574 0 23:32 pts/5 00:00:00 grep --color=auto nginx
[root@sc-master ~]# ps -aux|grep nginx
root 6808 0.0 0.1 49056 1156 ? Ss 8月27 0:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/ngin.conf
nginx 6809 0.0 0.1 49524 1880 ? S 8月27 0:00 nginx: worker process
root 77085 0.0 0.0 112824 984 pts/7 R+ 23:40 0:00 grep --color=auto nginx
5、crontab 命令
crontab
命令,用于定时程序的命令。
- -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe)
- -r : 删除目前的时程表
- -l : 列出目前的时程表
6、查看端口的命令
1、
netstat:查看监听的端口
netstat:是查看本机开放了哪些端口;本机开放的所有的端口。
详解:
Linux常用命令
需要安装:
yum install net-tools -y
2、lsof:查看端口被占用情况
需要先安装:
yum install lsof -y
① 查看哪个端口被哪个进程占用了。
lsof -i:22 查看22端口被哪个进程占用了
② 查看某个进程打开了哪些文件、加载库,依赖关系
lsof -p 64138
③ 或者是哪个文件夹被哪个进程打开
lsof /root/
3、ss:显示更多更详细的有关 TCP 和连接状态的信息
ss 是
Socket
Statistics 的缩写。ss 命令可以用来获取 socket 统计信息,它显示的内容和 netstat 类似。但 ss 的优势在于它能够显示更多更详细的有关 TCP 和连接状态的信息,而且比 netstat 更快。
常用选项:
| ss | 输出所有建立的连接(不包含监听的端口),包括 tcp, udp, and unix |
| ss -tnl | 查看主机监听的tcp端口信息 |
| ss -tna | 查看监听的tcp连接 |
4、nc和nmap:扫描别人机器上开放了哪些端口。
nc:扫描别人机器上开放了哪些端口。
需要先安装:yum install nc -y
nc:ncat – Concatenate and redirect sockets —-cat: Concatenate 连接递归到socket。
可接选项:
| -z | Only scan for listening daemons, without sending any data to them. 查看端口号是否开发 |
| [-w timeout] | 超时,等待时间 |
例如:-z :查看192.168.0.1的80端口是否开放。
[root@slave-mysql ~]# nc -z 192.168.0.1 80
Connection to 192.168.0.1 80 port [tcp/http] succeeded!
[root@slave-mysql ~]# echo $?
0 为0表示上层命令执行成功
[root@slave-mysql ~]# nc -z 192.168.0.1 8080
^C
[root@slave-mysql ~]# man nc
[root@slave-mysql ~]# nc -w 1 -z 192.168.0.1 8080
[root@slave-mysql ~]# echo $?
1
nmap:探测一个机器或者整个局域网里机器开放了哪些端口。
网络探测工具和安全/端口扫描器。速度比较慢。
例如:扫描本台机器上常见的端口号:nmap 192.168.2.137
[root@nginx-kafka01 ~]# nmap 192.168.2.137
Starting Nmap 6.40 ( http://nmap.org ) at 2022-08-04 10:31 CST
Nmap scan report for nginx-kafka03 (192.168.2.137)
Host is up (0.00014s latency).
Not shown: 997 closed ports
PORT STATE SERVICE
22/tcp open ssh
111/tcp open rpcbind
3306/tcp open mysql
MAC Address: 00:0C:29:3F:07:8B (VMware)
Nmap done: 1 IP address (1 host up) scanned in 1.85 seconds
7、
查看系统资源使用情况
1、glances:监听系统CPU、内存、磁盘I/O等使用情况
基于Python开发,使用psutil库来从系统抓取信息的基于curses开发的跨平台的命令行系统监视工具。使用glances,我们可以监视CPU、平均负载、内存、网络流量,磁盘I/O,其他处理器和文件、系统的利用情况。
安装:
yum install epel-release -y
yum install glances -y
按q退出
2、nethogs:查看某个进程消耗了多少流量(动态显示)
查看某个进程消耗了多少流量,知道哪些进程和外面进行通信。
yum install epel-release -y
yum install nethogs -y
按q退出
[root@nginx-kafka01 shell]# nethogs
Ethernet link detected
Ethernet link detected
Waiting for first packet to arrive (see sourceforge.net bug 1019381)
8、查看网络流量
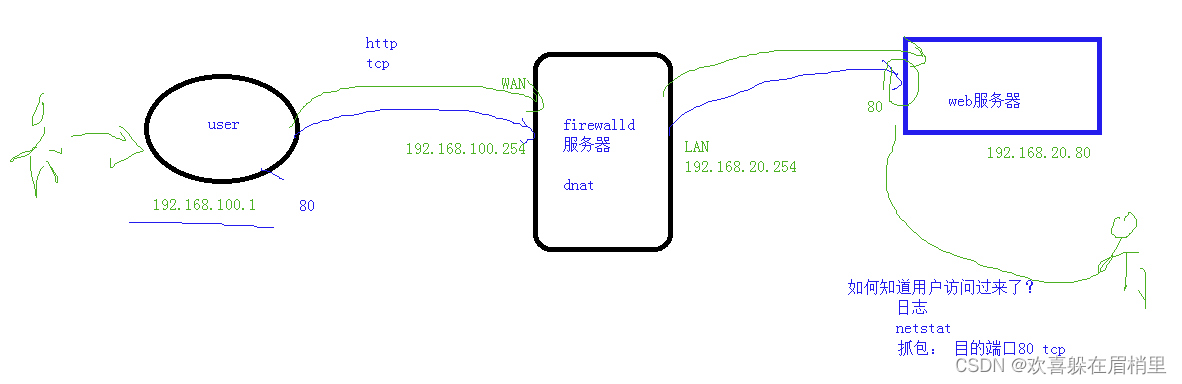
1、tcpdump:抓包查看网络流量
ifconfig :
字符界面的抓包工具—Linux中
需要安装:
yum install tcpdump -y
2、wireshark:抓包查看网络流量
Linux和windows里的图形化的抓包工具。需要先安装:
yum install tcpdump -y
3、iftop:查看网络上的流量情况
用于查看网络上的流量情况(查看你的机器和别人机器之间的流量。),包括实时速率、总流量、平均流量等,是一款实时流量监控工具。需要先安装。
iftop
命令
不记录历史数据,无报表,且只能显示从程序启动到现在的总流量。它的运行需要root权限。
yum install iftop -y