
本文由同济大学和北京大学合作发表于CVPR2018,聚焦于loss层面,为遮挡情况下的行人检测问题提供了一种行之有效的解决方案。
论文:
https://arxiv.org/abs/1711.07752
一、问题提出
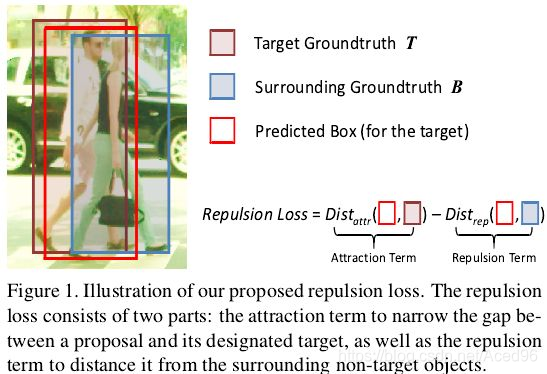
1.行人遮挡会造成什么问题
当我们在做行人检测时,人与人之间会存在互相遮挡。遮挡会造成2个问题:
1.设红色框为目标框T(man)的预测框P,旁边也有个真实框B(woman),我们的P可能会被往B去移动(shift)。
2.检测器对NMS的阈值的选取更为敏感。如果NMS阈值选取过小,周围的目标框会被
过滤
掉;如果NMS阈值选取过大,会带更多的
虚检
。
2.非极大抑制选取更敏感
第二点的影响是不是不太直观?没关系,我们先详细回顾一下非极大抑制NMS的实现过程:
在检测器中,一张图片可能会有n个检测目标,每个检测目标都会有很多
检测框
(proposals/anchors/bbox)。
对于每个检测目标来讲,它的附近都会有一簇IoU很高的检测框(相较于其他的检测框来说),所以针对
同一个检测目标
,有必要只留下置信度(score)最高的那个检测框作为该物体的检测框,其他的都应该过滤掉。
实现步骤:
1、假定有6个带置信率的region proposals,并预设一个IOU的阈值如0.7。
2、按置信率大小对6个框排序: 0.95, 0.9, 0.9, 0.8, 0.7, 0.7。
3、设定置信率为0.95的region proposals为一个预测框;
4、在剩下5个region proposals中,去掉与0.95物体框IOU大于0.7的。
5、重复2~4的步骤,直到没有region proposals为止。
6、每次获取到的最大置信率的region proposals就是我们筛选出来的目标。
那么问题来了,对于有遮挡的行人数据集,这里过滤掉的检测框有没有对隔壁检测目标IoU最高却被我们这个检测目标的检测框给抑制掉的呢?看图。
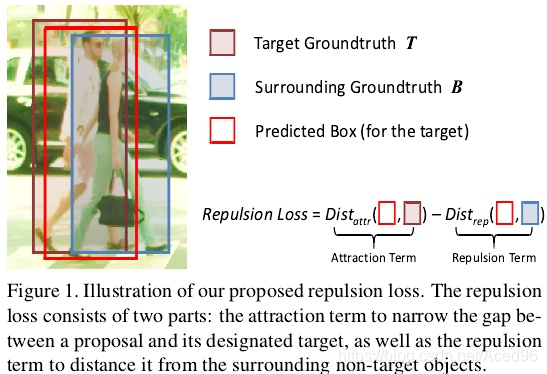
NMS阈值选取过小
:针对目标T(man),检测框P与T的IoU最大,P会视为T的预测框。如果NMS选取过小,旁边目标B的预测框(woman)假设为K,那么K会被选作T的检测框,然后被P抑制掉。
NMS阈值选取过大
:与上面是同样的道理,会多出许多检测框,带来更多的假正例。
二、Repulsion loss
既然已经清楚影响是怎样造成的,来看看解决方案。Repulsion loss的作用在于,
要求预测框P靠近(吸引)自己的真实目标T的同时,还要求P远离(排斥)T旁边的其他真实框(例如B)
。
1.Replusion loss:

可以看到该损失函数中包含3个模块,下面来分别作解释。
2.
L
A
t
t
r
L_{Attr}
L
A
t
t
r
该模块的作用是使得预测框和它的目标框尽可能接近。
L
A
t
t
r
L_{Attr}
L
A
t
t
r
采用的是通用目标检测中的回归loss,可以采用欧式距离,SmoothL1距离以及IoU距离。但为了和其他算法有可比性,这里采用的是SmoothL1距离。

P
∈
P
+
P∈P+
P
∈
P
+
(所有的正样本):正样本就是根据设定的IoU阈值来划分出来的检测框P的集合。
G
A
t
t
r
P
G^P_{Attr}
G
A
t
t
r
P
: 为每一个检测框P匹配一个有最大IoU值的真实目标框(Ground truth)
B
P
B^P
B
P
: 从检测框P做回归偏移(shift)后得到的预测框。
清楚这些基础概念后,这个模块的函数就好理解了,smoothL1的公式如下:
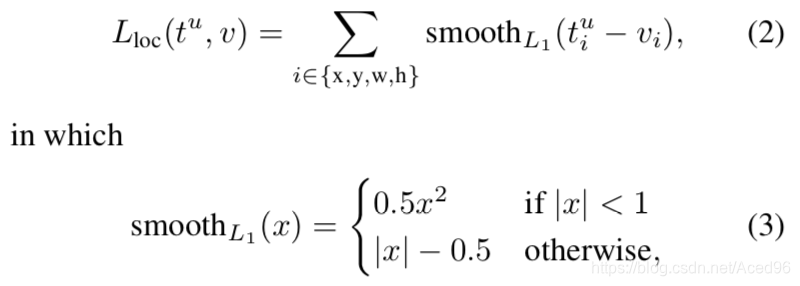
从公式可以很直观的看出,
B
P
B^P
B
P
和
G
A
t
t
r
P
G^P_{Attr}
G
A
t
t
r
P
的左上角坐标以及宽高
(
x
,
y
,
w
,
h
)
(x,y,w,h)
(
x
,
y
,
w
,
h
)
分别进行smoothL1计算,然后累加和。
优化的目标就是让两者之间距离缩短,那就达到了预测框和它的目标框尽可能接近的目的。
3.
L
R
e
p
G
T
L_{RepGT}
L
R
e
p
G
T
L
R
e
p
G
T
L_{RepGT}
L
R
e
p
G
T
是使得预测框P和周围的目标框G尽可能远离 。
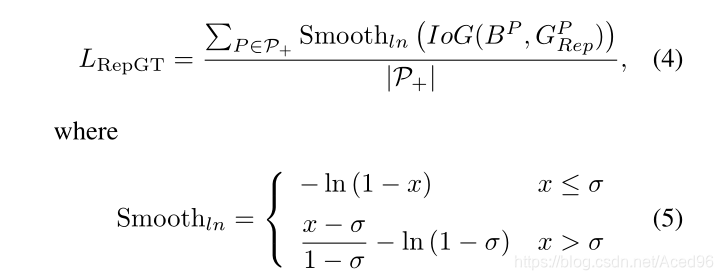
这里的周围的目标框是除了已经匹配上的目标框以外的IoU最大的目标框,用
G
R
e
p
P
G^P_{Rep}
G
R
e
p
P
表示。

即
G
R
e
p
P
G^P_{Rep}
G
R
e
p
P
是除了与预测框P匹配了的Ground_truth-A以外,其他剩下的Ground_truth中与预测框P的IoU最大的Ground_truth-B。
Q1:
L
R
e
p
G
T
L_{RepGT}
L
R
e
p
G
T
采用的smoothLn和IoG,那么为什么不适用IoU呢?
A :
如果选用IoU,那么只要预测框变得足够大(即增大并集)就能使得
L
R
e
p
G
T
L_{RepGT}
L
R
e
p
G
T
减小。IoG不同,GT是固定的,只能优化分子部分(即增大交集)。
Q2.为什么采用smoothLn?
A :
Ln既保留了L1的鲁棒性又吸收L2的快速收敛性。
4.
L
R
e
p
B
o
x
L_{RepBox}
L
R
e
p
B
o
x
L
R
e
p
B
o
x
L_{RepBox}
L
R
e
p
B
o
x
:使得预测框Pi和周围的预测框Pj尽可能远离,
P
i
P_i
P
i
和
P
j
P_j
P
j
分别配上不同的预测框,他们之间的距离采用的是IoU。定义如下:

从式(4)中可以发现当预测框Pi和周围的其他预测框Pj的IoU越大,则产生的loss也会越大,因此可以有效防止两个预测框因为靠的太近而被NMS过滤掉,进而减少漏检。
参考文献:
[1].
CVPR18|Repulsion loss:遮挡下的行人检测
[2].
Repulsion Loss: Detecting Pedestrians in a Crowd
[3].
NMS算法原理及代码验证