前言
本文记载个人在RM视觉组中学习到的传统算法和opencv用法及代码实例讲解,用于教会别人,同时教会自己。
接下来的文章中,我会将图像识别部分单独抽离出来,简化图像的输入与输出,一步一步的实现如何识别出装甲板。为了理解这篇文章,你需要有一定的图片和opencv基础。
讲解的代码部分参考了东南大学2018的开源代码
SEU开源代码
,对其进行了些微的封装处理和改动。文中会引用其他文章的内容,毕竟学习本身就是集大成的过程。我会尽量标明出处,如果有侵权请联系我修改或删除。
一、装甲板的分析
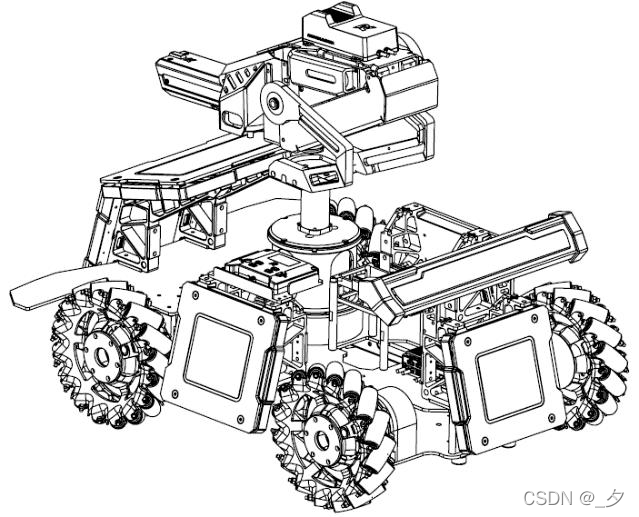
写任何程序的第一步,就是对自己的目标需求进行分析。下面这幅图是装上装甲板后的步兵轴测图
下面这幅图则是我们比赛时实际会看到的状况(这张图片是网上偷的,有经过调色和后期处理,但不影响我们讲解):

在图中可以看到:
- 装甲板近似竖直固定在小车的四周
- 同一装甲板两灯条平行、灯条长宽确定、两灯条间的间距确定
- 在小车转过45度后会有两个装甲板出现在摄像头画面中,但是相互倾斜一定角度
- 两个装甲板的倾斜角度相差不大,容易将中间两个灯条误识别成大装甲板
据此可以初步构思出识别思路。
- 预处理,尽量忽略图片中我们不需要的信息
- 找出图片中所有的灯条
- 根据长宽比、面积大小和凸度等约束条件来筛选灯条
- 对找出的灯条进行匹配找到合适的配对
- 配对灯条作为候选装甲板
- 寻找最适合打击的装甲板进行目标确认,返回给姿态解算模块
以上几步就是识别装甲板的步骤。
二、预处理
按我的话来说,所谓预处理,就是在图像还未真正进行识别处理前,对图像进行简易、全局的处理。这一块通常在产生图片时进行操作,不属于我们视觉识别的重点(但是预处理真的很重要)。这里仅简单介绍我们使用的两个预处理过程。
降低曝光度
通过相机,我们能够源源不断地获取到当前的画面,也就是一帧帧的图像。自瞄算法处理的对象,就是这每一张图像。
在实战中,由于环境光的干扰,如果直接对图片进行算法处理,会错误的提取多余的特征,导致算法的准确度和速度大大降低。由于灯条自己会发光,可以有效和将灯条与环境光很好的区分开来。为了便于分离灯条与其他光线,一般将曝光设置得很低,如下图为相机获取到的画面:(
RoboMaster视觉教程(1)摄像头
)
降低曝光前

降低曝光后

显而易见,通过降低曝光度的操作,可以在很大程度上屏蔽背景光的干扰
ROI区域
先贴一下定义:
在图像处理领域,感兴趣区域(ROI) 是从图像中选择的一个图像区域,这个区域是你的图像分析所关注的重点。圈定该区域以便进行进一步处理。使用ROI圈定你想读的目标,可以减少处理时间,增加精度。
因为机器人不会瞬移,当我们某一帧识别到一个装甲板的位置后,下一帧装甲板的位置几乎一定在这个位置的附近。因此我们可以以当前识别到的装甲板为中心,扩大装甲板的范围若干倍作为roi区域,在下一帧图像识别时就可以仅选取这片区域进行识别,从而缩小图片规模,减少处理时间。
如图所示,黄框的是装甲板的范围,白框的是又装甲板范围扩展的ROI区域,下一帧可以仅选取白框范围来进行图像处理。

三、颜色提取
从这里开始,我们以这张已经经过低曝光处理的图片为例子(素材来自官方视觉素材)。
官方素材

提取目标颜色
当我们获得了一个低曝光的ROI区域之后,我们接下来要做的就是将我们想要的颜色提取出来,进行下一步的识别。
幸运的是,经过低曝光处理后,装甲板的颜色特征非常明显,装甲板的两侧分别有一个蓝色或者红色的光条,在昏暗的图片中非常显眼。而这就是我们想要提取的颜色。
对于图像中红色的物体来说,其rgb分量中r的值最大,g和b在理想情况下应该是0,同理蓝色物体的b分量应该最大。
如果识别红色物体可以直接用r通道-b通道。由于在低曝光下只有灯条是有颜色的,两通道相减后,其他区域的部分会因为r和b的值差不多而被减去,而蓝色灯条部分由于r通道比b通道的值小,相减后就归0了,也就是剩下的灰度图只留下了红色灯条。
//颜色分离函数,返回提取目标颜色后的灰度图
Mat separateColors(){
vector<Mat> channels;
// 把一个3通道图像转换成3个单通道图像
split(_roiImg,channels);
Mat grayImg;
//剔除我们不想要的颜色
//对于图像中红色的物体来说,其rgb分量中r的值最大,g和b在理想情况下应该是0,同理蓝色物体的b分量应该最大,将不想要的颜色减去,剩下的就是我们想要的颜色
if(_enemy_color==RED){
grayImg=channels.at(2)-channels.at(0);//R-B
}
else{
grayImg=channels.at(0)-channels.at(2);//B-R
}
return grayImg;
}
这里我们使用了split()函数,该函数可以将一个多通道的Mat对象转化为一个Mat数组。而且Mat类重载了减号,可以将两个mat矩阵中的每个元素依次相减。最后我们可以得到通道相减后的灰度图。

可以看到,和原图相比,进一步的去除了我们不需要的信息。由于我们选的这种图片的灯条中心的光线在相机中接近于白光(实际上不会这么白),因此部分灯条中心也被减成了黑色,但是问题不大,灯条的边缘信息依然是被保留下来的。
PS:通道相减的做法一个缺点就是当拍摄到的灯条接近白光时,会出现如上图所示的白色的环,增大了识别的难度。关于这部分,还有一个做法就是简单的将ROI区域转化为灰度图,然后直接阈值化,优点是可以得到完整的灯条形状,缺点是这样会把其他颜色的灯光全部识别进来,后面对灯条进行筛选时要回到原图去查看对应位置的颜色,然后将不是目标颜色的灯条剔除出去,增大了运算的时间。至于用哪种算法,见仁见智了。
阈值化与膨胀
经过颜色提取,虽然已经去除了很多多余信息,但是图中还是有很多灰蒙蒙的亮点。如果低曝光程度不够,甚至会出现很多亮斑,会在之后干扰我们对轮廓的提取,因此我们需要进行一些形态学的操作,将这些噪声给去除掉。
我们这里的做法,就是使用threshold函数将图片二值化,并使用膨胀操作尽量将断开的轮廓合并在一起。
int brightness_threshold = 120;//设置阈值,根据相机拍摄实际情况调整
Mat binBrightImg;
//阈值化
threshold(_grayImg, binBrightImg, brightness_threshold, 255, cv::THRESH_BINARY);
//设置膨胀卷积核
Mat element = cv::getStructuringElement(cv::MORPH_ELLIPSE, cv::Size(3, 3));
//膨胀
dilate(binBrightImg, binBrightImg, element);
这是我们二值化后的结果

灯条的轮廓有些断开,因此需要进行一次膨胀操作,使用dilate函数可以让图片中白色的区域尽可能的扩大。这是我们膨胀后的结果
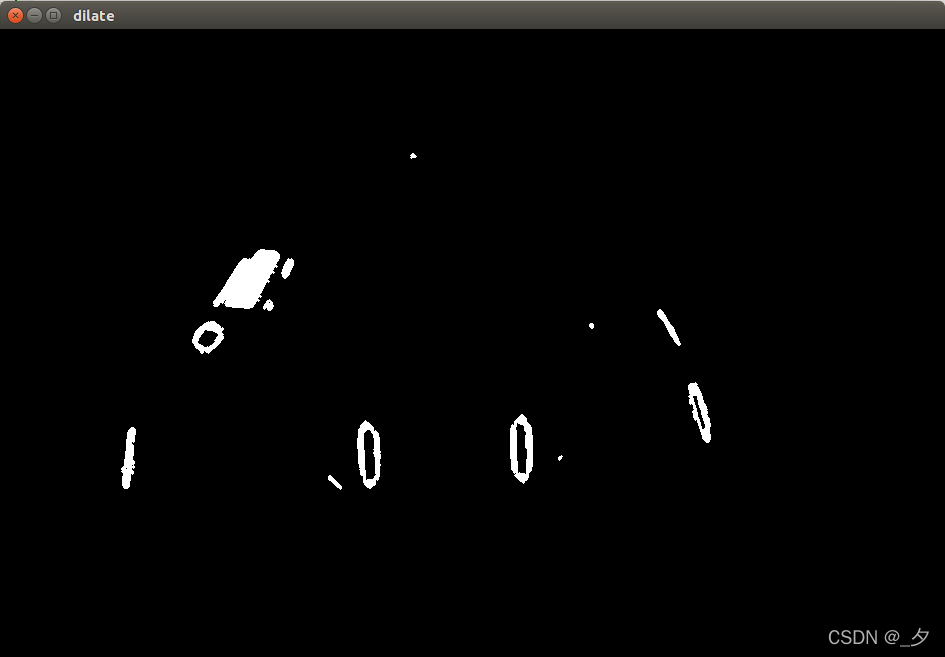
可以看到,灯条的轮廓较好的连在了一起,这样就方便我们进一步的提取轮廓
四、灯条轮廓提取
前面的步骤可以说都是为了找灯条轮廓而做的预处理。现在,使用
findContours
函数检测我们之前的成果。这是我们算法最关键的步骤之一,同时也是最费时的步骤。如果之前的预处理做的好,可以极大地减少找轮廓中花费的时间。
findContours函数详解
//找轮廓
vector<vector<Point> > lightContours;
findContours(binBrightImg.clone(), lightContours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_SIMPLE);
识别模式设置为CV_RETR_EXTERNAL,意思是只寻找最外层的轮廓,理由很简单,根据刚才识别的效果可以看到,如果灯条中心偏白的话,就会形成一个环状的轮廓,影响我们的识别。
最后将识别到的轮廓存储在一个点集的数组里。
以下是对二分图使用findContours函数的结果,为了方便观察,将轮廓绘制在了roi图中。可以看到,二分图中白色的区域全部被识别了出来,并在lightContours中以点集的形式存储起来。
画轮廓的代码:
_debugImg = _roiImg.clone();
for(size_t i = 0; i < lightContours.size(); i++){
drawContours(_debugImg,lightContours, i, Scalar(0,0,255), 1, 8);
}
imshow("contours", _debugImg);

图中红色的歪歪扭扭的线就是轮廓。
五、灯柱筛选
上面使用findCountour函数找到了很多的轮廓,但并不是每个轮廓都对应着一个灯条。可以看到,有的轮廓只有一个小圈,有的轮廓呈现长条形,有的轮廓偏向圆形或者正方形或者一些不规则形状。
现在要做的,就是把那些最不可能是灯柱的轮廓全部剔除出去,只留下可能是灯柱的轮廓,并对有可能是灯柱的轮廓做拟合椭圆的外接矩形处理,使其可以量化分析,便于之后的灯柱匹配计算。
因此需要设置一些约束条件,包括轮廓的面积、宽高比、凸度(这里定义为
轮廓面积/外包椭圆面积
)等。面积太小的不要,宽高比不是那种细长的不要,凸度太小的不要,这样就能缩小我们的搜索范围。这里对我们的约束条件定义如下,用一个ArmorParam类存储这些参数。
注:参数应该根据实际情况进行调整,这里展示的参数仅供参考
//Class ArmorParam
// 过滤灯条
light_min_area = 100;//灯条最小面积
light_max_angle = 45.0;//灯条最大的倾斜角
light_min_size = 5.0;
light_contour_min_solidity = 0.5;//灯条最小凸度
light_max_ratio = 0.4;//灯条最大长宽比
定义LightDescriptor类来描述灯条对象,其实就是把RotatedRect的属性抄了过来:
class LightDescriptor
{
public:
LightDescriptor() {};
LightDescriptor(const cv::RotatedRect& light)
{
width = light.size.width;
length = light.size.height;
center = light.center;
angle = light.angle;
area = light.size.area();
}
const LightDescriptor& operator =(const LightDescriptor& ld)
{
this->width = ld.width;
this->length = ld.length;
this->center = ld.center;
this->angle = ld.angle;
this->area = ld.area;
return *this;
}
//返回旋转矩阵
cv::RotatedRect rec() const
{
return cv::RotatedRect(center, cv::Size2f(width, length), angle);
}
public:
float width;
float length;
cv::Point2f center;
float angle;
float area;
};
万事俱备,最后就是筛选灯条,将满足条件的“灯条”储存起来。
这里用一个函数封装起来。传入轮廓数组,返回灯条数组。
PS:虽然讲解的代码来自东南大学的开源代码,但是不得不吐槽他们的代码书写习惯并不是很好,喜欢一个函数里把所有的过程都塞进去。比较好的写法是一个函数只做一件事,并且代码长度最好不超过20行
//筛选符合条件的轮廓
//输入存储轮廓的矩阵,返回存储灯条信息的矩阵
void filterContours(vector<vector<Point> >& lightContours, vector<LightDescriptor>& lightInfos){
for(const auto& contour : lightContours){
//得到面积
float lightContourArea = contourArea(contour);
//面积太小的不要
if(lightContourArea < _param.light_min_area) continue;
//椭圆拟合区域得到外接矩形
RotatedRect lightRec = fitEllipse(contour);
//矫正灯条的角度,将其约束为-45~45°
adjustRec(lightRec);
//宽高比、凸度筛选灯条 注:凸度=轮廓面积/外接矩形面积
if(lightRec.size.width / lightRec.size.height >_param.light_max_ratio ||
lightContourArea / lightRec.size.area() <_param.light_contour_min_solidity)
continue;
//对灯条范围适当扩大
lightRec.size.width *= _param.light_color_detect_extend_ratio;
lightRec.size.height *= _param.light_color_detect_extend_ratio;
//直接将灯条保存
lightInfos.push_back(LightDescriptor(lightRec));
}
}
这边讲一个小细节,代码里有一步拟合椭圆的操作,将轮廓以最小二乘的算法拟合成一个椭圆,最后返回一个椭圆的外接旋转矩阵,长边为
height
,短边为
width
,其旋转角
angle
为x轴顺时针旋转至与width边重合时的角度,范围为0~~180°。为了方便后续角差的计算和统一旋转矩形四个顶点的方位,这里使用自己写的
adjustRec
函数将旋转角约束为-45~45°。
最后调用即可。
//筛选灯条
vector<LightDescriptor> lightInfos;
filterContours(lightContours, lightInfos);
看一下筛选结果:

看着也许还行?候选项被我们筛选到了只剩6个,这下离我们的目标越来越近了。
六、灯柱匹配
找到了所有符合条件的灯柱后,接下来要做的就是使用这些灯组“组装”成一个又一个的装甲板。很明显,上面匹配到的灯柱有很多个,但不是随便两个灯柱都能组成一个装甲板的,因此我们需要对这些灯柱两两进行匹配,寻找合适的灯柱队,组成一个装甲板。
观察图片,注意到能够组成装甲板的灯柱对具有一些明显的特性:
- 两个灯柱近似平行
- 两个灯柱的中心点y轴相近
- 两个灯柱的长度和宽度相近
- 两个灯柱的长宽比接近
- 灯柱的长度和两个灯柱的间距成一定比例
除了这些很容易发现的特性,还有一些其他值得推敲的约束条件,这里没有进行详细说明,大家可以自行查看代码。
代码具体实现如下,先用STL的sort函数以灯条中心的x坐标进行排序,这样才方便我们从左到右对灯条进行匹配识别。之后计算一系列的约束条件计算和筛选,最后将符合条件的灯条对组合成一个ArmorDescriptor对象,保存在armors数组中返回。关于
ArmorDescriptor类可以去翻看SEU的源码,这里就不贴出来了。
//匹配灯条,筛选出装甲板
vector<ArmorDescriptor> matchArmor(vector<LightDescriptor>& lightInfos){
vector<ArmorDescriptor> armors;
//按灯条中心x从小到大排序
sort(lightInfos.begin(), lightInfos.end(), [](const LightDescriptor& ld1, const LightDescriptor& ld2){
//Lambda函数,作为sort的cmp函数
return ld1.center.x < ld2.center.x;
});
for(size_t i = 0; i < lightInfos.size(); i++){
//遍历所有灯条进行匹配
for(size_t j = i + 1; (j < lightInfos.size()); j++){
const LightDescriptor& leftLight = lightInfos[i];
const LightDescriptor& rightLight = lightInfos[j];
//角差
float angleDiff_ = abs(leftLight.angle - rightLight.angle);
//长度差比率
float LenDiff_ratio = abs(leftLight.length - rightLight.length) / max(leftLight.length, rightLight.length);
//筛选
if(angleDiff_ > _param.light_max_angle_diff_ ||
LenDiff_ratio > _param.light_max_height_diff_ratio_){
continue;
}
//左右灯条相距距离
float dis = distance(leftLight.center, rightLight.center);
//左右灯条长度的平均值
float meanLen = (leftLight.length + rightLight.length) / 2;
//左右灯条中心点y的差值
float yDiff = abs(leftLight.center.y - rightLight.center.y);
//y差比率
float yDiff_ratio = yDiff / meanLen;
//左右灯条中心点x的差值
float xDiff = abs(leftLight.center.x - rightLight.center.x);
//x差比率
float xDiff_ratio = xDiff / meanLen;
//相距距离与灯条长度比值
float ratio = dis / meanLen;
//筛选
if(yDiff_ratio > _param.light_max_y_diff_ratio_ ||
xDiff_ratio < _param.light_min_x_diff_ratio_ ||
ratio > _param.armor_max_aspect_ratio_ ||
ratio < _param.armor_min_aspect_ratio_){
continue;
}
//按比值来确定大小装甲
int armorType = ratio > _param.armor_big_armor_ratio ? BIG_ARMOR : SMALL_ARMOR;
// 计算旋转得分
float ratiOff = (armorType == BIG_ARMOR) ? max(_param.armor_big_armor_ratio - ratio, float(0)) : max(_param.armor_small_armor_ratio - ratio, float(0));
float yOff = yDiff / meanLen;
float rotationScore = -(ratiOff * ratiOff + yOff * yOff);
//得到匹配的装甲板
ArmorDescriptor armor(leftLight, rightLight, armorType, _grayImg, rotationScore, _param);
armors.emplace_back(armor);
break;
}
}
return armors;
}
调用代码如下:
//匹配灯条对
_armors = matchArmor(lightInfos);
if(_armors.empty()){
return -1;
}
//绘制装甲板区域
for(size_t i = 0; i < _armors.size(); i++){
vector<Point2i> points;
for(int j = 0; j < 4; j++){
points.push_back(Point(static_cast<int>(_armors[i].vertex[j].x), static_cast<int>(_armors[i].vertex[j].y)));
}
polylines(_debugImg, points, true, Scalar(0, 255, 0), 1, 8, 0);//绘制两个不填充的多边形
}
imshow("aromors", _debugImg);
结果如下

可以看到成功匹配到了中间的两个灯条。将灯条的长度*2,就是装甲板的高度了,同时灯条内侧的间距就是装甲板图案的长度,在创建armor对象的时候将装甲板图案传进去,进行下一步的识别。
其他
在标定出装甲板的位置之后,识别装甲板最基本的功能就已经实现了。根据自己的需求,可以增加识别装甲板贴纸的算法,例如SVM或者模板匹配等,这里就不展开说明了,因为演示的图片也没有图案啊(
总结
本篇文章介绍了使用传统算法检测装甲板的一般思路,完整代码详见
完整代码