题目
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8
-10 <= nums[i] <= 10
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/permutations-ii
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
想法
这题和46题及其相似,唯一不同的是,可以含有重复元素,所以我先把代码写下来,和46题代码大致不变,唯一有区别的就再去重问题上,怎么样去重是这类问题需要关注的地方,这次我没想到怎么去重,所以用了hashset,hashset虽然能去重,但是啊,这个效率低的很。
所以先把代码写上吧:
class Solution {
List<Integer> list = new ArrayList<>();
List<List<Integer>> res = new ArrayList<>();
// Set<List<Integer>> set = new HashSet<>();
public List<List<Integer>> permuteUnique(int[] nums) {
boolean[] check = new boolean[nums.length];
Arrays.sort(nums);
dfs(nums,check);
Set set = new HashSet(res);
res = new ArrayList<>(set);
return res;
}
public void dfs(int[] nums,boolean[] check)
{
if(nums.length == list.size())
{
res.add(new ArrayList<>(list));
return;
}
for(int i = 0 ; i< nums.length;i++)
{
if(check[i]==true) continue;
check[i] =true;
list.add(nums[i]);
dfs(nums,check);
check[i] = false;
list.remove(list.size()-1);
}
}
}
这个结果也比较垫底了。
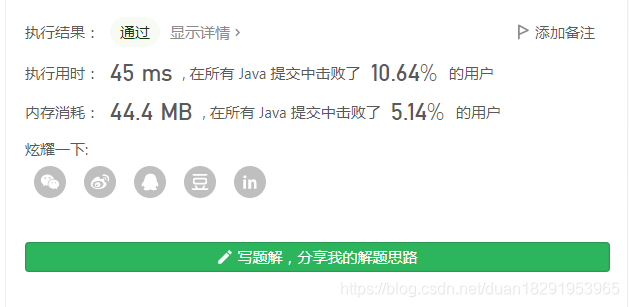
解决去重问题,就要去掉set还要另寻剪枝的好方法。
我在尝试过程中找到剪枝:
if(i>0&&nums[i]==nums[i-1]&check[i-1]==true) continue;
在for循环中加入这一行,就可以,不用再用set。
class Solution {
List<Integer> list = new ArrayList<>();
List<List<Integer>> res = new ArrayList<>();
// Set<List<Integer>> set = new HashSet<>();
public List<List<Integer>> permuteUnique(int[] nums) {
boolean[] check = new boolean[nums.length];
Arrays.sort(nums);
dfs(nums,check);
return res;
}
public void dfs(int[] nums,boolean[] check)
{
if(nums.length == list.size())
{
res.add(new ArrayList<>(list));
return;
}
for(int i = 0 ; i< nums.length;i++)
{
if(i>0&&nums[i]==nums[i-1]&check[i-1]==true) continue;
if(check[i]==true) continue;
check[i] =true;
list.add(nums[i]);
dfs(nums,check);
check[i] = false;
list.remove(list.size()-1);
}
}
}
但是呢,这个效率还是不是很高。

再寻找快速的方法,在评论中找到,当你回溯的时候,遇到重复的下一个元素可以跳过。
while(i<nums.length-1&&nums[i]==nums[i+1]) i++;
重新写:
class Solution {
List<Integer> list = new ArrayList<>();
List<List<Integer>> res = new ArrayList<>();
// Set<List<Integer>> set = new HashSet<>();
public List<List<Integer>> permuteUnique(int[] nums) {
boolean[] check = new boolean[nums.length];
Arrays.sort(nums);
dfs(nums,check);
return res;
}
public void dfs(int[] nums,boolean[] check)
{
if(nums.length == list.size())
{
res.add(new ArrayList<>(list));
return;
}
for(int i = 0 ; i< nums.length;i++)
{
if(!check[i]){
check[i] =true;
list.add(nums[i]);
dfs(nums,check);
check[i] = false;
list.remove(list.size()-1);
while(i<nums.length-1&&nums[i]==nums[i+1]) i++;
}
}
}
}
本次快了很多。
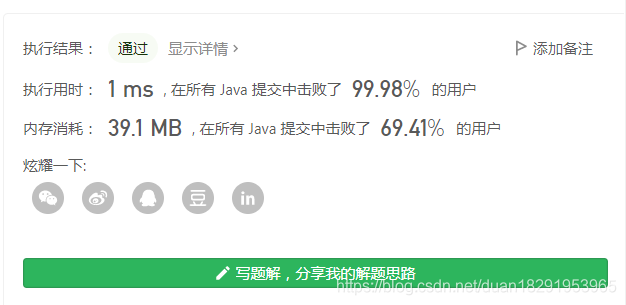
总结
之前那个排列组合就有个不重复的问题,不重复要是用set就回很慢,所以需要找到某个条件让重复去掉,所以一般就是排序后找到相邻的元素,想办法越过这个相邻元素,这样才能去掉重复元素。
还有 list转set和set转到list都可以新建一个,在括号里面放入就行,如
List<Integer> list = new ArrayList<>(set);
---------------------------------------------
Set<String>set = new HashSet<String>(list);
版权声明:本文为duan18291953965原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。