1.Introduction
本文是2019年发表在EMNLP上的一篇论文,这也是第一次图卷积技术第一次运用在ABSA中。我们知道在ABSA中目前主流的方法是基于注意力机制的模型。然而注意力机制并不能捕获一个句子中上下文及其方面之间的句法依赖,从而导致了对于一个给定的方面,注意力机制可能会错误地将句法上不相干的上下文词作为描述符。因此,作者通过图所具有的特定的性质来解决这些问题。在本文中,作者主要有三大贡献:1)利用句子的句法依赖结构,解决了ABSA中长期多词依赖性问题。2)提出了一个全新的面向方面的GCN模型。3)实验结果比其他模型的结果更好。
2.Model
2.1 Graph Convolutional Networks
GCN模型算是CNN模型的一种改进。在GCN中,各节点的更新处理只与其邻接节点有关。具体公式如下:

在等式的左边
![]()
定义为第l层中第i个节点的hideen representation。
在等式的右边
![]()
定义为领接矩阵中第i行与第j列的值,即第i个节点与第j个节点是否相连(相连值为1,不相连值为0)。对于一个给定图,会通过遍历整个图节点得到对应的邻接矩阵
![]()
。
![]()
定义为第l层的线性变换矩阵(可学习的参数)。
![]()
定义为第l-1层第j个节点的hideen representation。具体的公式执行过程如下图所示。

2.2 Aspect-specific Graph Convolutional Network
大体的模型如下图所示。
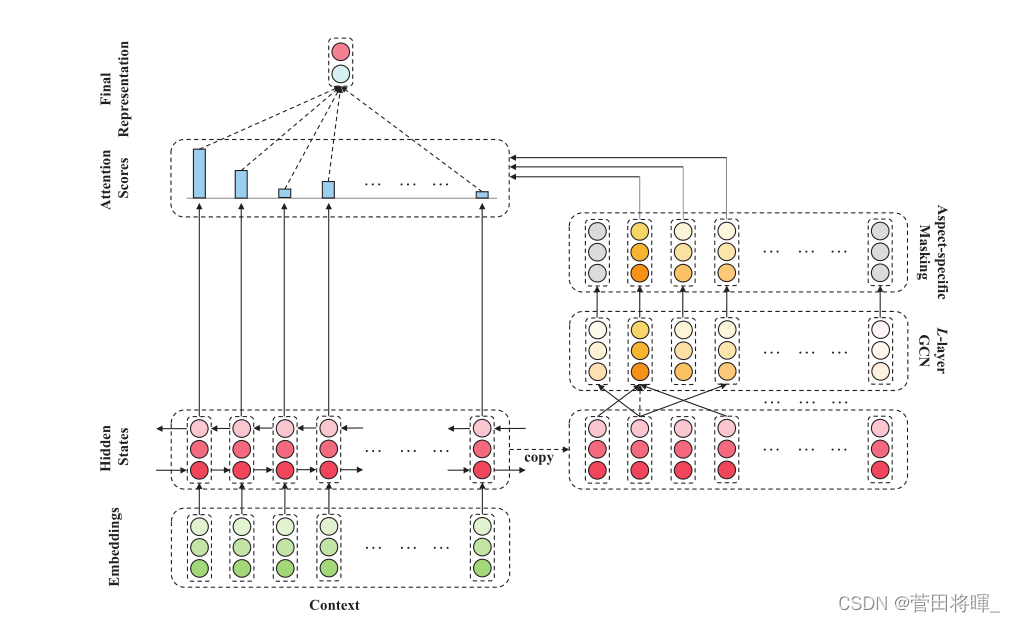
在这里我们把模型分为4个部分进行介绍。
2.2.1 Embedding and Bidirectional LSTM
这一部分主要是对输入的句子进行一个初始转换,并通过LSTM输出一个初始的hidden representation。对于一个给定n个词的句子
c={wc1,wc2,···,wcτ+1,···,wcτ+m,···,wcn−1,wcn},
这里我们将第τ+ 1 个字定义为方面词的开始。之后我们将其输入到对应的embedding层,在将对应的结果输入到一个双向LSTM中,得到
Hc={hc1,hc2,···,hcτ+1,···,hcτ+m,···,hcn−1,hcn}。
2.2.2 Graph Convolution over Dependency Trees
对于一个给定的句子,在其对应的依赖树被构造以后,我们会得到一个对应的邻接矩阵。我们知道依赖树是有向图,虽然GCN模型一般不考虑方向,但是它们可以适合有方向的场景。因此作者提出了两种基于ASGCN的变体:ASGCN-DG(无向的依赖图)和ASGCN-DT(有向的依赖树)。两者的区别在于领接矩阵上,有向的领接矩阵比无向的领接矩阵更加的稀疏。在双向LSTM输出的基础上,以多层方式执行ASGCN变体,即H0 = Hc以使节点了解上下文。ASGCN的变体层的具体公式如下。

在这里

是由上一层的hideen representation经过一定的变化演化而来的。
![]()
指的是第i个节点所对应的度数。
在这里我们可以看到,上一层的hideen representation并没有直接输入到下一层中,而是进行了一个位置感知转换的操作以后再输入。位置感知转换公式如下。
![]()

这样做的目的是以增强与方面相近的上下文词的重要性,可以减少依赖项解析过程中自然产生的噪声和偏差。
2.2.3 Aspect-specific Masking
这一层是将GCN层的输出中非方面的向量进行了一个隐藏。mask范围下所示。

mask输出:HLmask={0,···,hLτ+1,···,hLτ+m,···,0}
通过图卷积,这些特征以一种既考虑句法依赖性又考虑长程多词关系的方式来感知方面周围的上下文。
2.2.4 Aspect-aware Attention
这一层的作用在于将我们刚刚技术得到的
![]()
,通过注意力机制来检索重要的特征。注意力分数公式如下图所示:



从上图我们可以看到,这里先是将对应的
算出, 再将注意力分数乘以整个句子的hideen representation(之前LSTM的结果)。之后利用softmax操作得到对应的注意力分数。最后再经过一个线性变换与softmax操作得到结果
3.Experiments
模型比较:

消融实验(Ablation Study)

4.Conclusion
作为第一个“吃螃蟹”的人,作者的这篇文章也为以后GCN模型在ABSA的运用起到了铺垫的作用。在文末作者提出了3点需要改进的地方以供我们以后的研究。1)文中没有利用句法依赖树的边缘信息,即每条边缘的标签。2)GCN也可以和其他领域(domain knowledge )知道进行合并。3)ASGCN模型可以扩展为通过捕获各个方面之间的依赖关系来同时判断多个方面的情绪。