7.6
数据的读取与写入
在现实世界中,数据的存储形式常分为文件和数据库两大类,具体见下表。因此,为了实现数据处理,首先需要解决的问题是如何从文件或数据库中读取数据,并将其存储为DataFrame对象,或将处理后的DataFrame中的数据存储到文件或数据库中。
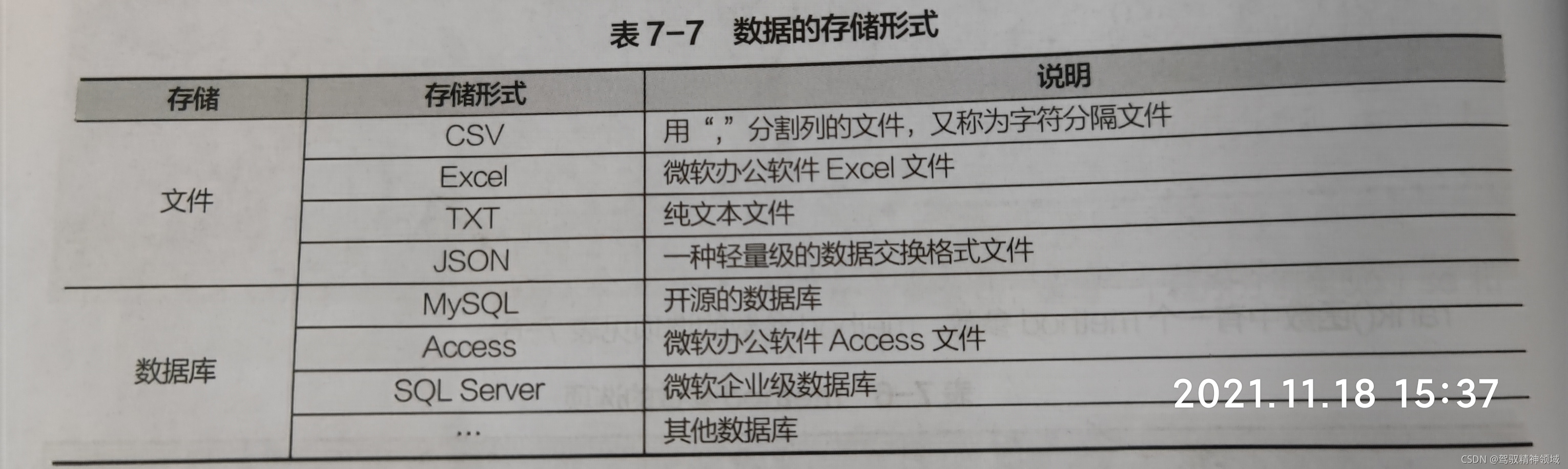
pandas库为实现文件的读取与写入提供了专门的工具–I/O API函数,这些函数可分为完全对称的两大类-读取函数和写入函数。常用的读/写数据源主要有文本文件、Excel文件、数据库文件、JSON文件,下面将分别介绍读/写这4类数据文件的操作
7.6.1 读/写文本文件
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。CSV是一种用分隔符分隔的文件格式,因为其分隔符不一定是逗号,因此,又被称为字符分隔文件
1.文本文件的读取
pandas提供了一些用于将表格型文本数据读取为DataFrame对象的函数,常用有read_csv()和read_table()函数。其中:
read_csv()函数:从文件,url,文件型对象中加载带分隔符的数据。默认分隔符为逗号(“,”)。
read_table()函数:从文件,url,文件型对象中加载带分隔符的数据。默认分隔符为制表符(“\t”)。
read_csv()函数格式如下:
pandas.read_csv(file,sep=’,’,header=‘infer’,names=None,index_col=0,
dtype=None,encoding=utf-8,engine=None,nrows=None)
read_csv()函数格式如下:
pandas.read_csv(file,sep=’\t’,header=‘infer’,index_col=None,
dtype=None,encoding=utf-8,engine=None,nrows=None)
函数中常用参数说明如下:
- file:接收string,表示CSV或TXT的文件名或路径
- sep:接收string,表示分隔符,read_csv()默认为逗号,read_table()默认为制表符。
- header:接收int或sequence,表示将某行数据作为列名。默认为infer,表示自动识别。
- names:接收array,表示列名,默认为None。
- index_col:接收int、sequence或False,表示索引列的位置,取值sequence则代表多重索引,默认为None。
- dtype:接收dict,代表写入的数据类型(列名为key,数据格式为values,默认为None)
- engine:接收C或python,表示数据解析引擎,默认为C。
- nrows:接收int。表示前n行,默认为None。
- encoding:表示文件的编码方式。常用的有UTF-8,UTF-16,GBK,GB2312,GB18030
【例】
以员工月工资收入信息为例,用read_csv()和read_table()函数分别读取salary.csv文件和salary.txt文件
import pandas as pd
print('数据保存在P盘的data目录下')
df=pd.read_csv('p:\data\salary.csv',encoding='GBK',nrows=3)
print('输出df:\n','\n',df)
数据保存在P盘的data目录下
输出df:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
df1=pd.read_table('p:\data\salary.txt',encoding='GBK',sep='\t',nrows=3)
print('输出df1:\n',df1)
输出df1:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
文本文件存储
文本文件的存储与其读取类似,对于结构化的数据,可以通过pandas的
to_csv()函数
实现以csv文件格式存储,to_csv()函数存储格式如下:
DataFrame.to_csv(path_or_buf=None,sep=’,’,na_rep=’’,columns=None,header=True,index=True,index_label=None,mode=‘w’,encoding=None)
参数说明如下:
path_or_buf:接收string,表示保存的文件名和路径。
sep:接收string,表示分隔符,默认为逗号。
na_rep:接收string,表示缺失值,默认为””。
columns:接收list,表示写出的列名。
header:接收boolean,表示是否将列名写出,默认为True
index:接收boolean,表示是否将行名(索引)写出,默认为True
index_label:接收sequence,表示索引名,默认为None。
mode:接收特定的string,表示数据写入的模式,默认为“w”
encoding:接收特定的string,表示存储文件的编码格式
【例】:读取员工的月工资收入信息,在DataFrame对象中增加一个员工工资收入信息为(潘传志,男,21,12000),然后将增加后的数据重新存储到salaryadd.csv中,示例代码如下:
import pandas as pd
print('数据文件保存在P盘的data目录下')
df=pd.read_csv('p:\data\salary.csv',encoding='GBK')
print('输出df:\n',df)
数据文件保存在P盘的data目录下
输出df:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
3 张艳 女 31 5000
4 陈丹 女 25 2800
5 李志敏 男 32 5000
6 张建国 男 45 8000
7 杨平远 男 50 10000
8 周源 男 40 7000
df.loc['add_row']=['潘传志','男',21,12000]
print('输出df:\n',df)
输出df:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
3 张艳 女 31 5000
4 陈丹 女 25 2800
5 李志敏 男 32 5000
6 张建国 男 45 8000
7 杨平远 男 50 10000
8 周源 男 40 7000
add_row 潘传志 男 21 12000
#新的数据储存到salaryadd.csv文件中
df.to_csv('P:\data\salaryadd.csv',encoding='GBK')
7.6.2 读/写Excel文件
1.Excel文件读取
pandas提供了read_excel()函数来读取Excel文件,其函数的语法格式如下:
pandas.read.excel(io,sheet_name=0,header=0,index_col=None,names=None,dtype=None)
参数说明:
- io:接收string,表示文件名和路径
- sheet_name:接收string,int,表示Excel表内数据的分表位置,默认为0
- header:接收int或sequence,表示将某行的数据作为列名,取值为int时代表将该列作为列名,取值为sequence时则表示多重列索引,默认为infer,表示自动识别
- names:接收array,表示列名,默认为None
- index_col:接收int、sequence或False,表示索引列的位置。取值sequence代表多重索引,默认为None
- dtype:接收dict,代表写入的数据类型(列名为key,数据格式为values),默认为None
注意:
在执行pandas读取Excel的操作时,需要安装xlrd库,并且在当前代码导入xlrd库。
【例】:将员工月工资收入信息salary.csv文件打开,另存为salary.xlsx文件,然后将该文件的数据读取为DataFrame对象
import pandas as pd
import xlrd
df=pd.read_csv('p:\data\salary.csv',encoding='GBK')
df
| name | sex | age | salary | |
|---|---|---|---|---|
| 0 | 李明 | 男 | 24 | 3600 |
| 1 | 王小红 | 女 | 28 | 4000 |
| 2 | 杨勇 | 男 | 30 | 4500 |
| 3 | 张艳 | 女 | 31 | 5000 |
| 4 | 陈丹 | 女 | 25 | 2800 |
| 5 | 李志敏 | 男 | 32 | 5000 |
| 6 | 张建国 | 男 | 45 | 8000 |
| 7 | 杨平远 | 男 | 50 | 10000 |
| 8 | 周源 | 男 | 40 | 7000 |
df.to_excel('P:\data\salary1.xlsx')
df=pd.read_excel('P:\data\salary.xls',sheet_name='salary')
print('输出df:\n',df)
输出df:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
3 张艳 女 31 5000
4 陈丹 女 25 2800
5 李志敏 男 32 5000
6 张建国 男 45 8000
7 杨平远 男 50 10000
8 周源 男 40 7000
2.Excel文件存储
格式:
DataFrame.to_excel(excel_writer=None,sheet_name=‘None’,np_rep=’’,header=True,index=True,index_label=None,mode=‘w’,encoding=None)
参数说明如下:
- excel_writer:接收string,表示保存的文件名和路径
- shheet_name:接收string,表示保存到Excel表内数据的分表名称,默认为None
- np_rep:接收string,表示缺失值,默认为””
- header:接收boolean,表示是否将列名写出,默认为True
- index:接收boolean,表示是否将行名(索引)写出,默认为true
- index_label:接收sequence,表示索引名,默认为None
- mode:接收特定的string,表示数据写入的模式,默认为“w”
- encoding:接收特定的string,表示存储文件编码格式
【例】读取员工的月工资收入信息,在读取salary.xls文件后,DataFrame对象中增加一个元工资收入信息为(李丽,女,25,3000),然后将增加后的数据重新存储到salaryadd.xls文件中
import pandas as pd
import xlrd
import xlwt
df=pd.read_excel('p:\data\salary.xls',sheet_name='salary')
print('输出df:\n',df)
df.loc['add_row']=['李丽','女',25,3000]
print('输出df:\n',df)
df.to_excel('p:\data\salaryadd.xlsx',encoding='GBK')
输出df:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
3 张艳 女 31 5000
4 陈丹 女 25 2800
5 李志敏 男 32 5000
6 张建国 男 45 8000
7 杨平远 男 50 10000
8 周源 男 40 7000
输出df:
name sex age salary
0 李明 男 24 3600
1 王小红 女 28 4000
2 杨勇 男 30 4500
3 张艳 女 31 5000
4 陈丹 女 25 2800
5 李志敏 男 32 5000
6 张建国 男 45 8000
7 杨平远 男 50 10000
8 周源 男 40 7000
add_row 李丽 女 25 3000
7.6.3 读/写数据库文件
1.SQLAlchemy连接MySQL
(1)安装SQLAlchemy
pip install SQLAlchemy
pip insatll pymysql
(2)创建MySQL数据库
创建一个数据库,库名为salary。
from sqlalchemy import create_engine
engine=create_engine('mysql+pymysql://root:123456@localhost:3306/salary?\charset=utf-8')
print(engine)
Engine(mysql+pymysql://root:***@localhost:3306/salary?%5Ccharset=utf-8)
数据库产品名+连接工具名://用户名:密码@数据库IP地址:数据库端口/数据库名称? charset=数据库数据编码
2.读取数据库文件
pandas提供了3个读取数据库文件的函数,它的作用如下:
- read_sql()函数:既可读取数据库中的某个表,又可实现查询操作。
- read_sql_table()函数:只能读取数据库的某一个表格,不能实现查询操作。
- read_sql_query()函数:可实现查询操作,但不能直接读取数据库中的某个表
- 将文件传到mysql数据库中还需要下载python覆盖率统计工具包:coverage
read_sql():
pandas.read_sql(sql,con,index_col=None,coerce_float=True,columns=None)
read_sql_table():
pandas.read_sql_table(table_name,con,schema=None,index_col=None,coerce_float=True,columns=None)
read_sql_query():
pandas.read_sql_query(sql,con,index_col=None,coerce_float=True)
参数说明如下:
- sql:接收string,表示读取数据库的表名或者SQL语句,无默认值
- table_name:接收string,表示读取数据库的表名,无默认值
- con:接收数据库连接。表示接收数据库连接信息,无默认值
- index_col:接收int、sequence或False,表示设定的列作为行名。如果是一个数列,则是多重索引,默认为None。
- coerce_float:接收boolean:将数据库中的decimal类型的数据转换为pandas中float类型的数据,默认为True
- colums:接收int,表示读取数据的列名,默认为None
【例】分别运用read_sql(),read_sql_table(),read_sql_query()函数读取mysql数据库中的文件salary,并观察这三个函数的特点
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/salary?\
charset=gb2312')
print(engine)
Engine(mysql+pymysql://root:***@localhost:3306/salary?charset=gb2312)
df = pd.read_csv('p:\data\salary.csv',encoding='GBK')
df
| name | sex | age | salary | |
|---|---|---|---|---|
| 0 | 李明 | 男 | 24 | 3600 |
| 1 | 王小红 | 女 | 28 | 4000 |
| 2 | 杨勇 | 男 | 30 | 4500 |
| 3 | 张艳 | 女 | 31 | 5000 |
| 4 | 陈丹 | 女 | 25 | 2800 |
| 5 | 李志敏 | 男 | 32 | 5000 |
| 6 | 张建国 | 男 | 45 | 8000 |
| 7 | 杨平远 | 男 | 50 | 10000 |
| 8 | 周源 | 男 | 40 | 7000 |
3.存储数据到数据库中
把salary.csv存储到mysql的数据库salary1中,具体说明如下图:

df.to_sql('salary1',con=engine,if_exists='replace')
#使用read_sql_query查看数据表的数目
tables=pd.read_sql_query('show tables',con=engine)
tables
| Tables_in_salary | |
|---|---|
| 0 | salary. |
| 1 | salary1 |
#使用read_sql_table()读取salary1数据表的数据
mysql=pd.read_sql_table('salary1',con=engine)
print(mysql)
index name sex age salary
0 0 李明 男 24 3600
1 1 王小红 女 28 4000
2 2 杨勇 男 30 4500
3 3 张艳 女 31 5000
4 4 陈丹 女 25 2800
5 5 李志敏 男 32 5000
6 6 张建国 男 45 8000
7 7 杨平远 男 50 10000
8 8 周源 男 40 7000
#使用read_sql()获取salary1数据表的数据
salary1=pd.read_sql('salary.',con=engine)
print(salary1)
index name sex age salary
0 0 李明 男 24 3600
1 1 王小红 女 28 4000
2 2 杨勇 男 30 4500
3 3 张艳 女 31 5000
4 4 陈丹 女 25 2800
5 5 李志敏 男 32 5000
6 6 张建国 男 45 8000
7 7 杨平远 男 50 10000
8 8 周源 男 40 7000
2.读/写JSON文件
1、JSON简介
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。
JSON具有良好的可读和便于快速编写的特性,适合于服务器与JavaScript客户端的交互,是目前网络中主流的数据传输格式之一,应用十分广泛。
2、JSON基本语法
JSON数据是以一种key-value(键值对)的方式存在。JSON值可以是:数字(整数或浮点数)、字符串(在双引号中)、逻辑值(true 或 false)、数组(在方括号中)、对象(在花括号中)、null(空值)等。
例如:json={“name”:“小芳”, “age”:16}或
json={"name":"小芳"," hobby ":[ "唱歌","编程","打球"]}
3、Python读取JSON文件
在Python中若要进行JSON文件的读写,需要添加json模块。在Python中读取JSON文件是通过调用json.load()函数来实现的,json.load()函数的语法格式:
son.load(file,encoding="utf-8")
函数中的参数file表示JSON文件名,encoding表示编码方式。
4、Python存储JSON文件
存储JSON文件需要调用json.dump()函数,该函数的语法格式:
json.dumps(data, file, sort_keys=False, indent=4, separators=(',', ': '),
encoding="utf-8", ensure_ascii=False)
参数说明如下:
data:表示存储的JSON数据
file:表示存储的JSON文件名
sort_keys:表示是否排序,默认为False,不排序
indent:指定每个变量的缩进量,一般填4,缩进4格
separators:消除多余的空格,以减小文件大小
encoding:编码方式,默认为“utf-8”
import json
#写文件
data=[{'a':'apple','b':'banana','c':[1,2,3]},11,'test',True]
file=open('p:/data/jsontest1.txt','w')
json.dump(data,file)
file.close()
#读文件
file=open('p:/data/jsontest1.txt')
data=json.load(file,encoding="utf-8")
print(data)
[{'a': 'apple', 'b': 'banana', 'c': [1, 2, 3]}, 11, 'test', True]