一、Sink Processors
接下来看一下Sink处理器
Sink Processors类型包括这三种:Default Sink Processor、Load balancing Sink Processor和Failover Sink Processor
DefaultSink Processor是默认的,不用配置sinkgroup,就是咱们现在使用的这种最普通的形式,一个channel后面接一个sink的形式。
Load balancing Sink Processor是负载均衡处理器,一个channle后面可以接多个sink,这多个sink属于一个sink group,根据指定的算法进行轮询或者随机发送,减轻单个sink的压力。
Failover Sink Processor是故障转移处理器,一个channle后面可以接多个sink,这多个sink属于一个sink group,按照sink的优先级,默认先让优先级高的sink来处理数据,如果这个sink出现了故障,则用优先级低一点的sink处理数据,可以保证数据不丢失。
下面我们来看两个案例:
负载均衡、故障转移
先看负载均衡
二、Load balancing Sink Processor【负载均衡】
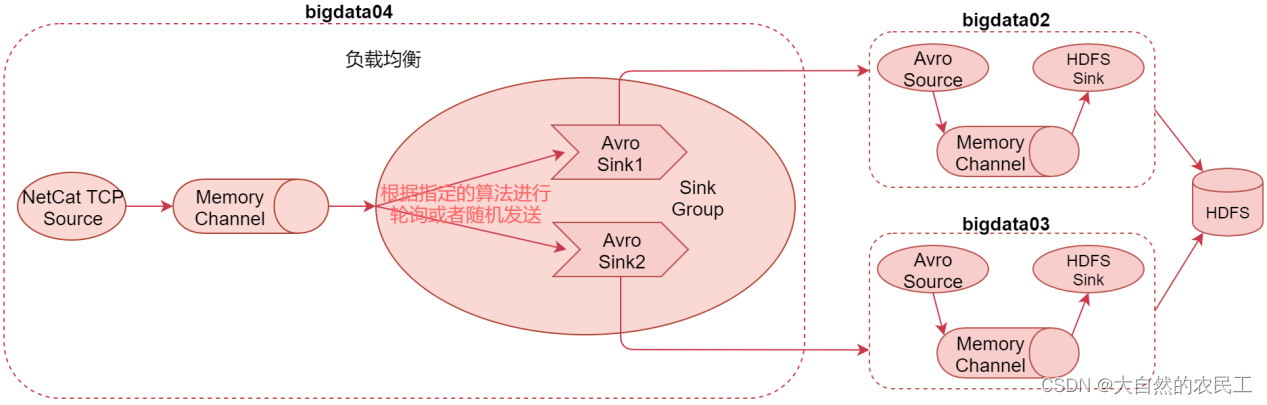
看这个图,在这里面一个channel后面接了两个sink,这两个sink属于一个sink group,具体的数据发送策略我们来看一下文档
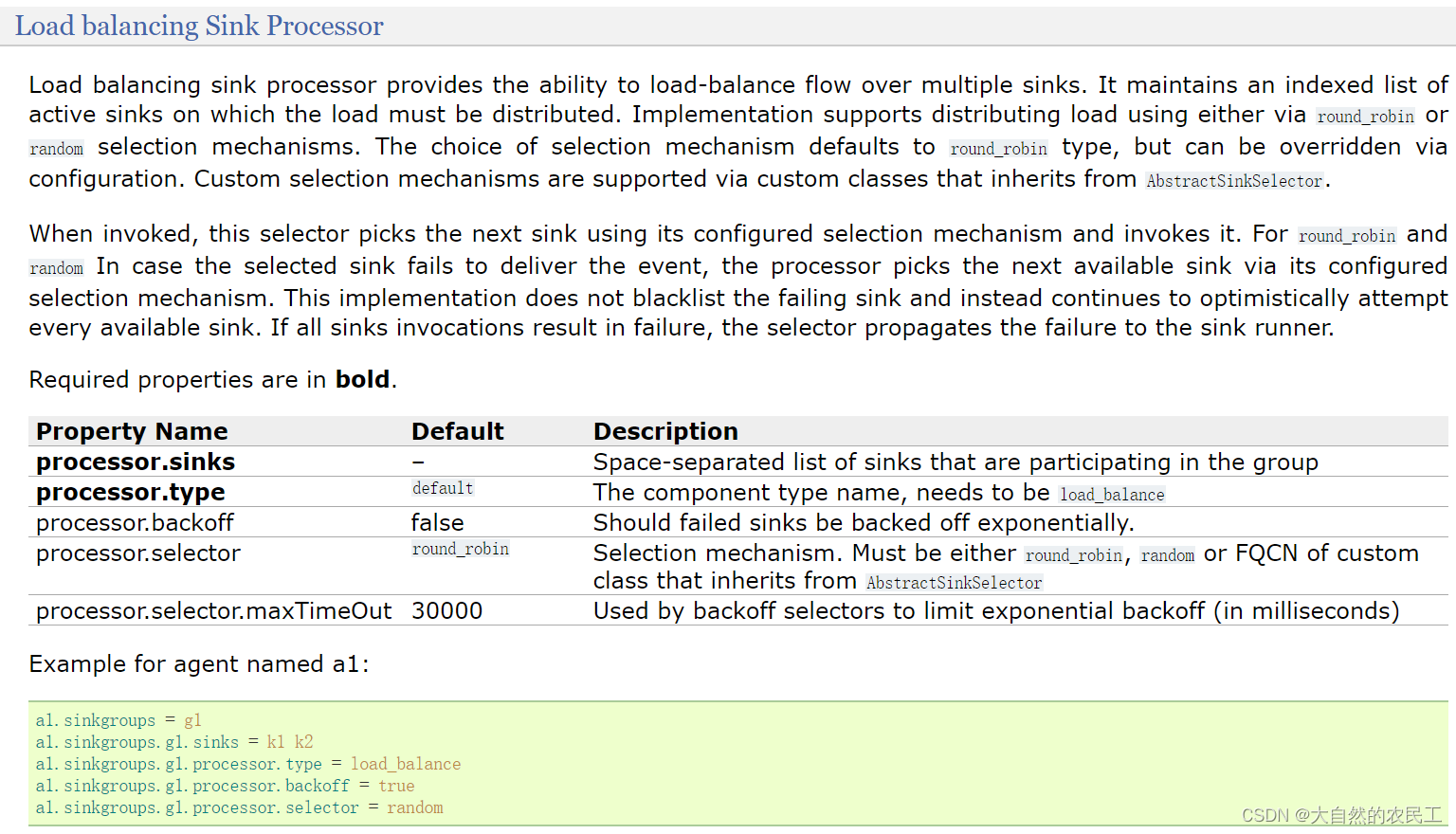
看中间的参数信息,
processor.sinks:指定这个sink groups中有哪些sink,指定sink的名称,多个的话中间使用空格隔开即可【注意,这里写的是processor.sinks,但是在下面的example中使用的是sinks,实际上就是sinks,所以文档也是有一些瑕疵的,不过Flume的文档已经算是写的非常好的了】
processor.type:针对负载均衡的sink处理器,这里需要指定load_balance
processor.selector:此参数的值内置支持两个,round_robin和random,
round_robin表示轮询,按照sink的顺序,轮流处理数据,random表示随机。
processor.backoff:默认为false,设置为true后,故障的节点会列入黑名单,过一定时间才会再次发送数据,如果还失败,则等待时间是指数级增长;一直到达到最大的时间。
如果不开启,故障的节点每次还会被重试发送,如果真有故障节点的话就会影响效率。
processor.selector.maxTimeOut:最大的黑名单时间,默认是30秒
最后看一下里面提供的例子:
# 指定sinkgroup的名称
a1.sinkgroups = g1
# 指定sinkgroup中有哪些sink
a1.sinkgroups.g1.sinks = k1 k2
# 使用负载均衡策略
a1.sinkgroups.g1.processor.type = load_balance
# 开启后,故障的节点会列入黑名单
a1.sinkgroups.g1.processor.backoff = true
# 指定sinkgroup的数据发送策略
a1.sinkgroups.g1.processor.selector = random
这个负载均衡案例可以解决之前单节点输出能力有限的问题,可以通过多个sink后面连接多个Agent实现负载均衡,如果后面的Agent挂掉1个,也不会影响整体流程,只是处理效率又恢复到了之前的状态。
下面来配置Agent,先配置bigdata04节点上的这个Agent
[root@bigdata04 conf]# vi load-balancing.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
# 配置source组件
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件,[为了方便演示效果,把batch-size设置为1]
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=192.168.182.101
a1.sinks.k1.port=41414
a1.sinks.k1.batch-size = 1
a1.sinks.k2.type=avro
a1.sinks.k2.hostname=192.168.182.102
a1.sinks.k2.port=41414
a1.sinks.k2.batch-size = 1
# 配置sink策略
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
接着配置bigdata02的Agent
[root@bigdata02 conf]# vi load-balancing-101.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件[为了区分两个sink组件生成的文件,修改filePrefix的值]
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/load_balance
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = data101
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
接着配置bigdata03上的Agent
[root@bigdata03 conf]# vi load-balancing-102.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件[为了区分两个sink组件生成的文件,修改filePrefix的值]
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/load_balance
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = data102
a1.sinks.k1.hdfs.fileSuffix = .log
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:bigdata04中指定的a1.sinks.k1.port=41414和a1.sinks.k2.port=41414需要和bigdata02和bigdata03中的a1.sources.r1.port = 41414的值保持一致
接下来开始启动这几个Agent
需要先启动bigdata02和bigdata03上的Agent,最后启动bigdata04上的Agent
启动bigdata02上的Agent
注意:在启动之前需要到/etc/profile中先配置HADOOP_HOME环境变量,因为这个Agent中使用到了hdfs
[root@bigdata02 apache-flume-1.9.0-bin]# vi /etc/profile
........
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
[root@bigdata02 apache-flume-1.9.0-bin]# source /etc/profile
[root@bigdata02 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/load-balancing-101.conf -Dflume.root.logger=INFO,console
启动bigdata03上的Agent
注意:在启动之前需要到/etc/profile中先配置HADOOP_HOME环境变量,因为这个Agent中使用到了hdfs
[root@bigdata03 apache-flume-1.9.0-bin]# vi /etc/profile
........
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
[root@bigdata03 apache-flume-1.9.0-bin]# source /etc/profile
[root@bigdata03 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/load-balancing-102.conf -Dflume.root.logger=INFO,console
启动bigdata04上的Agent
[root@bigdata04 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf conf --conf-file conf/load-balancing.conf -Dflume.root.logger=INFO,console
通过telnet产生数据
[root@bigdata04 ~]# telnet localhost 44444
Trying ::1...
Connected to localhost.
Escape character is '^]'.
hehe
OK
haha
OK
分别到bigdata02和bigdata03中hdfssink指定的path中验证数据
[root@bigdata01 soft]# hdfs dfs -ls hdfs://192.168.182.100:9000/load_balance
Found 2 items
-rw-r--r-- 2 root supergroup 6 2020-05-03 12:44 hdfs://192.168.182.100:9000/load_balance/data101.1588481094383.log.tmp
-rw-r--r-- 2 root supergroup 6 2020-05-03 12:44 hdfs://192.168.182.100:9000/load_balance/data102.1588481087463.log.tmp
[root@bigdata01 soft]# hdfs dfs -cat hdfs://192.168.182.100:9000/load_balance/data101.1588481094383.log.tmp
haha
[root@bigdata01 soft]# hdfs dfs -cat hdfs://192.168.182.100:9000/load_balance/data102.1588481087463.log.tmp
hehe
这就是sink负载均衡的使用,在这里面我们使用了轮询的策略,大家下去以后可以使用random试验一下,只需要修改bigdata04配置文件中a1.sinkgroups.g1.processor.selector的值即可。