Spark两种共享变量:
广播变量
(broadcast variable)与
累加器
(accumulator)
累加器用来对
信息进行聚合
,而广播变量用来
高效分发较大的对象
。
共享变量出现的原因:
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
广播变量的引入
:
Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是 Spark 会为每个操作分别发送。
用一段代码来更直观的解释:

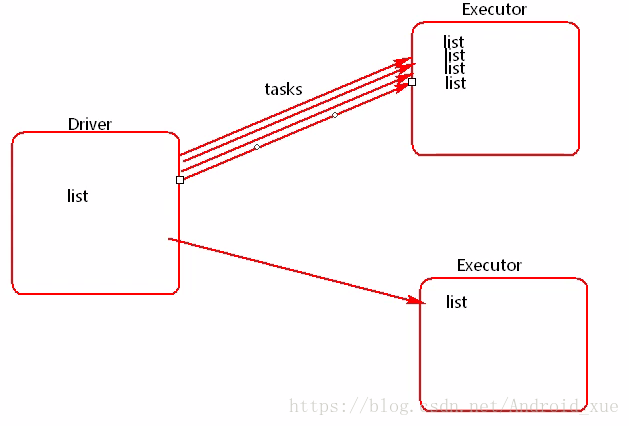
list是在driver端创建的,但是因为需要在excutor端使用,所以driver会把list以task的形式发送到excutor端,如果有很多个task,就会有很多给excutor端携带很多个list,如果这个list非常大的时候,就可能会造成内存溢出(如下图所示)。这个时候就引出了广播变量。
使用广播变量后:
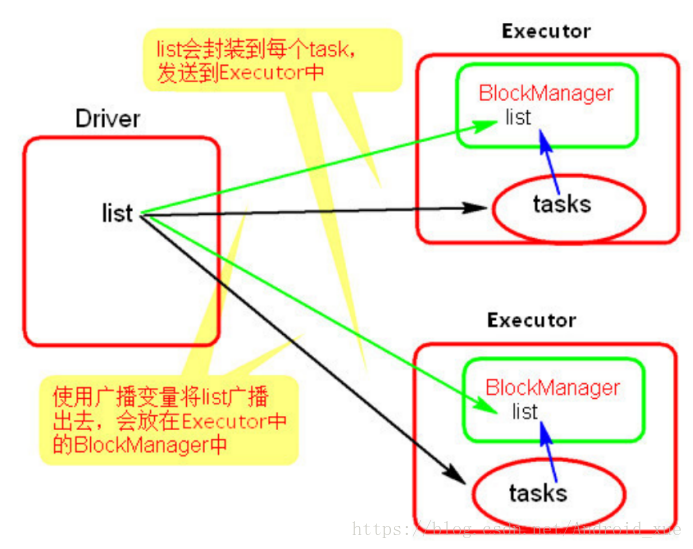
使用广播变量
的过程很简单:
(1) 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
(2) 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
案例如下
:
object
BroadcastTest
{
def
main
(
args
: Array[
String
]): Unit = {
val
conf
=
new
SparkConf().
setMaster
(
“local”
).
setAppName
(
“broadcast”
)
val
sc
=
new
SparkContext(
conf
)
val
list
=
List
(
“hello java”
)
val
broadcast
=
sc
.
broadcast
(
list
)
val
linesRDD
=
sc
.
textFile
(
“./word”
)
linesRDD
.
filter
(
line
=> {
broadcast
.
value
.
contains
(
line
)
}).
foreach
(
println
)
sc
.
stop
()
}
}
注意事项:
能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
广播变量只能在Driver端定义,不能在Executor端定义。
在Driver端可以修改广播变量的值,在Executor
端无法修改广播变量的值
。
我们发现打印的结果为

依然是
driver和excutor
端的数据不能共享
的问题。excutor端修改了变量,根本不会让driver端跟着修改,这个就是累加器出现的原因。
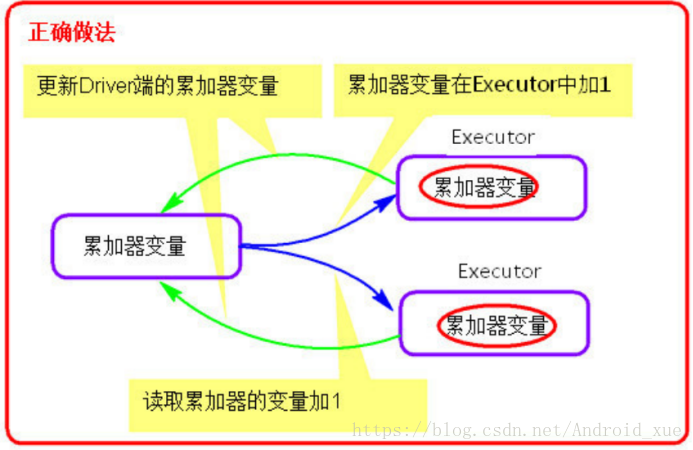
累加器的作用:
提供了将工作节点中的值聚合到驱动器程序中的简单语法。(如下图)
常用场景:
调试时对作业执行过程中的事件进行计数。

累加器的用法如下所示:
(1)通过在driver中调用 SparkContext.accumulator(initialValue) 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值initialValue 的类型。
(2)Spark闭包(函数序列化)里的excutor代码可以使用累加器的 += 方法(在Java中是 add )增加累加器的值。
(3)driver程序可以调用累加器的 value 属性(在 Java 中使用 value() 或 setValue() )来访问累加器的值。
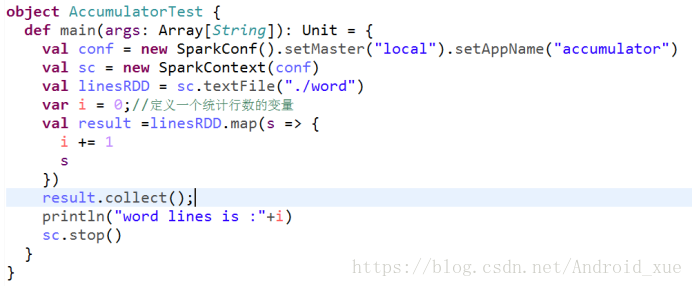
案例如下:
object
AccumulatorTest
{
def
main
(
args
: Array[
String
]): Unit = {
val
conf
=
new
SparkConf().
setMaster
(
“local”
).
setAppName
(
“accumulator”
)
val
sc
=
new
SparkContext(
conf
)
val
accumulator
=
sc
.
accumulator
(
0
);
//创建accumulator并初始化为0
val
linesRDD
=
sc
.
textFile
(
“./word”
)
val
result
=
linesRDD
.
map
(
s
=> {
accumulator
.
add
(
1
)
//有一条数据就增加1
s
})
result
.
collect
();
println
(
“words lines is :”
+
accumulator
.
value
)
sc
.
stop
()
}
}
输出结果:

注意事项
累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor
端更新
(如下图)。