笔者近日在修改项目原有MapReduce作业中的事件流转化率/漏斗计算模块。
那么既然有事件流相关计算,如何生成有时间顺序的事件流路径,再如何基于时间顺序进行漏斗模型的匹配,成为了本次MapReduce作业设计中的一部分思考点。
笔者翻阅了MapReduce的自身机制以及其中的四次排序机制,总结出了以下内容。即,本文将分为以下三点进行探讨:
- MapReduce的排序方式为什么,为什么选用该种方式?
- MapReduce自身的排序机制分别在哪几个阶段进行,以及为什么MapReduce在这几个阶段的排序是必要的。
- 如何在实际问题中巧用MR的排序:自定义比较器Comparator,自定义分组器Partitioner
1、首先明确MR的排序算法是什么。而MR为什么选用这几种排序方式?
学过算法课的同学们应该记得,排序的种类多种多样,有插入排序,并归排序,堆排序,快速排序,基数排序,计数排序,桶排序等方法。不同方法拥有不同的最坏情况运行时间,以及平均情况/期望运行时间。
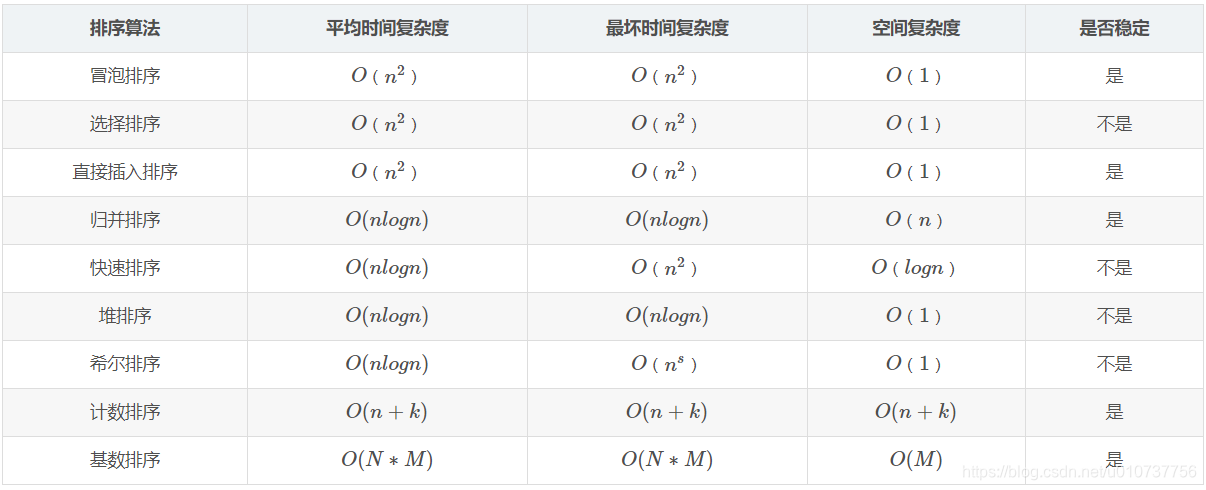
注:表格来源:
排序算法时间复杂度、空间复杂度、稳定性比较
排序机制作为MapReduce、甚至大数据框架中很重要的一环,值得我们进行向下思考与探索。在实际应用中,MapReduce的过程中存在三个阶段的排序。分别在Map、Reduce以及最终输出结果阶段:
1、在Map阶段后,shuffle阶段进行k-v溢写时,采用的是快排;
2、Shuffle阶段,将溢出文件的合并使用的则是归并;
3、在Reduce阶段,通过shuffle从Map获取的文件进行合并的时候采用的也是归并;
4、Reduce最后阶段,使用了堆排作为最后的合并过程。
- 并归排序(Merge Sort)
并归排序的原理可参考以下动图:
并归排序采用了分治策略。(分解Divide-解决Conquer-合并Combine)归并排序的方法为,首先让数组中的每一个数单独成为长度为1的区间,然后两两一组有序合并,得到长度为2的有序区间,依次进行,直到合成整个区间。
而应用于合并已经排序好的有序序列,归并排序的工作原理如下:
第一步:申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
第二步:设定两个指针,最初位置分别为两个已经排序序列的起始位置
第三步:比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
重复步骤3直到某一指针超出序列尾后,再将另一序列剩下的所有元素直接复制到合并序列尾。
并归排序运用了分治思想,它的时间复杂度为nlogn。并归排序在MapReduce框架中,被应用于合并以及排序好的有序序列。因此在合并溢出文件。以及Reduce阶段,通过shuffle从Map获取的文件进行合并的时候采用的也是归并。
- 快速排序 (quick sort)
快速排序的原理可参考以下动图:
快速排序从小到大排序:在数组中随机选一个数(默认数组首个元素),数组中小于等于此数的放在左边,大于此数的放在右边,再对数组两边递归调用快速排序,重复这个过程。
快读排序的时间复杂度依赖于数据的划分是否平衡。
快速排序的最坏运行时间与插入排序相等为n^2,如果划分是平衡的,那么快排的期望运行时间为nlogn(此时它的时间复杂度与并归排序相等。)甚至在实际应用中,由于快排的平均性能很好,nlogn中隐藏的常数因子非常小,它通常是最优选择。
另外,它能够进行原址排序,所以在虚存环境中,快排也是很好的选择。这也是为什么大数据框架多选用快排、堆排序的原因之一。
ref:
Performance of Quicksort adapted for virtual memory use
注:虽然堆排序也具有空间原址性,但堆排序的稳定性低于快速排序。推断这可能是溢写阶段不采用堆排序的原因?(待确认)不然无法解释为什么堆排序具有1的空间复杂度,却不被应用于溢写过程中环形缓冲区内存中的排序。
- 堆排序(heapsort)
堆排序的原理可参考以下动图:
堆排序的堆指的是数据结构中的堆而非java中的堆。堆排序的算法为:首先将数组元素建成大小为n的大顶堆,堆顶(数组第一个元素)是所有元素中的最大值,将堆顶元素和数组最后一个元素进行交换,再将除了最后一个数的n-1个元素建立成大顶堆,再将最大元素和数组倒数第二个元素进行交换,重复直至堆大小减为1。

堆排序与并归排序都具有相同的时间复杂度nlogn。而与并归排序不同的是,堆排序与插入排序(时间复杂度n^2)相同,都具有空间原址性,即任何时候都只要常数个额外的元素空间储存临时数据。且堆排序的空间复杂度为1,小于并归排序与快速排序的空间复杂度n,因此堆排序适用于数据量大的排序场景来节省排序所占空间,这可能也是为什么MapReduce最终阶段的排序选用堆排序的原因。
关于堆排序,有看到一个面试相关的漫画,很有趣:
ref:
大数据排序算法-堆排序(针对大数据使用较多)
综上,并归排序、快速排序、堆排序的的运行时间复杂度都为nlogn。时间复杂度相同的基础上,堆排序的空间复杂度为1,优于并归排序与快速排序的空间复杂度n,但相对并归排序与快速排序的稳定性稍逊。
并归排序由于自身排序特性,通常用于合并有序文件。
由于原址排序特性,快排被用于溢写阶段。
由于较低的空间复杂度,堆排序被用于最终排序阶段。
思考:以上皆为个人推断。而MapReduce框架设计之初是否真的这么考虑?
下周需要再查找MapReduce框架设计论文,再过一遍排序部分
2、已知MR的排序分别在三个阶段进行,那为什么MR在这三个阶段的排序是必要的。
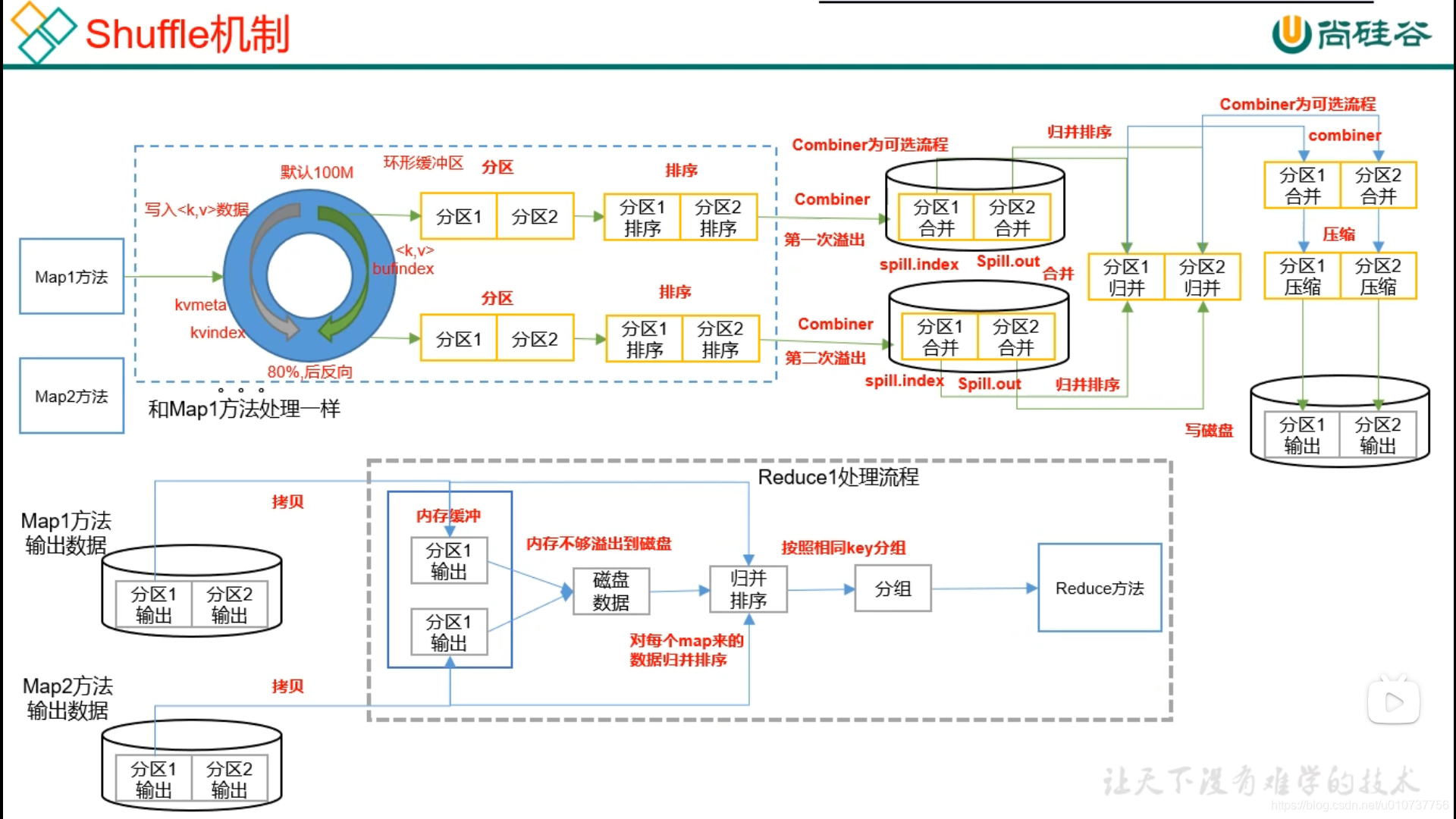
整个MapReduce流程如上图所示:
1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中。
在环形缓冲区内进行排序(第一次排序:内存中,局部排序,快排)
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件 。在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序。
(第二次排序:磁盘中,分区内部进行局部排序,并归排序)
4)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
5)ReduceTask会取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并
(第三次排序,磁盘中,ReduceTask内部局部排序,归并排序)
6)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
7)ReduceTask计算完成后,对多个ReduceTask的输出结果进行堆排序
(第四次排序,磁盘中,ReduceTask的结果排序,堆排序)
那么定位了四次排序的位置,再来谈一谈个人对MR框架采用这么多次排序的理解。即,为什么MapReduce需要这四次排序,如果不进行排序会造成什么后果?
第一次排序:
第二次排序:
第三次排序:
第四次排序:
3、如何在实际问题中巧用MR的排序。本文将举例说明如何自定义比较器Comparator,如何自定义分组器Partitioner
那么既然MapReduce会经过多次排序,关于如何在实际排序相关的问题中利用MapReduce自身的排序机制,减轻资源消耗,本文将举例说明:
1、部分排序
2、全排序
3、辅助排序
4、事件流/漏斗模型中的应用