1 简介
本文根据2019年5月《OpenPose: Realtime Multi-Person 2D PoseEstimation using Part Affifinity Fields》翻译总结。不过openpose在2017年就发了。这个是更新版。
人体姿态估计面临多种挑战:1)每张图片可能包含未知数量的人,他们出现在不同的未知,也不同的大小尺度;2)人体之间的交互,如接触,产生了复杂的空间预测;3)预测时间随着人的数量增加,增加了在实时场景预测的难度。
人体姿态估计有两种方法,分别是top-down方法和bottom-up方法。其中top-down方法先预测人,再预测每个人的姿体。而bottom-up方法就直接对多人姿体同时预测,openpose采用的这种。
本版本较2017CVPR版本有如下新贡献:
- 我们证明PAF( Part Affifinity Fields,下面正文介绍)对于提高准确率是必要的,而身体部分预测精炼不是重要的。所以我们增加了网络深度,去除了身体部分精炼阶段。最终网络再速度方面增加200%,再准确率方面增加7%。
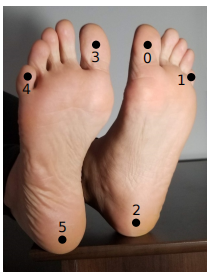
- 我们提出了一个脚部数据,包括1.5万个脚部实例。我们显示了采用身体和脚部关键点的联合模型在保持只采用身体的模型的速度下,也保持了准确率。脚本标注示例如下:大拇指、小拇指、脚跟。
3.我们显示了我们模型的泛化性,可以应用于机动车关键点检测。
4.我们开放了openpose。应该是首个实时的多人2D姿体检测系统,包括身体、脚部、手、脸的关键点检测。
2 方法

如上图,描述了openpose的处理过程。首先输入一个w*h的图像(图a),接着一个前向网络预测出身体部位位置的置信图( Confidence Maps)S(图b),和part affifinity fields (PAFs) L (图c),其表示身体部位之间连接的程度。

最后,置信图和PAF通过一个贪婪算法(图d),输出最终的2D关键点(图e)。
2.1 网络结构
如下图,每一步t,其前半部分预测part affifinity fields (PAFs) L,后半部分预测置信图( Confidence Maps)S。
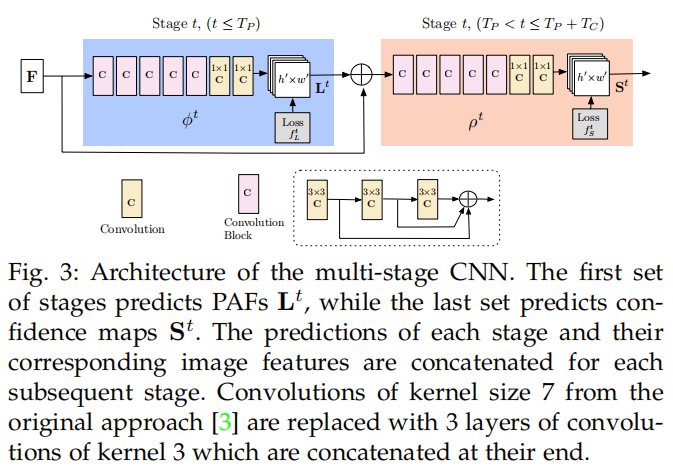
2.2 同时检测和组合
上面图片(Fig 3)中的F是有一个CNN生成的特征图,该CNN采用GNN的前面10层初始化和微调的。

损失函数分别如下:

总体损失函数如下:
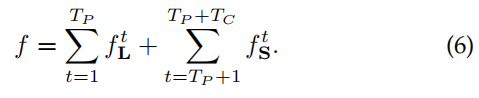
3.3 part affifinity fields (PAFs)
PAF同时提供位置和方向信息,如下图:

对于肢体区域的每一个像素,有一个2D向量编码方向,该方向表示从肢体一个部位到另一个。每种肢体都有一个对应的PAF,其连接两个关联的身体部位。


公式4中L的groundtruth等于图片中所以人的L的平均值,如下:
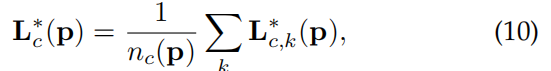
3.4 使用PAFs多人解析
多人问题说是NP-HARD的,为此,我们采用了下面两个方法。如下图,1)我们采用图c的方法,选择最小化数量的边来生成树形骨架,而不是使用完整的图(图b)。2)我们进一步压缩匹配问题到两两(bipartite)匹配问题,如图d。

3 openpose
3.1 系统
openpose可以运行在不同的平台,包括Ubuntu、windows、Max OSX、嵌入式系统(如Nvidia Tegra TX2)。
也支持不同的硬件,如CUDA GPUs、OpenCL GPUs和CPU。
openpose包括3个不同模块:a)身体和脚本检测;b)手势检测;c)脸部检测。
OpenCV已支持openpose。
4 实验结果
4.1 MPII 多人数据集上的结果
如下表,openpose效果较好,预测速度也快。

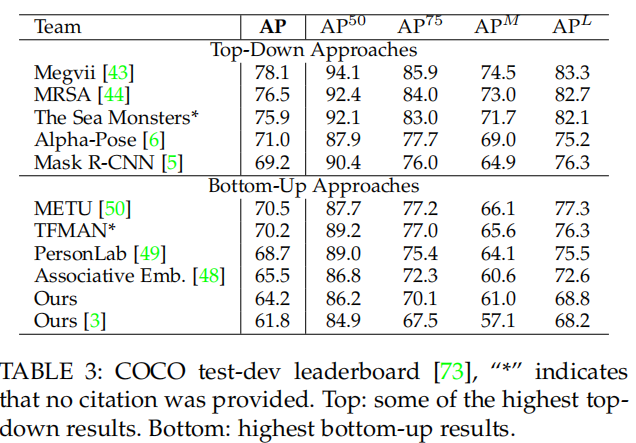
4.2 COCO关键点结果
4.3 预测时间分析
top-down方法,如Mask R-CNN、Alpha-Pose。其预测时间与图片中人的数量成比例。如下图所示,openpose不随图片中人的数量增加,而预测时间增加。

openpose的预测时间包括两部分,1)CNN的处理时间,其与人的时间复杂度是O(1),即恒定,和人数量无关;2)多人解析时间,其时间复杂度为O(n的2次方),但是其时间占比与第一个相比很小。例如,对于9人,CNN花了36毫秒,多人解析花了0.58毫秒。
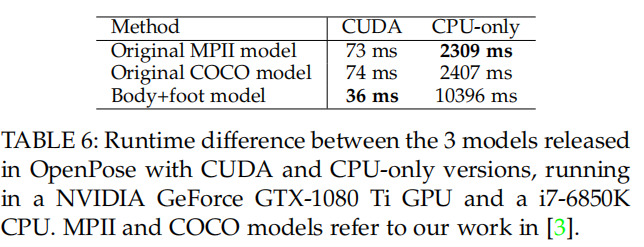
openpose不同模型运行时间:
4.4 车辆姿体检测
如下图,效果不错。

4.5 失败案例
当然也有检测失败的情况,如下图,比如当出现稀有的姿体、雕塑等情况,检测不正确。
