常见的数据结构
散列表(哈希表)
散列表(也称哈希表)是根据关键码值(Key value)而直接进行访问的数据结构,它让码值经过哈希函数的转换映射到散列表对应的位置上,查找效率非常高。
哈希索引主要用于memory引擎中
1、针对哈希索引,只有精确匹配索引所有列的查询才有效,比如在列(A,B)上建立了哈希索引,如果只查询数据列 A,则无法使用该索引
2、哈希索引并不是按照索引值顺序存存储的,所以也就无法用于排序,也就是说无法根据区间快速查找
3、哈希索引只包含哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行,不过,由于哈希索引多数是在内存中完成的,大部分情况下这一点不是问题
4、哈希索引只支持等值比较查询,包括 =,IN(),不支持任何范围的查找,如 age > 17
链表
双向链表支持顺序查找和逆序查找,索引是按照大小顺序进行存储的
什么是跳表?简单地说,跳表是在链表之上加上多层索引构成的。

跳表是能满足需求的,实际上它的结构已经和B+树非常接近了,只不过B+树是从平衡二叉查找树演化而来的而已
二叉查找树
图中的圆为二叉查找树的节点,节点中存储了键key和数据data。键对应user表中的id,数据对应user 表中的行数据。
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。顶端的节点称为根节点,没有子节点的节点称之为叶节点。
平衡二叉树
平衡二叉树又称 AVL 树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过 1
平衡二叉树保证了树的构造是平衡的,当插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
B-树
因为内存的易失性。一般情况下都会选择将user表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以应当尽量减少从磁盘中读取数据的次数。另外从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。如果能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那查找数据的时间也会大幅度降低。
如果用树这种数据结构作为索引的数据结构,那每查找一次数据就需要从磁盘中读取一个节点,也就是说的一个磁盘块。
二叉树的节点将会非常多,高度也会极其高,查找数据时也会进行很多次磁盘 IO,查找数据的效率将会极低
B 树相对于平衡二叉树,每个节点存储了更多的键值key和数据data,并且每个节点拥有更多的子节点,子节点的个数一般称为阶,例如B树为3阶B树,高度也会很低。基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
在BTree的机构下,就可以使用二分查找的查找方式,查找复杂度为【层高*log(结点数)】,一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构
B树的一些特点:
关键字集合分布在整颗树中
任何一个关键字出现且只出现在一个结点中
搜索有可能在非叶子结点结束
其搜索性能等价于在关键字全集内做一次二分查找
B树在插入删除新的数据记录会破坏B-Tree的性质,因为在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质
B+树
主要区别就是所有的节点值都在最后叶节点上用双向链表连接在了一起
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rxcCgpHa-1616665918339)(file:///C:/Users/21288/AppData/Local/Temp/msohtmlclip1/01/clip_image004.jpg)]](https://img-blog.csdnimg.cn/20210325175637459.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0xlY2hlbmdf,size_16,color_FFFFFF,t_70)
但是二叉树不能使用,因为比对次数太多,所以使用多叉树以减少比对次数
B+Tree中的非叶子结点不存储数据,只存储键值,非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应data数据的物理地址
B+Tree的每个非叶子节点由n个键值key和n个指针point组成
B+Tree对比B-Tree
磁盘读写代价更低:每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
查询速度更稳定。由于B+Tree非叶子节点不存储数据data,因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。
B+树的查找过程,与B树类似,只不过查找时,如果在非叶子节点上的关键字等于给定值,并不终止,而是继续沿着指针直到叶子节点位置。因此在B+树,不管查找成功与否,每次查找都是走了一条从根到叶子节点的路径。
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
数据库设计
数据库设计通常分为 6 个阶段: 主要在软件开发的概要设计阶段完成
1、需求分析:分析用户的需求,包括数据、功能和性能需求;依据是软件开发中的需求分析阶段的里程碑—需求说明书
2、概念结构设计:主要采用 E-R 模型进行设计,包括画 E-R 图;
在需求中查找名词,并且进行分类—-定义模式
学生(姓名、年龄、班级、家庭关系、…)
课程(课程编号、名称、…)
学生可以进行选课
使用软件绘制对应的 ER 图,用于说明结构设计—-用于沟通
Sybase 公司的 PowerDesigner:绘制 ER 图(不是标准 ER 图)、可以
根据 ER 图生成对应的建表语句、可以自动生成对应的测试数据、同时支持反向工程
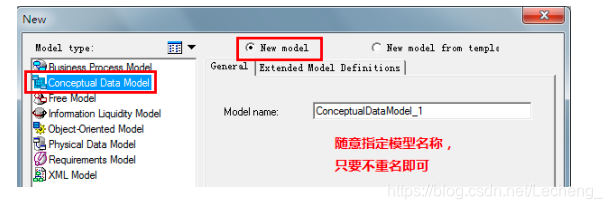
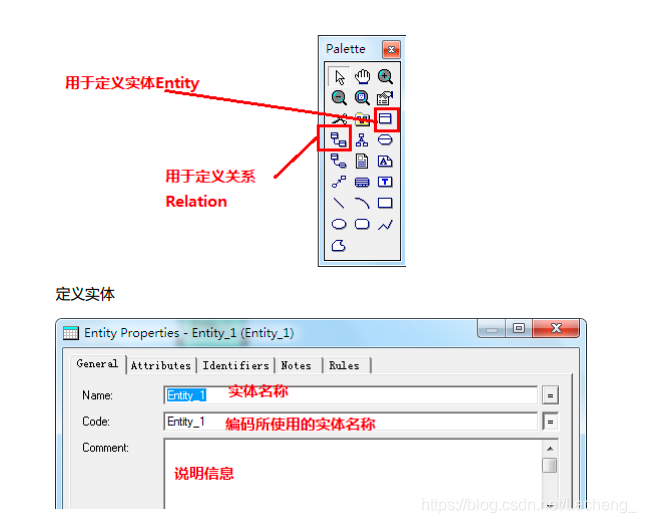
3、逻辑结构设计:通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换;
数据库选型: MySQL Oracle db2 SQLServer
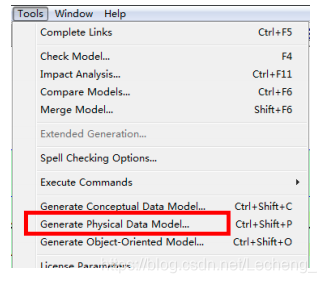
数据库选型:
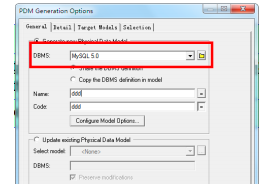
注意:物理数据模型中则会出现主外键
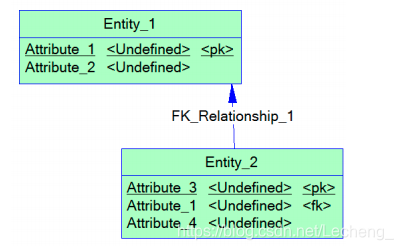
4、数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径;针对开发人员而言,具体的数据存放是透明的。但是作为运维管理人员则需要针对物理存放进行规划
5、数据库的实施:包括编程、测试和试运行;
/*=============================================================
=*/
drop table if exists Entity_1;
drop table if exists Entity_2;
/*===========================================================*/
/* Table: Entity_1 */
/*==========================================================*/
create table Entity_1
(
Attribute_1 char(10) not null,
Attribute_2 char(10),
primary key (Attribute_1)
);
/*===========================================================*/
/* Table: Entity_2 */
/*===========================================================*/
create table Entity_2
(
Attribute_3 char(10) not null,
Attribute_1 char(10),
Attribute_4 char(10),
primary key (Attribute_3)
);
alter table Entity_2 add constraint FK_Relationship_1 foreign key (Attribute_1)
references Entity_1 (Attribute_1) on delete restrict on update restrict
生成测试数据对应的 sql 文件
6、数据库运行与维护:系统的运行与数据库的日常维护。
数据库设计的方法:
试凑法:完全依赖于 DBA 的工作经验
规范化法: 范式和反范式
CAD 法
规范化法:
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。一般数据库设计中最多采用的是 3NF。如果不满足某个范式则采用分表的方式解决。
1NF: 列不可分原则
2NF:不允许部分依赖
3NF:不允许传递依赖
数据库设计实例:学生管理系统
系 dept(编号,名称)
班级 clz(班级编号,班级名称,自修教室)
系和班级:1:n
概念数据模型

考虑数据选型:在具体的开发中一般不会涉及层次和网状模型
MySQL:一般互联网企业或者中小型应用首选,因为社区版免费
Oracle:一般用于大中型应用开发中,是企业级开发的首选,价格昂贵
DB2:一般用于使用了 IBM 中间件的应用开发中,可以用于大中型应用
根据 ER 图【不是标准 ER 图】生成物理数据模型

根据物理数据模型可以生成对应建表的 SQL 语句
/*=========================================================*/
drop table if exists t_clz;
drop table if exists t_dept;
/*===========================================================*/
/* Table: t_clz */
/*===========================================================*/
create table t_clz
(
clz_id bigint not null,
dept_id bigint,
clz_name varchar(32) not null,
clz_room varchar(20),
primary key (clz_id)
);
/*==========================================================*/
/* Table: t_dept *//*=============================================================
=*/
create table t_dept
(
dept_id bigint not null,
dname varchar(32) not null,
primary key (dept_id)
);
alter table t_clz add constraint FK_包含 foreign key (dept_id)
references t_dept (dept_id) on delete restrict on update restrict;