缘起
生产环境服务A部署在K8s上,某天运维告诉我这个服务经常会重启,客户没有报告是因为我们是滚动发布更新,先启动这个服务的一个新实例,然后将旧实例Kill掉,这样前端是无感知的,但重启是实实在在存在的,生产问题不可马虎,于是开启了定位问题之旅。
过程
定位问题前前后后一共花了快一个月,过程如下:
-
服务是Java写成的,监控有Prometheus和ARMS(阿里商业监控),Prometheus只能看到CPU和内存用量,我也看了Prometheus监控,内存大致如下:

CPU大致如下:
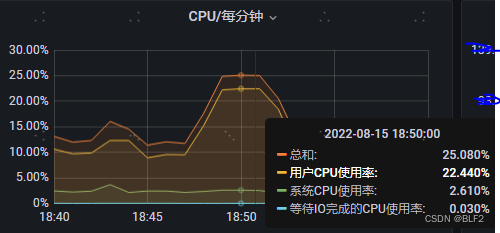
还有GC等指标,其实不用看了,大概就是老年代满了,没内存了,但是日志里没有OOM错误,这是为什么?原因是部署在K8s,在OOM之前 health check的响应时长过长,K8s认为服务挂了,就启动了个新实例,将旧实例Kill掉。 - 看此段时间内的请求,某个接口请求比较频繁,于是猜测这个接口频繁调用会导致服务重启,但猜测毕竟是猜测,要去验证的。于是在UAT环境进行验证,但是由于UAT数据量级和PRD量级差距过大,只是发现UAT内存增加了,并未出现和生产环境一样的现象——healthcheck导致服务重启。又去请求DBA同学导一下生产数据往UAT库,但被Security团队拒绝了。这下没法在UAT测试和验证了,于是主意又打到PRD环境,和领导聊过之后,终于在某个周五晚上(因为是内部系统,周五客户下班后,这个系统基本没人使用),疯狂调用上面发现的接口,将服务搞挂了,监控和上面一致,复现了这个问题,确定是这个接口导致的。
- 确定了是这个接口导致的,只能知道把内存打满了,但不知道因为内部逻辑的哪一块导致的,从代码角度看的话不容易看出来,而且看出来也没有直接的证据证明确实是这段代码,没法给领导汇报,于是考虑将出现这个问题时的内存dump一下。首先考虑到的是使用aliyun的ARMS进行dump,我让同事请求这个接口,然后我就看着监控,内存上去后就手动点Dump按钮,采集了几次打开感觉都不对,内存没有任何异常,而且吐槽一下,ARMS的Dump这个功能,一分钟之内只能点一次,实际把握不好,真的采集不到合适的数据。试了几次后就放弃了,于是考虑新的方案。
-
新的方案就是我们在K8s容器将要被Kill的时候执行
jmap
,
jstack
等命令,实施前才想到,我们用的基础镜像是包含jre的,不包含jdk,根本不支持
jmap
,
jstack
等命令,然后找运维去帮忙换成JDK的基础镜像,被拒绝了,只能自立更生了,在网上看到了
Jattch
这个东西,于是在SIT环境测试了下,居然真可以用,详情可参见 我的另一篇文章
Docker容器只有JRE没有JDK使用Jattach导出内存快照
最终使用到的脚本是
#!/bin/sh
# 导出当前内存信息
jattach 1 dumpheap /opt/dump/dumpheap_"$HOSTNAME"_`date +%Y%m%d-%H%M%S`.hprof
# 导出当前线程信息
for i in `seq 3`
do
jattach 1 threaddump > /opt/dump/threaddump_"$HOSTNAME"_`date +%Y%m%d-%H%M%S`.log && sleep 1
done
# 导出当前使用CPU最高的线程
top -H -p 1 -n 3 -c -b > /opt/dump/cpudump_"$HOSTNAME"_`date +%Y%m%d-%H%M%S`.log
- 导出文件的目录让运维挂载到了一个网络硬盘上,然后拿下来就可以分析了,期间一共导下来4个dump文件,其中3个事损坏的,个人猜测应该是没有导出完成,容器就被Kill了,我们优雅退出的等待时间是30秒
结果
那么我们来分析下唯一可以打开的这个文件,使用MAT(MemoryAnalyzer Tool)
载入后如下:
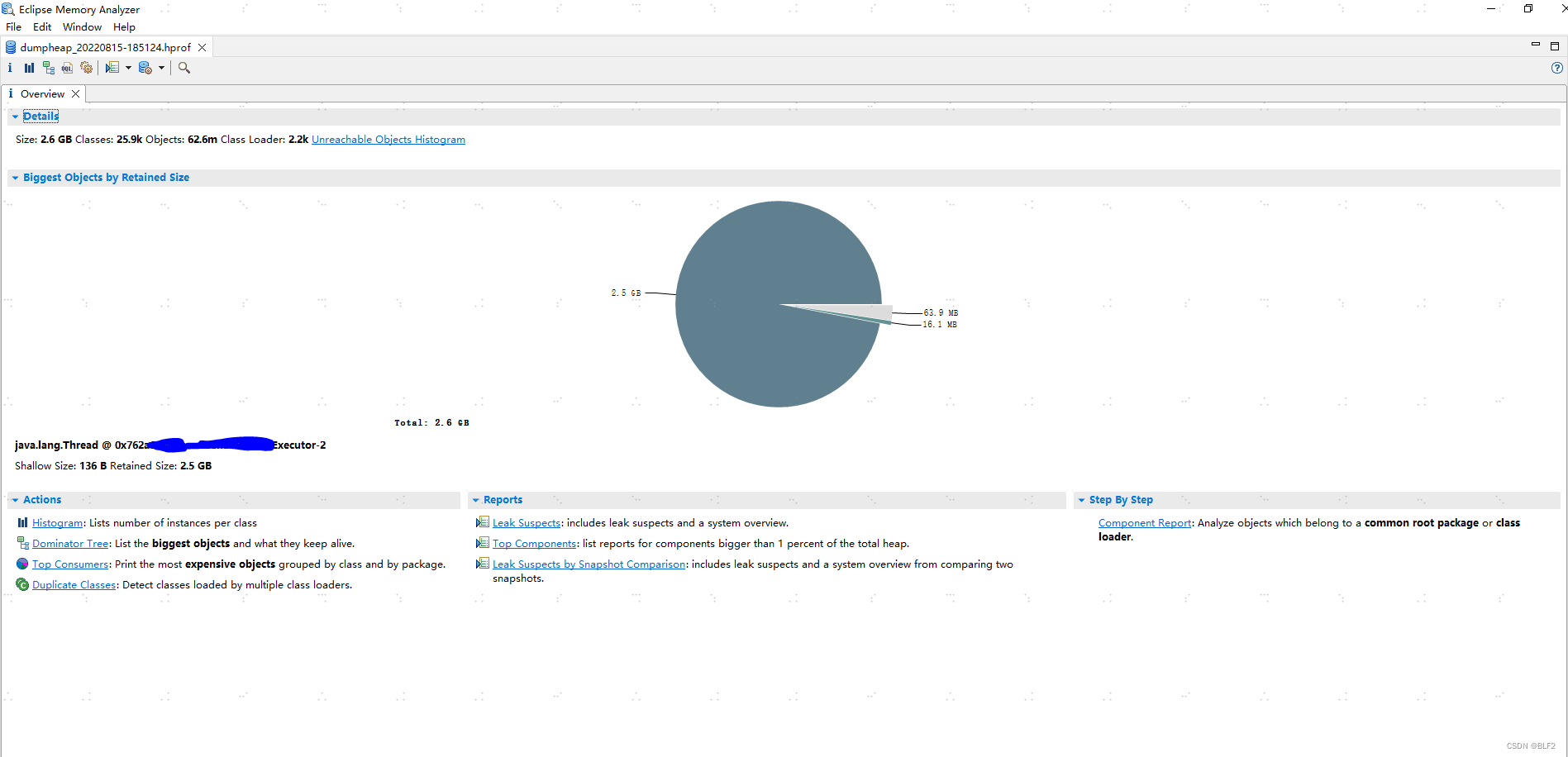
可以明显看出有个线程池的某个线程居然内存占用达到2.5G,结合上面Prometheus的老年代一共2.6G可以得知是这个线程把内存吃满了,到底是哪个呢?点击
Reports
下的
Leak Suspects
,可以看到:
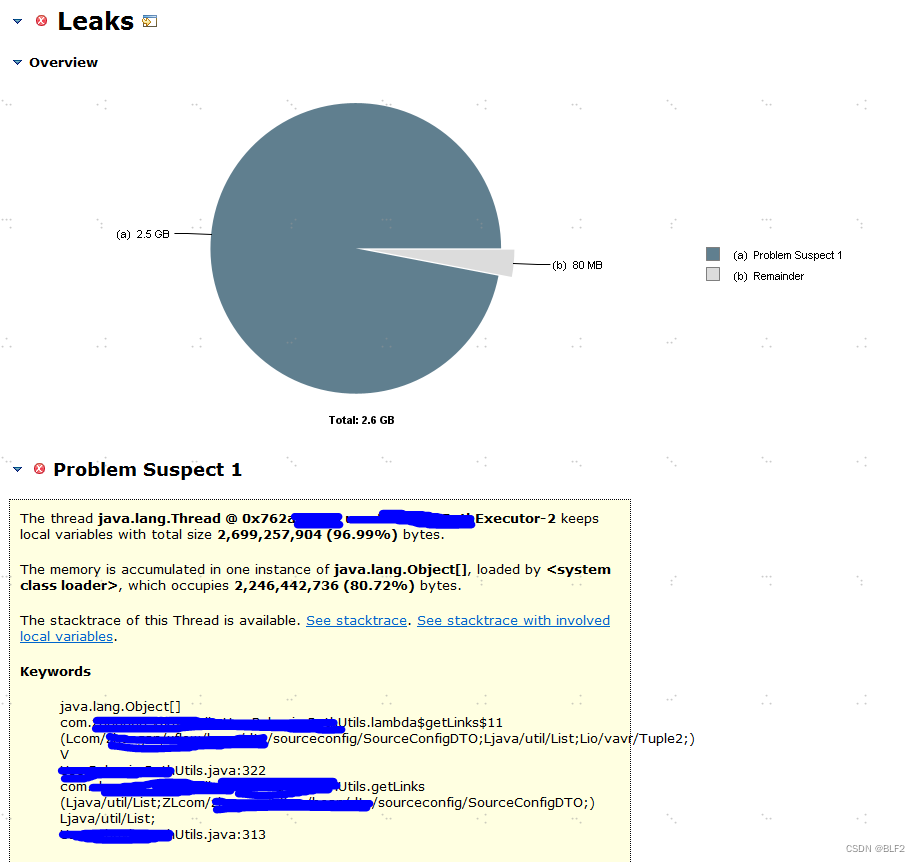
看到这里就比较清楚了,下面有方法的调用栈,如果看详细的,可以点
See stacktrace
查看详细调用栈。
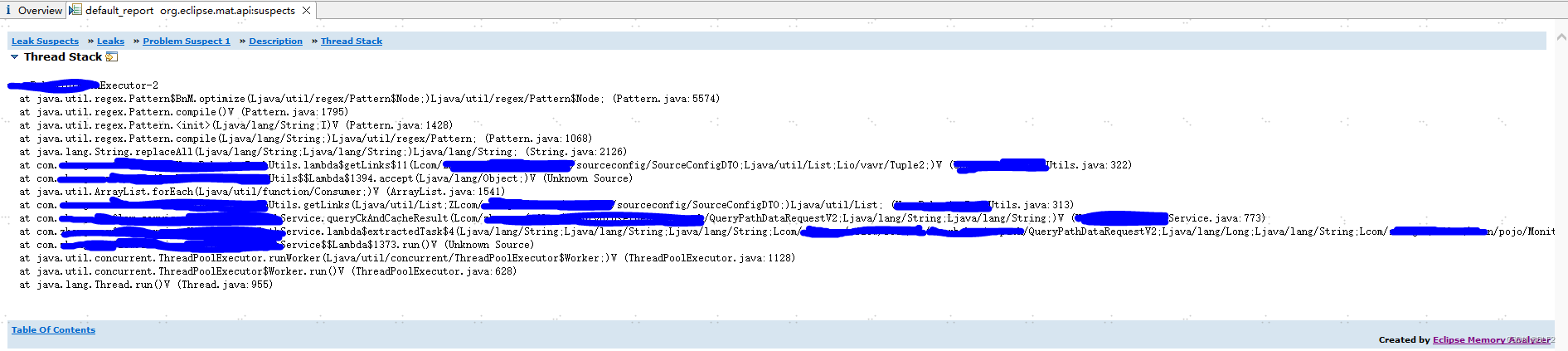
至此,问题定位到,剩下的就是去看逻辑,优化代码了。
版权声明:本文为u013014691原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。