贝叶斯网是一种帮助人们将概率统计应用于复杂领域,进行不确定性推理和数据分析的工具。他起源于人工智能领域的研究。贝叶斯网是一种系统地描述随机变量之间关系的语言。构造贝叶斯网的主要目的是进行概率推理,即计算一些事件发生的概率。贝叶斯网是概率论与图论相结合的产物,它一方面用图论的语言直观的揭示问题结构,另一方面又按照概率论的原则对问题结构加以利用,降低推理的计算复杂度。
贝叶斯网络的构造主要有两种方式:第一种是通过咨询专家手工构造;第二种是通过数据分析获得(讨论利用机器学习的方法分析数据获得贝叶斯,即贝叶斯学习)。贝叶斯网络的构造主要包括两个方面:确定网络结构与评估条件概率。
推理是通过计算回答查询的过程。贝叶斯网的推理问题有三大类:后验概率问题、最大后验假设问题以及最大可能解释问题。其中主要解决的推理问题是后验概率问题。后验概率问题指的是已知贝叶斯网络中某些变量的取值,计算另外一些变量的后验概率分布问题。主要有以下四种类型:第一种是从结果到原因的诊断推理;第二种是从原因到结果的预测推理;第三种是同一结果的不同原因之间的原因关联推理。
(以上知识概述一下什么是贝叶斯网、贝叶斯推理以及贝叶斯学习的概念,未涉及其中重要的算法,如:变量消元法、团树传播算法、随机抽样算法、EM算法、爬山算法等)
以下来举一个具体实践的例子说明贝叶斯网的构造。
为提高诊断水平,研发人员开发了一个叫做PATHFINDER的专家系统.这个贝叶斯网由开发人员和医疗专家一起手工建造的,确定变量及取值用了8h,确定网络拓扑结构用了35h,对总共14000个条件概率值的评估有用了40h,最终的到了一个由121个节点、195条边构成的网络。用PATHFINDER做推理问题,即给定症状变量的取值,计算疾病变量的后验分布,然后把后验概率最大的那个疾病作为诊断结果。系统测试使用了53个淋巴腺疾病的病例,结果显示,预测准确度达到中等医师的水平。
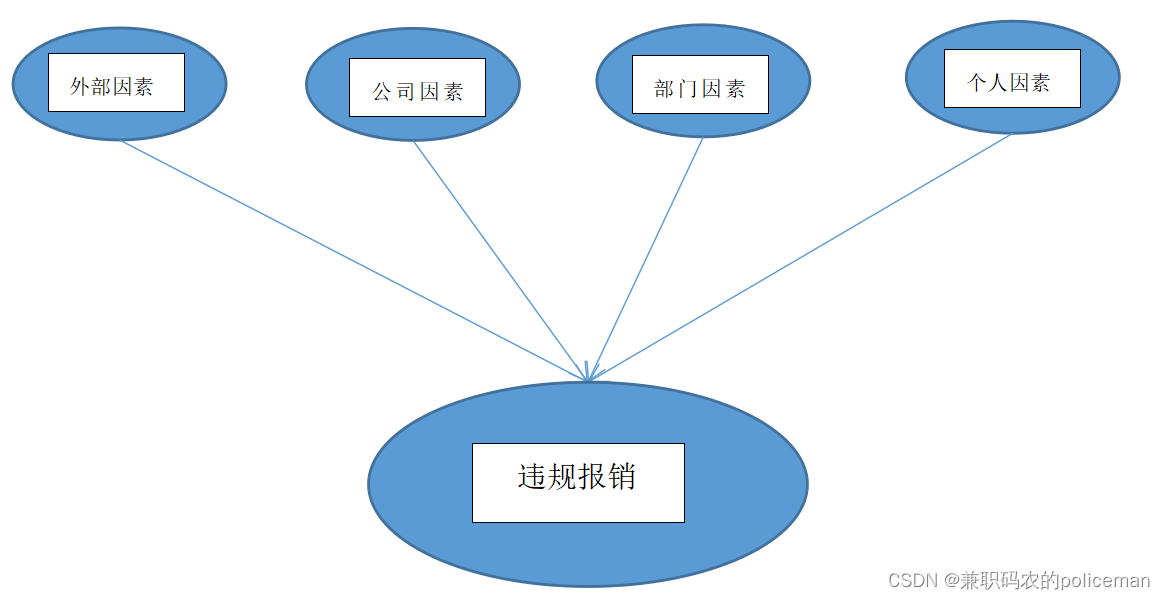
现将最近跟随老师做的有关违规报销预测的项目做的大框架(由于保密原因未能对每一个节点做展示)贴在此博客上。
from pgmpy.models import BayesianModel
from pgmpy.factors.discrete import TabularCPD
from pgmpy.inference import VariableElimination
import pandas as pd
#建立模型
model = BayesianModel([
('外部因素', '违规报销'),
('公司因素', '违规报销'),
('部门因素', '违规报销'),
('个人因素', '违规报销')])
#定义条件概率分布
# variable:变量
# variable_card:基数
# values:变量值
# evidence:依据
# evidence_card:依据基数
cpd_A = TabularCPD(variable='外部因素',
variable_card=2,
values=[[0.8],[0.2]])
cpd_B = TabularCPD(variable='公司因素',
variable_card=2,
values=[[0.95],[0.05]])
cpd_C = TabularCPD(variable='部门因素',
variable_card=2,
values=[[0.9], [0.1]])
cpd_D = TabularCPD(variable='个人因素',
variable_card=2,
values=[[0.85], [0.15]])
cpd_W = TabularCPD(variable='违规报销',
variable_card=2,
values=[[0.8,0.6,0.65,0.3,0.7,0.35,0.2,0.15,0.73,0.40,0.33,0.17,0.41,0.14,0.12,0.05],
[0.2,0.4,0.35,0.7,0.3,0.65,0.8,0.85,0.27,0.60,0.67,0.83,0.59,0.86,0.88,0.95]],
evidence=['外部因素','公司因素','部门因素','个人因素'],
evidence_card=[2,2,2,2])
# 将有向无环图与条件概率分布表关联
model.add_cpds(cpd_A,cpd_B,cpd_C,cpd_D,cpd_W)
# 验证模型:检查网络结构和CPD,并验证CPD是否正确定义和总和为1 CPD:概率图模型
model.check_model()
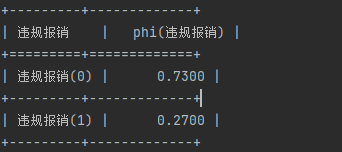
#获取结点“违规报销”的概率表:
print(model.get_cpds("违规报销"))
#获取结点“违规报销”的基数:
print (model.get_cardinality('违规报销'))
#获取整个贝叶斯网络的局部依赖:
print(model.local_independencies(['外部因素','公司因素','部门因素','个人因素','违规报销']))
#推测“违规报销”的节点概率,在pgmpy中我们只需要省略额外参数即可计算出条件分布概率
infer = VariableElimination(model)
print(infer.query(['违规报销'], evidence={'外部因素':1,'公司因素':0,'部门因素':0,'个人因素':0}))