介绍
经常会有人问profile工具该怎么使用?有没有方法获取性能差的sql的问题。自从转mysql我自己也差不多2年没有使用profile,忽然profile变得有点生疏不得不重新熟悉一下。这篇文章主要对profile工具做一个详细的介绍;包括工具的用途和使用方法等。profile是SQLServer自带的一个性能分析监控工具,它也可以生成数据库引擎优化顾问分析需要的负载数据,比如开发对功能进行调试需要收集执行sql使用profile就是一个非常好的办法,profile主要用于在线实时监控和收集数据用于后期的分析使用,它可以将收集的数据保存成文件和插入到表。
跟踪属性
一、常规
将跟踪的记录保存到指定的文件。
1.最大文件大小
指定最大文件大小的跟踪在达到最大文件大小时,会停止将跟踪信息保存到该文件。使用此选项可将事件分组成更小、更容易管理的文件。此外,限制文件大小使得无人参与的跟踪运行起来更加安全,因为跟踪会在达到最大文件大小后停止。可以为通过 Transact-SQL 存储过程或使用 SQL Server Profiler创建的跟踪设置最大文件大小。
最大文件大小选项的上限为 1 GB。默认最大文件大小为 5 MB
注意:最大文件的大小建议不要设的太大,特别是需要用于数据库引擎优化顾问使用的文件,太大的跟踪文件需要很长的分析的时间而且由于数据库引擎优化顾问也是把收集的负载文件执行一遍有时候可能会导致负载过大分析失败,同时对服务器的压力持续的时间过长对业务影响也会比较大,默认大小即可,同时启动文件滚动更新,多次分析。
2.启用文件滚动更新
如果使用文件滚动更新选项,则在达到最大文件大小时,SQL Server 会关闭当前文件并创建一个新文件。新文件与原文件同名,但是文件名后将追加一个整数以表示其序列。例如,如果原始跟踪文件命名为 filename_1.trc,则下一跟踪文件为 filename_2.trc,依此类推。如果指定给新滚动更新文件的名称已经被现有文件使用,则将覆盖现有文件,除非现有文件为只读文件。默认情况下,将跟踪数据保存到文件时,会启用文件滚动更新选项。
3.服务器处理跟踪数据
确保服务器记录每个跟踪事件,如果记录事件会显著降低性能,可以清除服务器处理跟踪数据,这样服务器不会再记录事件。
4.最大行数
指定有最大行数的跟踪在达到最大行数时,会停止将跟踪信息保存到表。每个事件构成一行,因此该参数可设置收集的事件数的范围。设置最大行数使得无人参与的跟踪运行起来更加方便。例如,如果需要启动一个将跟踪数据保存到表的跟踪,同时希望在该表变得过大时停止跟踪,则可以使其自动停止。
如果已指定并且达到了最大行数,将在运行 SQL Server Profiler的同时继续运行跟踪,但不再记录跟踪信息。SQL Server Profiler将继续显示跟踪结果,直到跟踪停止
5.启用跟踪停止时间
启用跟踪停止时间之后,到了指定的时间跟踪自动停止。每一次跟踪建议都必须得设置一个跟踪停止时间防止忘记关闭跟踪导致服务器空间被占满,默认跟踪1小时。
注意:
- 从 SQL Server 2005 开始,服务器以微秒(百万分之一秒或 10-6 秒)为单位报告事件的持续时间,以毫秒(千分之一秒或 10-3 秒)为单位报告事件使用的 CPU 时间。
- 在 SQL Server 2000 中,服务器以毫秒为单位报告持续时间和 CPU 时间。
-
在 SQL Server 2005 及更高版本中,SQL Server Profiler图形用户界面默认以毫秒为单位显示
“持续时间”
列,但是当跟踪保存到文件或数据库表中之后,将以微秒为单位在
“持续时间”
列中写入值。
二、事件选择
对于不同跟踪选择不同的跟踪事件;通过勾选“显示所有跟踪事件”可以看到所有的跟踪事件,总共有21个事件分类。用得最多的两个分类就是存储过程和TSQL这两个分类主要用来记录执行的存储过程和SQL语句,把鼠标移动到具体的事件上面会显示该事件和事件列的具体说明,接下来就分析几个常用的事件和常用的事件列。
1.显示所有跟踪事件
勾选之后会将所有的事件都显示出来
2.显示所有列
勾选之后会将所有的列显示出来
3.列筛选
对列增加一些条件,其实可以将它理解在TSQL语句的WHERE后面添加条件,对于整形列直接输入数值即可,对于字符串列就相当于like一样使用不带引号的%%模糊匹配方法。通过勾选“排除不包含值的行”之后跟踪结果就会筛选掉不满足条件的记录。
4.列组织
列组织可以理解成TSQL语句里面做GROUP BY操作,可以将相同的条件放在一起去重。
事件
1.SQL:Stmt*******
[SQL:StmtStarting]:启动TSQL语句时记录
[SQL:StmtCompleted]:完成TSQL语句时记录

这两事件的区别也同单词的意思一样,StmtStarting是记录事件的开始不关注这个事件在接下来会做什么,StmtCompleted是记录事件结束之后在开始和结束这个过程中做的一些操作比如一些常用的列”Duration”,”Cpu”,”Reads”,”Writes”,”EndTime”这些列就会出现在StmtCompleted事件中。所以如果你需要收集的记录不关心整个事件过程中的操作只需要收集数量那么可以使用Starting事件比如记录某个语句或者存储过程执行的次数等。
2.SQL:Batch******
[SQL:BatchStarting]:启动TSQL批处理时记录
[SQL:BatchCompleted]:完成TSQL批处理时记录
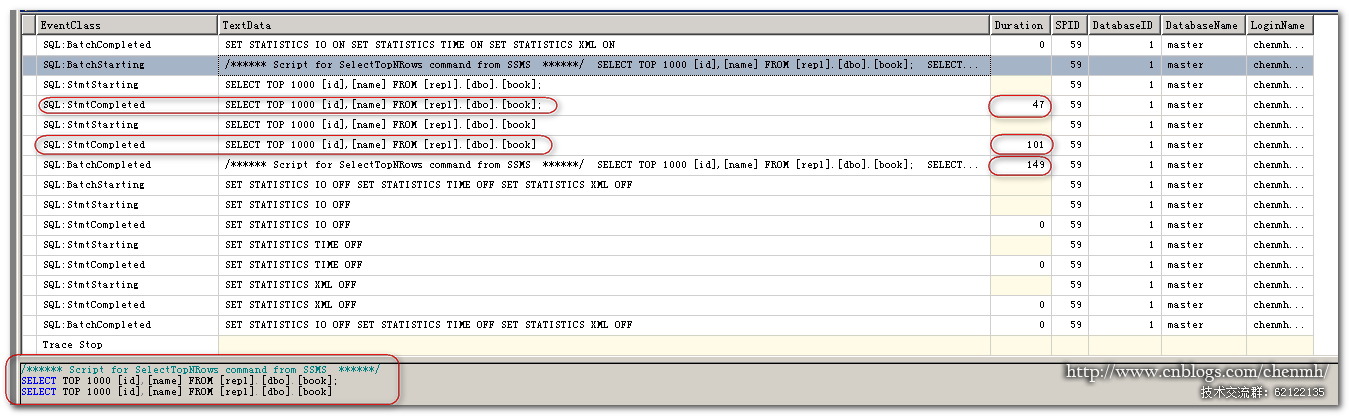

这次我把两个select语句放在一起来执行,可以从batch事件中可以看到它记录的整个批处理的SQL同时还包括相关注释,同时整个批处理两个TSQL作为一条事件记录,而stmt事件记录具体的TSQL语句把两个TSQL语句作为两条记录来记录。同时还可以发现两个TSQL的Duration相加是小于整个批处理的duration的,这也是正常的整个批处理在sql编译分析执行这块肯定比单个TSQL需要耗费更多的时间,但是相差也是非常的小。
batchcompleted事件多用于引擎优化顾问,而stmtcompleted事用于分析单个TSQL语句。同样Stored分类里面的starting事件和completed事件和TSQL里面的是一样的意思。
事件列
列举常用的事件列
TextData:
文本详细信息,比如详细的执行SQL语句等等。
ApplicationName
:连接SQLSever的客户端应用程序名称。
NTUserName
:windows用户名
LoginName
:SQLServer登入用户名。
CPU
:事件占用的CPU时间,在图形化界面但是是毫秒(千分之一秒或 10-3 秒),在文本文件或者数据库表中单位是微妙(百万分之一秒或 10-6 秒)。
Reads
:执行逻辑读的次数。
Writes
:物理磁盘写入的次数。
Duration
:事件的持续时间,也就是统计信息里面显示的占用时间,在图形化界面但是是毫秒(千分之一秒或 10-3 秒),在文本文件或者数据库表中单位是微妙(百万分之一秒或 10-6 秒)
ClientProcessID
:调用SQLServer的应用程序进程ID。
SPID
:SQLServer为连接分配的数据库进程ID,也就是sys.processes里面记录的进程ID。
StartTime
:事件的开始时间。
EndTime
:事件的结束时间。
DBUserName
:客户端的sqlserver用户名。
DatabaseID
:如果指定了USE database就是指定的数据库id,否则就是默认的数据库id(也就是master的数据库id)。所以该列的作用不是很大。
Error
:事件的错误号,通常是sysmessage中存储的错误号。
ObjectName
:正在引用的对象名称。
三、自带跟踪模板
工具自带了几个比较实用的跟踪模板,一般的跟踪都可以直接使用自带的跟踪模板解决,同时自己也可以创建自定义的跟踪事件和跟踪属性保存成模板供以后使用。
SP_Counts
:计算已运行的存储过程数,并且按存储过程的名称进行分组统计,此模板可以分析某时间段存储过程的行为。
Standard
:记录所有存储过程和T-SQL语句批处理运行的时间,当你想要监视常规数据库服务器活动时即可使用该模板,一般的跟踪需要使用该模板就可以解决,这也是默认的模板。
TSQL:
记录客户端提交给sqlserver的所有T-SQL语句的的内容和开始时间,通常使用该模板用于程序调试。
TSQL_Duration
:记录客户端提交给sqlserver的所有T-SQL语句批处理信息以及执行这些语句所需的时间(毫秒),并按时间进行分组,使用该模板可以分析执行慢的查询,此模板的跟踪记录可以用于数据库引擎优化顾问分析使用。
TSQL_Grouped
:按提交客户端和登入用户进行分组记录所有提交给SQLServer的T-SQL批处理语句及其开始时间,此模板用于分析某个客户或者用户执行的查询。
TSQL_Locks
:记录所有开始和完成的存储过程和T-SQL语句,同时记录死锁信息,此模板用于跟踪死锁。
TSQL_Replay
:记录有关已发出的T-SQL语句的详细信息,此模板记录重播跟踪所需的信息,此模板可执行跌到优化,例如基准测试。
TSQL_SPs
:记录有关执行的所有存储过程的详细信息,此模板可以分析存储过程的组成步骤。如果你怀疑正在重新编译存储过程,请添加SP:Recomple事件
Tuning
:记录有关存储和T-SQL语句批处理的信息以及执行这些语句所需的时间(毫秒),使用此模板生产跟踪输出可用于数据库引擎优化顾问工作负载来优化索引、优化性能。此模板和TSQL_Druation相似后者是做了时间分组。
数据库引擎优化顾问
1.如果需要用数据库引擎优化顾问分析跟踪事件记录必须捕获了以下跟踪事件:
-
RPC:Completed
-
SQL:BatchCompleted
-
SP:StmtCompleted
也可以使用这些跟踪事件的 Starting 版本。 例如,SQL:BatchStarting。 但是,这些跟踪事件的 Completed 版本包括 Duration 列,它能使数据库引擎优化顾问更有效地优化工作负荷。 数据库引擎优化顾问不优化其他类型的跟踪事件。
2.包含 LoginName列
数据库引擎优化顾问在优化过程中提交显示计划请求。 当包含 LoginName 数据列的跟踪表或跟踪文件被用作工作负荷时,数据库引擎优化顾问将模拟 LoginName 中指定的用户。 如果没有为此用户授予 SHOWPLAN 权限(该权限使用户能够为跟踪中包含的语句执行和生成显示计划),数据库引擎优化顾问将不会优化这些语句。
避免为跟踪的 LoginName 列中指定的每个用户授予 SHOWPLAN 权限
-
通过从未优化的事件中删除 LoginName 列来创建新的工作负荷,然后只将未优化的事件保存到新的跟踪文件或跟踪表中。
-
将不带 LoginName 列的新工作负荷重新提交到数据库引擎优化顾问。
数据库引擎优化顾问将优化新的工作负荷,因为跟踪中未指定登录信息。 如果某个语句没有相应的 LoginName,数据库引擎优化顾问将通过模拟启动优化会话的用户(sysadmin 固定服务器角色或 db_owner 固定数据库角色的成员)来优化该语句。
3.数据库引擎优化顾问不能执行下列操作:
-
建议对系统表建立索引。
-
添加或删除唯一索引或强制 PRIMARY KEY 或 UNIQUE 约束的索引。
- 优化单用户数据库。
4.数据库引擎优化顾问具有下列限制:
-
数据库引擎优化顾问通过数据采样收集统计信息。因此,在相同的工作负荷上重复运行该工具可能生成不同的结果。
-
数据库引擎优化顾问不能用于优化 Microsoft SQL Server 7.0 或更早版本的数据库中的索引。
-
如果为优化建议指定的最大磁盘空间超过了可用空间,数据库引擎优化顾问将使用指定的值。但是,当您执行建议脚本来实施它时,如果未先添加更多磁盘空间,则脚本会失败。可以使用
dta
实用工具的
-B
选项指定最大磁盘空间,也可以通过在
“高级优化选项”
对话框中输入值来指定最大磁盘空间。
-
为了安全起见,数据库引擎优化顾问不能优化驻留在远程服务器上的跟踪表中的工作负荷。若要解除此限制,可以选择以下选项之一:
-
使用跟踪文件而不使用跟踪表。
-
将跟踪表复制到远程服务器。
-
使用跟踪文件而不使用跟踪表。
-
当强制实施约束时,例如为优化建议指定最大磁盘空间时强制的约束(通过使用
-B
选项或
“高级优化选项”
对话框),数据库引擎优化顾问可能会被迫删除某些现有的索引。在此情况下,生成的数据库引擎优化顾问建议可能生成负的预期提高值。
-
指定限制优化时间的约束时(通过使用
dta
实用工具的
-A
选项或通过选择
“优化选项”
选项卡上的
“限制优化时间”
),数据库引擎优化顾问可能超过该时间限制,以便针对到当时为止已处理的工作负荷,生成精确预期的提高值和分析报告。
5.数据库引擎优化顾问可能在下列情况下不提供建议:
-
正在优化的表所包含的数据页数少于 10。
-
建议的索引对当前物理数据库设计的查询性能预计带来的提高值不够。
-
运行数据库引擎优化顾问的用户不是
db_owner
数据库角色或
sysadmin
固定服务器角色的成员。工作负荷中的查询在运行数据库引擎优化顾问的用户的安全上下文中进行分析。该用户必须是
db_owner
数据库角色的成员。
6.数据库引擎优化顾问可能在下列情况下不提供分区建议:
-
未启用
xp_msver
扩展存储过程。此扩展存储过程用于提取要优化的数据库所在服务器上的处理器数目以及可用内存。请注意,安装 SQL Server 后,默认情况下,此扩展存储过程处于打开状态。有关详细信息,请参阅了解外围应用配置器和 xp_msver (Transact-SQL)。
7.性能注意事项
在分析过程中,数据库引擎优化顾问可能占用相当多的处理器及内存资源。若要避免降低生产服务器速度,请采用下列策略之一:
-
在服务器空闲时优化数据库。数据库引擎优化顾问可能影响维护任务性能。
-
使用测试服务器/生产服务器功能。有关详细信息,请参阅减轻生产服务器优化负荷。
- 指定数据库引擎优化顾问仅分析物理数据库设计结构。数据库引擎优化顾问提供许多选项,但是请仅指定所需选项。
注意:由于数据库引擎优化顾问进行性能优化时也是将负载记录中的语句执行一篇查询分析执行计划的操作,所以对服务器同样存在压力。特别是对于大的负载分析可能需要分析一个小时甚至更长,这样可能会持续对服务器造成压力,所以避免在业务高峰期进行使用引擎优化顾问进行负载分析。
实例
接下来就列举三个案例,使用数据库引擎优化顾问来分析跟踪记录优化索引的案例、监控死锁的案例、创建自定义跟踪模板案例。
案例1:优化索引
1.创建测试数据


--创建测试表
CREATE TABLE [dbo].[book](
[id] [int] NOT NULL PRIMARY KEY,
[name] [varchar](50) NULL);
--插入10W条测试数据
DECLARE @id int
SET @id=1
WHILE @id<100000
BEGIN
INSERT INTO book values(@id,CONVERT(varchar(20),@id))
SET @id=@id+1
END;


2.创建跟踪
这里使用默认的跟踪模板“tuning”
1.创建好跟踪后点击运行即可,事件选择这里保持默认

2.执行SQL
SELECT * FROM book WHERE name='10001';
由于name字段没有建索引所以该查询执行计划分析过后会返回创建name字段的索引,通过引擎优化顾问分析同样如此
3.停止跟踪
在使用数据库引擎优化顾问分析负载跟踪之前必须先停止跟踪。
4.打开数据库引擎优化顾问
可以直接在profile的工具栏选择打开,“文件”选择刚才的跟踪文件,“负载数据库”选择需要进行优化的数据库,“选择要优化的数据库和表”也就需要优化的数据库的相关表。优化选项没有特别的需求选择默认即可,然后点击“开始分析”。
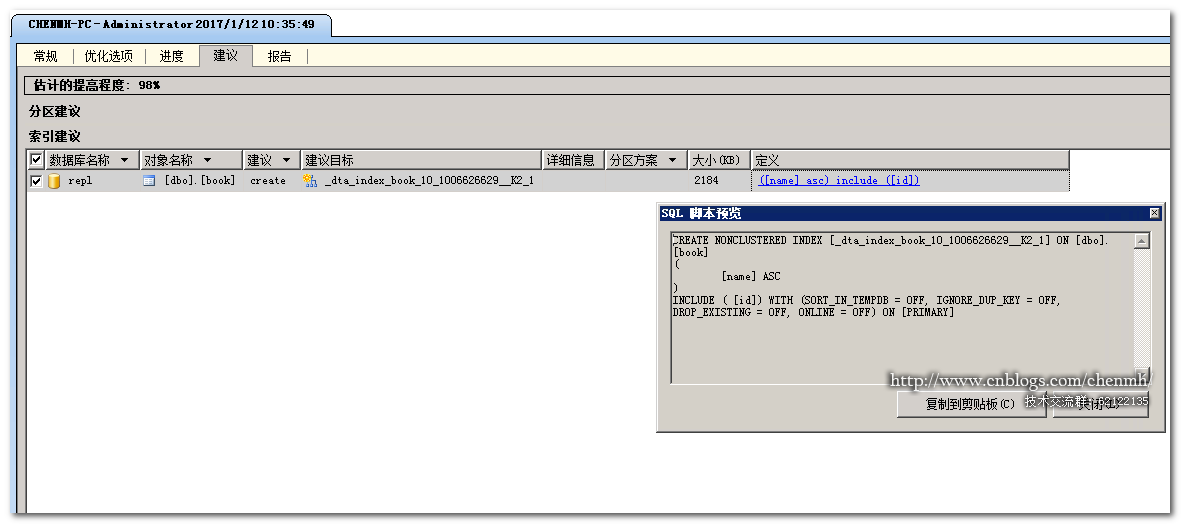
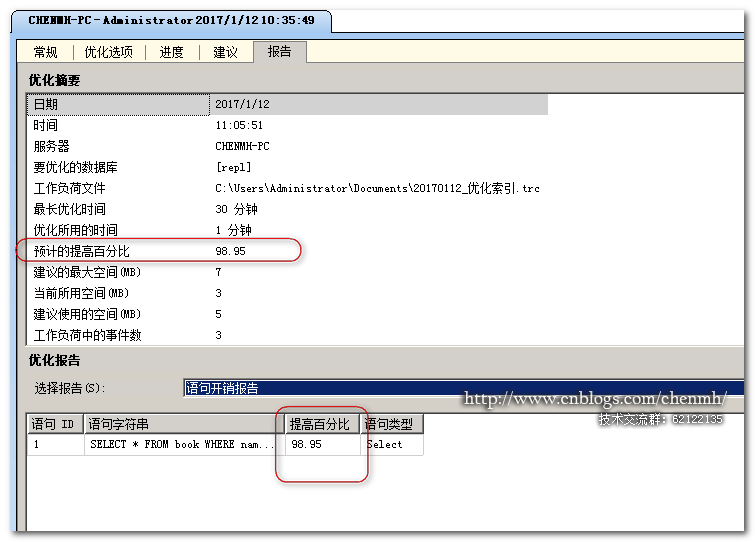
引擎优化顾问会自动生成创建索引的脚步,同时还给出了创建该索引之后预计性能可以提供的百分比,如果同时存在很多表的索引建议可以勾选需要保存的建议保存成sql文件在“开始分析”栏旁边有一个保存建议的按钮可以将建议保存成sql文件。
建议:
1.数据库引擎优化顾问给出的建议不是每一个都是对的,自己对比该SQL的执行频率来判断是否需要创建该索引,比如我当前这个SQL如果我这个SQL只执行了一次后面就不会再执行了那么这个索引就没必要创建了。
2.修改引擎优化顾问给出的索引名,数据库引擎优化顾问给出的创建索引的索引名不够直观,建议自己手动更改,比如改成“ix_book_name”,“索引标示_表名_字段描述”的规则。
3.用来分析的文件不要太大否则可能会分析不完成,不要在业务高峰期进行分析。
案例2:监控死锁
1.创建跟踪
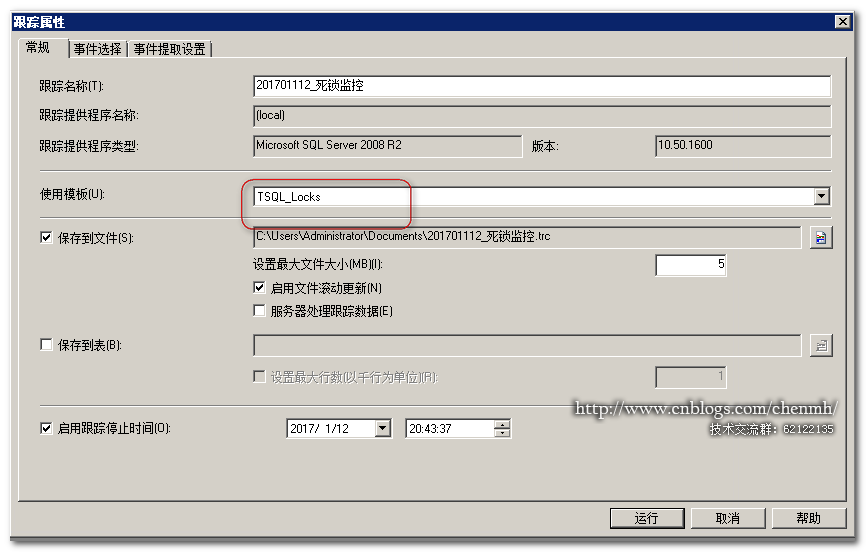
模板选择自带的“TSQL_Locks”模板,运行跟踪。
2.执行SQL
打开两个会话窗口分表执行如下SQL,先在会话1执行然后在10S内在会话2中执行,两个会话拥有各自的排他锁同时又去申请对方拥有的排他锁造成死锁。
会话1执行:当前会话1是62


BEGIN TRANSACTION UPDATE book SET name='a' WHERE ID=10 --延时10s执行 waitfor delay '0:0:10' UPDATE book SET name='a' WHERE ID=100
![]()

会话2执行:当前会话2是

BEGIN TRANSACTION UPDATE book SET name='b' WHERE ID=100 --延时20执行 waitfor delay '0:0:20' UPDATE book SET name='b' WHERE ID=10


msms客户端返回的错误消息显示当前62会话作为死锁的牺牲品。

3.跟踪分析死锁
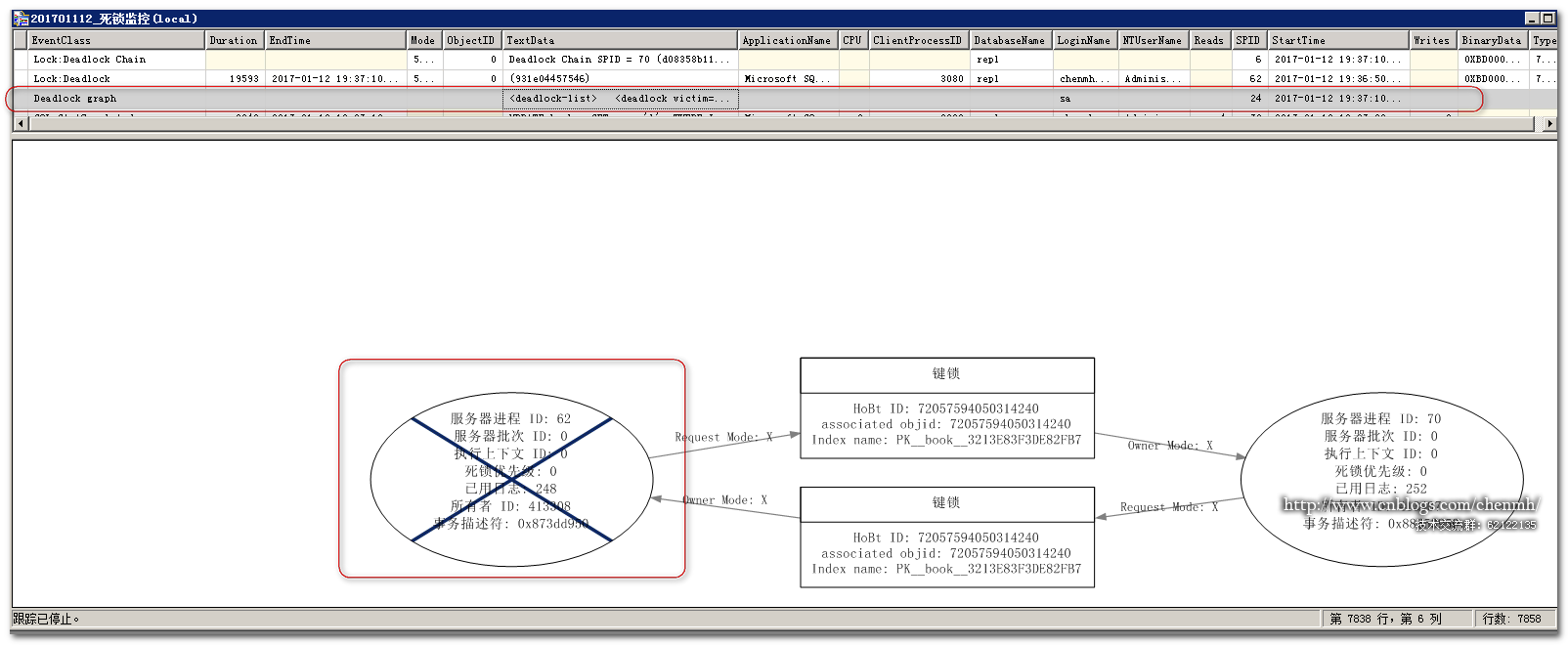
死锁跟踪事件使用图形和直观的返回了两个会话的死锁,其中62会话用了一个×表示当前的会话是死锁的牺牲品。
案例三:创建自定义跟踪模板
标准模板就是一个比较好的参考模板,比如我们对执行语句进行监控就可以参考标准模板在其基础上修改保存成自己的模板。
1.创建TSQL语句跟踪


2.创建跟踪模板
停止当前的TSQL跟踪,选择“文件”-“另存为跟踪模板”就可以保存成自己的跟踪模板。
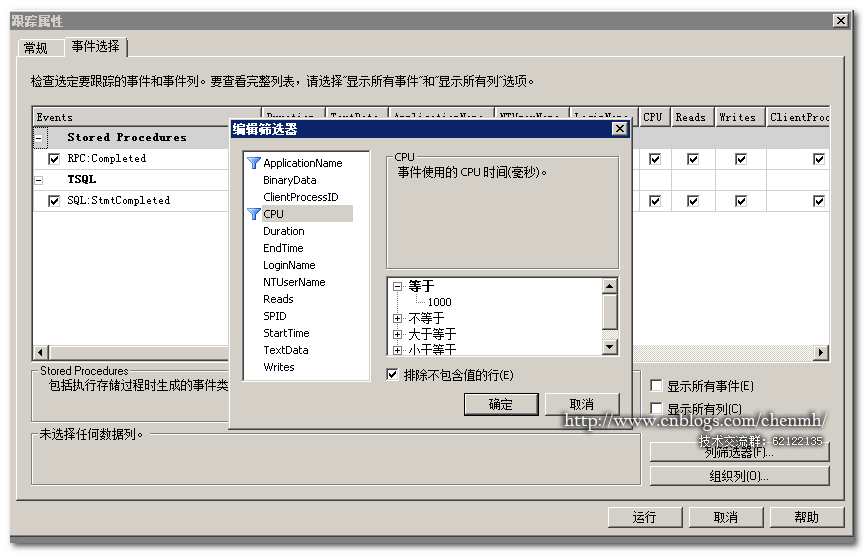
3.列筛选

当前是筛选跟踪的TSQL语句中包含book,这里的列筛选这执行 where like 的语法类似。
整形列的话就不需要带模糊条件:
注意:如果要取消列筛选记得把刚才的筛选条件删除同时把“排除不包含值的行” 的勾选也去除,记得两者都要去掉否则跟踪还是包含筛选的跟踪。
4.列组织
列组织其实就是按某列进行分组显示跟踪,类似select查询里面的group by操作。比如我当前按持续时间进行分组跟踪。
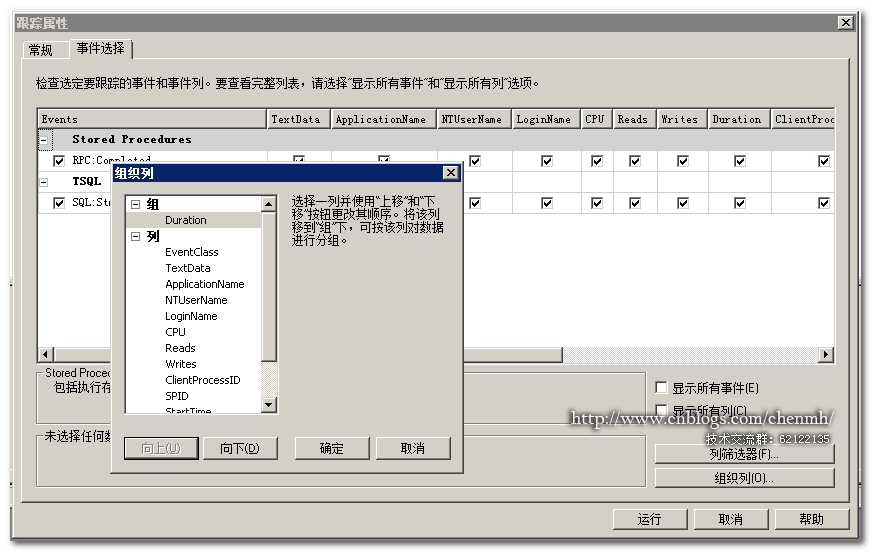
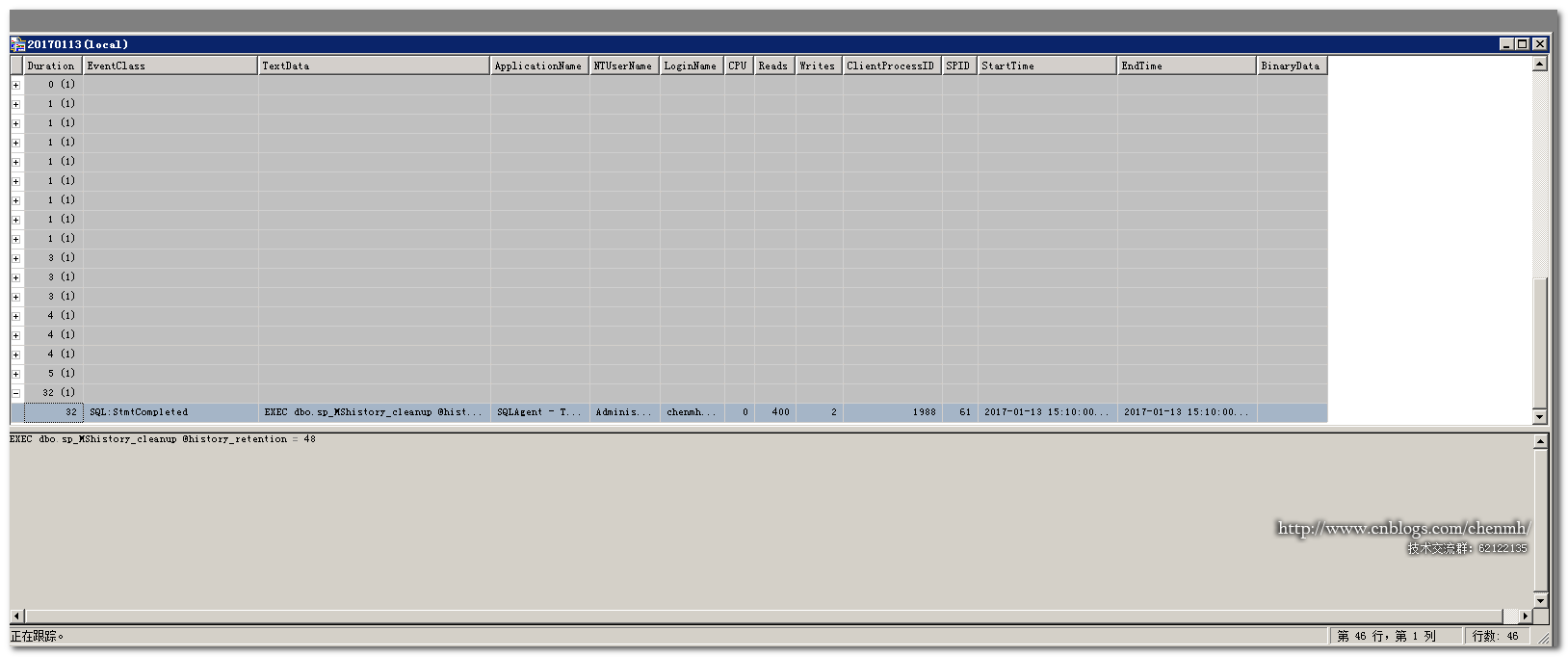
通过对持续时间进行分组,相同的持续时间会放在一个分组里。
总结
由于篇幅有限列举了一些简单常用的操作,其它的分类监控的方法类似有兴趣可以多去研究,profile是非常实用且界面化很好的监控工具这也是SQLServer独特的条件,应该熟练运用。