一、前言
最近在项目中做数据推荐的功能,比如,猜你喜欢。主动给用户推荐用户喜欢的商品。如何判断某个商品是不是用户喜欢的呢?在调研过程中,发现es可以做相似度的计算,相似度可以表示用户对某个商品的喜爱程度。下面我就介绍一下如何实现的。
二、数据源
要进行数据计算,首先是要有数据基础。我们的数据源是什么呢?我们目前数据来源是用户行为。我们会采集用户近100天的用户行为。根据用户行为计算出用户的向量。比如我们会统计用户浏览行为,点击行为,分享行为等,根据这些行为的数据,来计算出用户的向量。当然我们计算的是多维度的向量,为了简单表示,大家可以用二维向量来理解。如下面的图:

图中每一个小点点都是一个用户,用户会散列到象限中。
同理,我们的每一个商品也会有商品的向量。也会散列到象限中。
三、余弦相似度
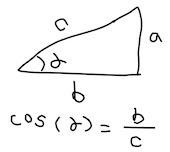
相似度是什么呢?可以理解为,相似度越近,用户越喜欢。如何计算相似度呢?我们在中学的时候学习了三角函数,其中有cos(x),可以来表示相似度,如下面图,cos(x) = b/c。当x角度越小的时候,cos(x)越小。
余弦相似度是很常见的相似度计算方案。除了余弦相似度,常见的
相似度计算有
:
- 欧几里得距离
- 皮尔逊相关系数
- 余弦相似度
- Tanimoto系数(广义Jaccard相似系数)

四、使用es计算余弦相似度
es如何计算相似度呢?
es 7.6.0 中提供了查询接口
先看下面的查询:
POST /index_vec_32/_search
{
"from": 1,
"size": 10,
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.queryVector, doc['vec'])+1",
"lang": "painless",
"params": {
"queryVector": [0.1, 0.2, -0.3,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1,0.1]
}
}
}
}, "_source": {
"includes": [
"tid",
"sku"
],
"excludes": []
}
}
查询结果如下:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.282883,
"hits" : [
{
"_index" : "index_vec_32",
"_type" : "_doc",
"_id" : "10_108219",
"_score" : 1.282883,
"_source" : {
"sku" : 10,
"tid" : "108219"
}
},
{
"_index" : "index_vec_32",
"_type" : "_doc",
"_id" : "10_108258",
"_score" : 1.282883,
"_source" : {
"sku" : 10,
"tid" : "108258"
}
},
{
"_index" : "index_vec_32",
"_type" : "_doc",
"_id" : "10_108262",
"_score" : 1.282883,
"_source" : {
"sku" : 10,
"tid" : "108262"
}
},
{
"_index" : "index_vec_32",
"_type" : "_doc",
"_id" : "10_108275",
"_score" : 1.282883,
"_source" : {
"sku" : 10,
"tid" : "108275"
}
}
]
}
}
es提供了script查询模型, 我们可以在查询的地方进行余弦相似度计算。根据这个特点,我们就可以来进行计算了。
java实现:
String inlineScript = "cosineSimilarity(params.queryVector, doc['vec'])+1";
Map<String, Object> param = new HashMap<>();
param.put("queryVector", vector);
Script script = new Script(ScriptType.INLINE, Script.DEFAULT_SCRIPT_LANG, inlineScript, param);
//筛选条件
BoolQueryBuilder query = QueryBuilders.boolQuery();
//eq
query.must(QueryBuilders.matchPhraseQuery("aaaaa","xxxx");
//in
if (!CollectionUtil.isNullOrEmpty(list)) {
Set set = new HashSet<Integer>();
for (Integer fieldValue : list) {
set.add(Integer.valueOf(fieldValue));
}
query.must(QueryBuilders.termsQuery("tid", set));
}
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.scriptScoreQuery(query, script));
//查询返回字段
String[] includeFields = new String[]{"tid", "sku"};
searchSourceBuilder.fetchSource(includeFields, null);
//分页参数
searchSourceBuilder.from(0);
searchSourceBuilder.size(topNumber);
SearchRequest searchRequest = new SearchRequest(ESConstant.calIndex);
searchRequest.source(searchSourceBuilder);
LinkedList<ResDTO> list = new LinkedList<>();
try {
SearchResponse scrollResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = scrollResponse.getHits();
SearchHit[] hits = searchHits.getHits();
for (SearchHit searchHit : hits) {
String sourceAsString = searchHit.getSourceAsString();
ResCalDTO dto = JsonUtil.fromJSON(sourceAsString, new TypeReference<ResCalDTO>() {
});
dto.setScore((double) searchHit.getScore());
ResDTO resDTO = new ResDTO();
resDTO.setTid(dto.getTid());
resDTO.setScore(dto.getScore());
if (dto.getSku().length() < 2) {
dto.setSku("0" + dto.getSku());
}
list.add(resDTO);
}
} catch (IOException e) {
logger.error("es query error,{}", e);
}
return list;
通过上面方法我们可以从es中算出top N的最相似的数据,这个就是我们需要给用户推荐的数据。
五、思考
还是学习数学好呀!数学解决了很多的问题,应用的计算机真是无敌的存在!