近日,抽空跑通了delf模型,它已经成为tensorflow models中research的一个子工程(见网址:https://github.com/tensorflow/models/tree/master/research/delf)。
该项目的介绍如下所示:
This project presents code for extracting DELF features, which were introduced with the paper
“Large-Scale Image Retrieval with Attentive Deep Local Features”
. A simple application is also illustrated, where two images containing the same landmark can be matched to each other, to obtain local image correspondences.
DELF is particularly useful for large-scale instance-level image recognition. It detects and describes semantic local features which can be geometrically verified between images showing the same object instance. The pre-trained model released here has been optimized for landmark recognition, so expect it to work well in this area. We also provide tensorflow code for building the DELF model, which could then be used to train models for other types of objects.
以图搜图模式的图像检索是CBIR(基于内容的图像检索)任务中最难的一块,其中由于图像拍摄角度的不同,有些图片只显示了局部信息,有些则有全局信息,在这种情况下的图像检索匹配的效果,以往算法都表现一般。而DELF模型则是ICCV 2017和CVPR 2018(Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking)提到的是当前效果最好的以图搜图的模型,具体而言他是一种基于图像中对象instance的检索匹配。
1、DELF的架构(实现流程)
如下图的流程可见,对于任何图像,需要获得特征,此处采用CNN架构来实现特征的抽取,其中DELF抽取的步骤如左图所示,主要区别是有个注意力的得分判断模型。然后通过提取后的特征进行匹配来获得。
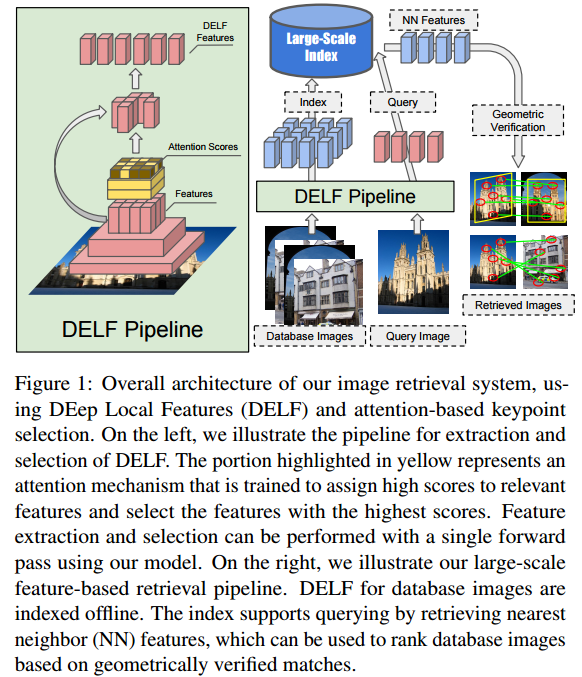
整个系统的四个部分如下:
Our large-scale retrieval system can be decomposed into four main blocks:
(i) dense localized feature extraction, 提取密集的局部特征,作者采用了ResNet50的全连接层来进行特征的抽取
(ii)keypoint selection, : 关键点选择,这是论文的关键部分,也是比较难懂的部分。除了注意力机制的使用,The proposed pipeline achieves both goals by training a model that encodes higher level semantics in the feature map, and learning to select discriminative features for the classification task. 作者直接在高层的语义上进行关键点检测,而不是在原图上检测。这也是为什么需要用到tensorflow 的object_detect包的原因。
(iii) dimensionality reduction : 降维,the selected features are L2 normalized, and their dimensionalityis reduced to 40 by PCA, which presents a good trade-off between compactness and discriminativeness.Finally, the features once again undergo L2 normalization. 主要办法是用 L2正则化,然后再用PCA进行降维。
(iv)indexing and retrieval. 索引提取,作者用KD树进行了索引。
2、实践
这个项目的复现比较复杂,需要综合用到slim和object_detect的包。
在对源码进行重新编译后,完成调试记录如下:
(1)取两张图片,如下进行测试
IMAGE_1_URL = 'https://upload.wikimedia.org/wikipedia/commons/c/ce/2006_01_21_Ath%C3%A8nes_Parth%C3%A9non.JPG'
IMAGE_2_URL = 'https://upload.wikimedia.org/wikipedia/commons/5/5c/ACROPOLIS_1969_-_panoramio_-_jean_melis.jpg'首先生成特征,这一步的过程需要的耗时较长,大概在20S左右。
检索匹配,这一步就超级快了。
实验结果

为了丰富实验,以澳门著名景点再进行实验,一个取正面,一个以侧面如下图所示:



从上面可以看出,这个效果还是相当好的。