目录
前言
经过前面几节的学习,我们现在终于具有做小项目的能力了。我们的目标就是我们之前涉及过的某电影排行榜,利用爬虫工具抓取Top250,用来练手。
需求
抓取某电影Top250的“电影名称”,“上映年份”,“评分”,“评分人数”四项内容,并另存为文件。

思路
查看页面源代码,看数据是否包含在源代码中,如果不在源代码中则考虑js动态加载数据,需要观察找到加载数据的源头,从而抓取数据,否则直接用正则解析源代码即可

可以看到,我们所需要的数据都在源代码中,所以我们直接用刚学习到的re正则表达式方法解析出我们想要的数据即可!
代码实现
第一步,老熟人了,先拿到页面源码:
url = 'https://movie.douban.com/top250'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54"
}
resp = requests.get(url, headers=headers)
page_content = resp.text按照思路,第二步就是观察源码来写对应的正则:
# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<moviename>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<movieyear>.*?) .*?<span '
r'class="rating_num" property="v:average">(?P<moviescore>.*?)</span>.*?'
r'<span>(?P<ratingnum>.*?)人评价</span>', re.S)可以从页面源代码中发现是从<li>标签开始有的电影信息,然后往后找到<span class=”title”>,在这可以找到电影名称,我们用?P<groupname>方法来给他起名,方便我们后面提取内容。后面部分也是一样的,依次找到上映年份、评分、评分人数并命名。
部分页面源代码(一个电影信息段)如下,方便大家对比正则表达式:
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2763627人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>第三步,开始匹配,并将获取的数据存入我们喜欢的文件形式中即可。我这里用的是csv文件,类似表格形式,需要导入csv库函数,后续会给出完整代码。
# 开始匹配
result = obj.finditer(page_content)
with open("data.csv", mode="w", encoding='utf-8',newline='') as f:
csvwriter = csv.writer(f)
for i in result:
print(i.group("moviename"))
print(i.group("moviescore"))
print(i.group("ratingnum"))
print(i.group("movieyear").strip()) # strip()去除前面的空格
dic = i.groupdict()
dic['movieyear'] = dic['movieyear'].strip()
csvwriter.writerow(dic.values())
f.close()
print("over!")此时我们发现只抓取到了前25名,可是如果再往后要怎么获取呢???
这时我们滑到底部,发现这个排名是分页的,并不是直接放在一页中。这也好理解,一次性请求250条数据,传输的数据量大,容易造成服务器堵塞,同时传输数据也存在传输错误率,一次性传输这么多数据很有可能会在传输过程中出现错误。
这时我们点到第二页,发现网页url变了:
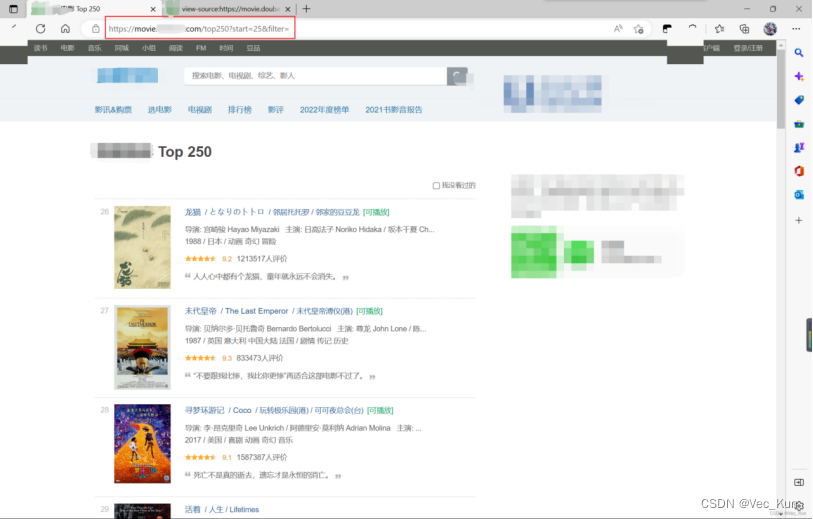
它后面加了“?start=25&filter=” ,他的意思大家可以猜测一下,很明显就是从第25名开始显示!
我们把url修改一下,把start参数修改成0试试,果然显示出了第一页:
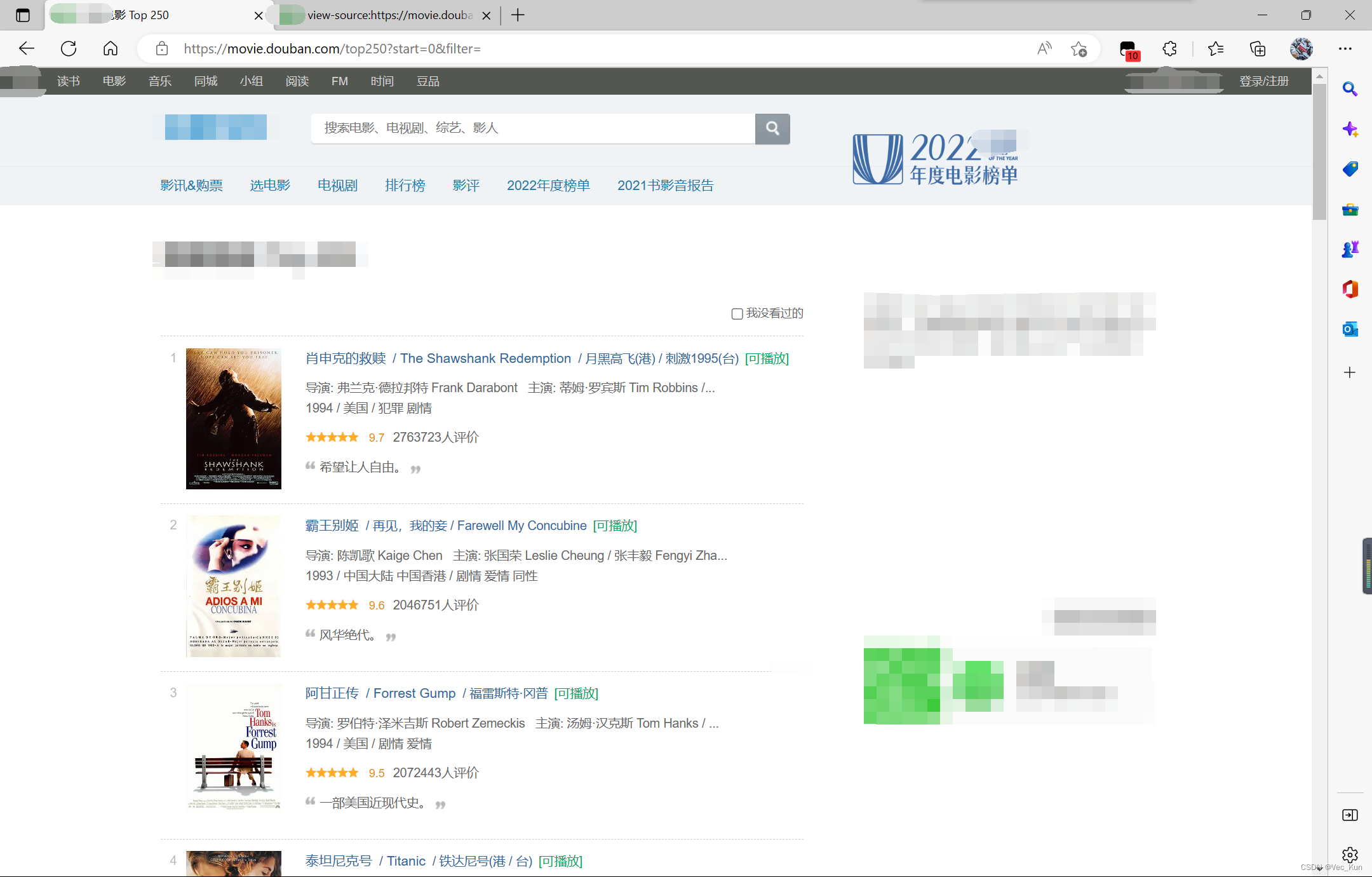
这下思路就清晰了,我们只需要把这个源代码循环执行,把start参数循环加25,循环十次就能导出我们想要的数据了!
小小写一个for循环就好了,但是为了不覆盖以前的数据,我们要把csv写入方式改为a+来加入后续数据,否则只会得到226-250名数据。
完整代码
# 拿到页面源代码 =>requests
# 通过re来提取想要的有效信息 =>re
import requests
import re
import csv
for rank in range(10):
url = 'https://movie.douban.com/top250' + '?start=' + str(25 * rank) + '&filter='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.54"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<moviename>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<movieyear>.*?) .*?<span '
r'class="rating_num" property="v:average">(?P<moviescore>.*?)</span>.*?'
r'<span>(?P<ratingnum>.*?)人评价</span>', re.S)
# 开始匹配
result = obj.finditer(page_content)
with open("data.csv", mode="a+", encoding='utf-8', newline='') as f:
csvwriter = csv.writer(f)
for i in result:
print(i.group("moviename"))
print(i.group("moviescore"))
print(i.group("ratingnum"))
print(i.group("movieyear").strip()) # strip()去除前面的空格
dic = i.groupdict()
dic['movieyear'] = dic['movieyear'].strip()
csvwriter.writerow(dic.values())
f.close()
print("over!")
注意还是要修改为自己的ua!怎么修改ua在之前的章节已经讲过了,只需要按下F12出现网页调试工具,进入网络/Network选项,在响应头中找到自己的User-Agent覆盖我的headers就好。
代码还有优化空间,各位可以思考一下如何降低代码的时间复杂度、空间复杂度,也就是提高运行效率。欢迎大家提意见!
运行结果
简要展示一下我的运行结果:

总结
今天我们学习了如何用已学的基础知识来手撕一个小程序,实现爬取某电影排行榜。使用了re正则方法来爬取信息,进一步熟悉了此种爬虫方式,大家感兴趣的话也可以自己找找其他感兴趣的网页尝试爬取对应的信息。
不过记得一定要适度,不要频繁访问导致ip被禁用~
还要记得resp.close()来关闭请求端口,以免端口占用过多导致无法访问网页。