什么是爬虫。简单一句话就是代替人去模拟浏览器进行网页操作。
爬虫的作用。为其他程序提供数据源,如搜索引擎(百度、Google等)、数据分析、大数据等等。
一、准备工作
我们需要先做好如下准备工作:
-
安装好Python3,最低为3.6 版本,并能成功运行 Python3 程序。
具体安装步骤可以看下这个链接:
http://t.csdn.cn/RvBqQ
2.了解 Python HTTP请求库requests 的基本用法。
请求,英文为Request,由客户端发往服务器,分为四部分内容: 请求方法(Request Method).请求的网址(Request URL )、请求头( Request Headers )、请求体(Request Body )。
这里我就不系统的解释了,如果想要了解更完善可以点击这个链接:
http://t.csdn.cn/unbf3
3.了解正则表达式的用法和 Python 中正则表达式库 re 的基本用法。
1.正则表达式的用法
(1)判断特定字符串
(2)切割字符串
(3)提取字符串信息
(4)替换字符串
2.正则表达式库 re 的基本用法
re模块主要定义了9个常量、12个函数、1个异常,re库,Python处理文本的标准库(标准库的意思表示这是一个Python内置模块,不需要额外下载)。
(1)sreach用法 :它会搜索整个 HTML 文本,找到符合上述正则表达式的第一个内容并返回。匹配连续的多个数值。
(2)match用法:向它传人要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否和字符串相匹配。
(3)compile用法:可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
(4) findall用法:获取与正则表达式相匹配的所有字符串。
(5) sub 用法:使用正则表达式提取信息,有时候还需要借助它来修改文本。
二.爬取目标
本节我们以一个基本的静态网站作为案例进行爬取,需要爬取的链接为
https://ssr1.scrape.center
这个网站里面包含一些电影信息,界面如图所示。
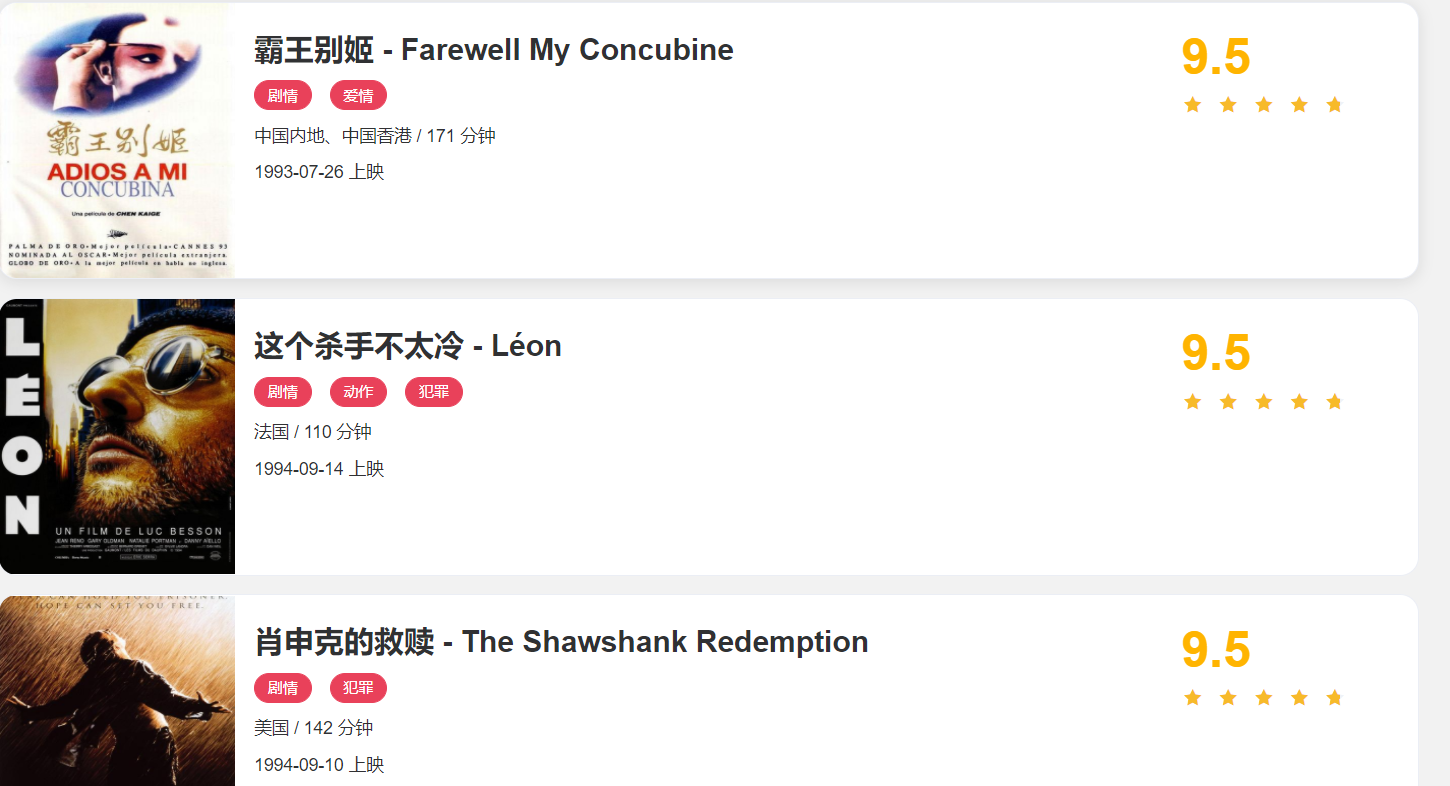
网站首页展示了一个由多个电影组成的列表,其中每部电影都包含封面、名称、分类、上映时间评分等内容,同时列表页还支持翻页,单击相应的页码就能进入对应的新列表页。如果我们点开其中一部电影,会进入该电影的详情页面,例如我们打开第一部电影《霸王别姬》.会得到如图 所示的页面。

这个页面显示的内容更加丰富,包括剧情简介、导演、演员等信息。
我们本次爬虫要完成的目标有:
1.利用 requests 爬取这个站点每一页的电影列表,顺着列表再爬取每个电影的详情页;
2.用正则表达式提取每部电影的名称、封面、类别、上映时间、评分、刷情简介等内容
把以上爬取的内容保存为JSON 文本文件;
已经做好准备,也明确了目标,那我们现在就开始吧。
三.爬取列表页
1.爬取肯定要从列表页人手,我们首先观察一下列表页的结构和翻页规则。在浏览器中访问
https://ssr1.scrape.center
,然后打开浏览器开发者工具,如图所示。然后打开浏览器开发者工具,如图所示。
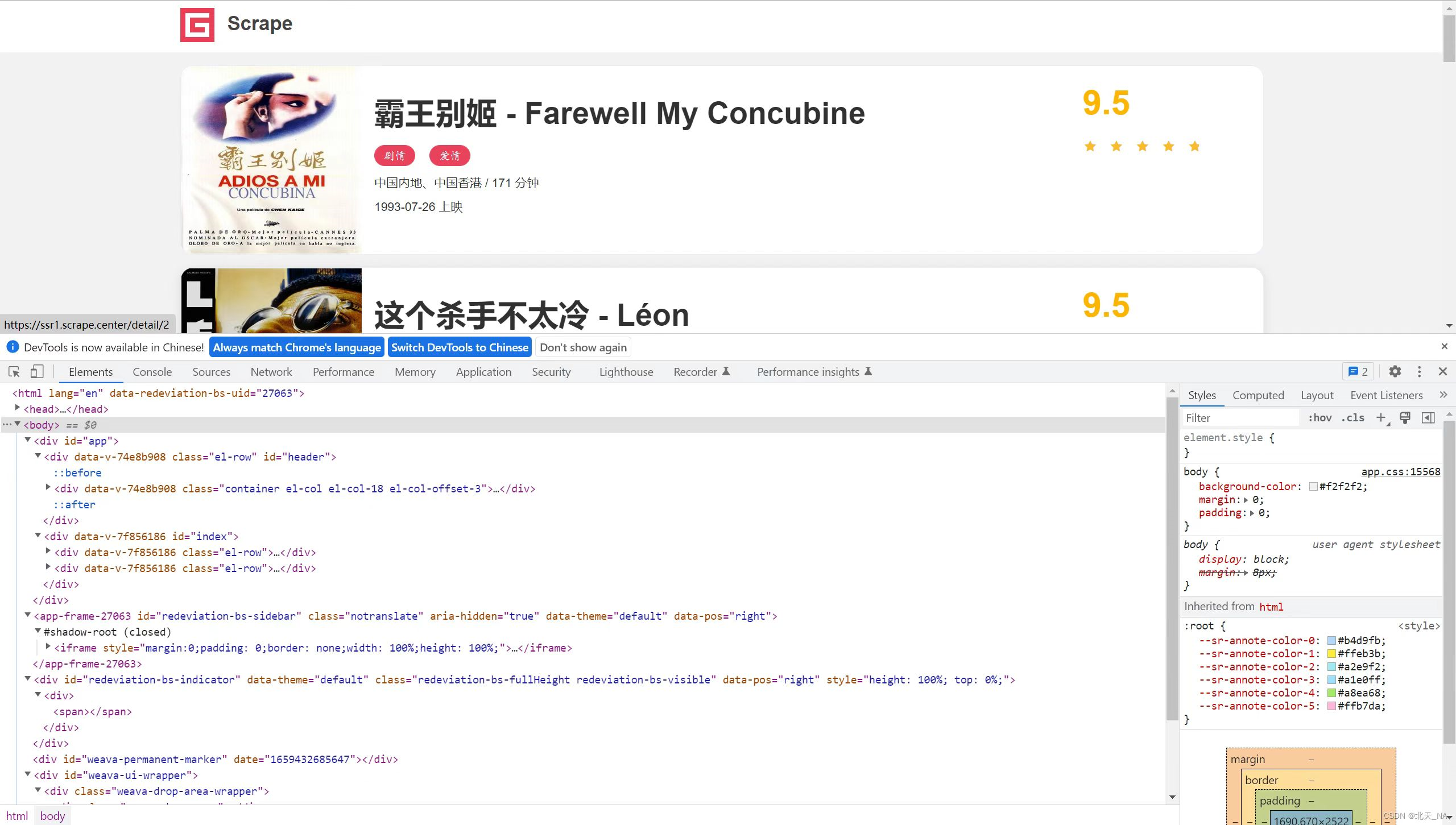
2.观察每一个电影信息区块对应的 HTML 以及进入到详情页的 URL,可以发现每部电影对应的区块都是一个div节点,这些节点的 class 属性中都有 el-card这个值。每个列表页有 10个这样的 div节点,也就对应着 10 部电影的信息。
接下来再分析一下是怎么从列表页进入详情页的,我们选中第一个电影的名称,看下结果,如图所示。

可以看到这个名称实际上是一个 h2 节点,其内部的文字就是电影标题。h2 节点的外面包含一个a节点,这个a节点带有 href属性,这就是一个超链接,其中 href 的值为 /detail/1,这是一个相对网站的根 URL
https://ssr1.scrape.center/
的路径,加上网站的根 URL 就构成
https://ssr1.scrape.center
)detail/1,也就是这部电影的详情页的 URL。这样我们只需要提取这个 href 属性就能构造出详情页的URL 并接着爬取了。
接下来我们分析翻页的逻辑,拉到页面的最下方,可以看到分页页码,如图所示。
import requests
import logging
import re
from urllib.parse import urljoin
logging.basicConfig(level=logging.INFO, format=’%(asctime)s – %(levelname)s: %(message)s’) # 用来定义日志输出几倍和输出格式
BASE_URL = ‘
https://ssr1.scrape.center
‘ # URL的根URL
TOTAL_PAGE = 10 # 需要爬取的总页码数(按需选择)
接下来实现每一个页面的爬取功能
def scrape_page(url):
logging.info(‘抓取%s中…’, url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
logging.error(‘抓取%s时获取无效的状态码%s’, url, response.status_code)
except requests.RequestException:
logging.error(‘抓取%s时发生错误’, url, exc_info=True)
可以观察到这里一共有 100 条数据,页码最多是10
我们单击第 2页、如图 所示。
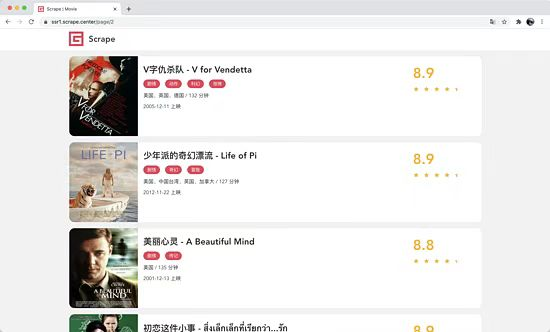
相比根 URL多了 /page/2 这部分内容。网页的结构还是和原来一模一样,可以像第 1页那样处理。
接着我们查看第3页、第4页等内容,可以发现一个规律,这些页面的URL最后分别为 /page/3/page/4。所以,/page 后面跟的就是列表页的页码,当然第 1 页也是一样,我们在根 URL后面加上/page/1 也是能访问这页的,只不过网站做了一下处理,默认的页码是1,所以第一次显示的是第1页内容。
好,分析到这里,逻辑基本清晰了
3.程序的实现
于是我们要完成列表页的爬取,可以这么实现:
遍历所有页码,构造 10页的索引页URL;
从每个索引页,分析提取出每个电影的详情页 URL。
那么我们写代码来实现一下吧。
首先,需要先定义一些基础的变量,并引人一些必要的库,写法如下
import requests
import logging
import re
from urllib.parse import urljoin
RESULT_DIR = ‘result’
logging.basicConfig(level=logging.INFO,
format=’%(asctime)s – %(levelname)s: %(message)s’)
BASE_URL = ‘
https://ssr1.scrape.center
‘
TOTAL_PAGE = 10
这里我们引人了requests库用来爬取页面、logging库用来输出信息、re库用来实现正则表达式解析、urljoin 模块用来做 URL的拼接。
接着我们定义了日志输出级别和输出格式,以及 BASE URL 为当前站点的根 URL,TOTAL_PAGE 为需要爬取的总页码数量。
完成了这些工作,来实现一个页面爬取的方法吧,实现如下:
def scrape_page(url):
logging.info(‘scraping %s…’, url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
logging.error(‘get invalid status code %s while scraping %s’,
response.status_code, url)
except requests.RequestException:
logging.error(‘error occurred while scraping %s’, url, exc_info=True)
四.爬取详情页
第一步:
现在我们已经可以成功获取所有详情页 URL 了,那么下一步当然就是解析详情页并提取出我们想要的信息了。我们首先观察一下详情页的 HTML 代码吧,如图所示:

经过分析,我们想要提取的内容和对应的节点信息如下:
封面:是一个 img 节点,其 class 属性为 cover
名称:是一个 h2 节点,其内容便是名称。
类别:是 span 节点,其内容便是类别内容,其外侧是 button 节点,再外侧则是 class 为 categories 的 div 节点。
上映时间:是 span 节点,其内容包含了上映时间,其外侧是包含了 class 为 info 的 div 节点。另外提取结果中还多了「上映」二字,我们可以用正则表达式把日期提取出来。
评分:是一个 p 节点,其内容便是评分,p 节点的 class 属性为 score。
剧情简介:是一个 p 节点,其内容便是剧情简介,其外侧是 class 为 drama 的 div 节点。
看似有点复杂是吧,不用担心,有了正则表达式,我们可以轻松搞定。
接着我们来实现一下代码吧。刚才我们已经成功获取了详情页 URL,接着当然是定义一个详情页的爬取方法了,实现如下:
def scrape_detail(url):
return scrape_page(url)
这里定义了一个 scrape_detail 方法,接收一个 url 参数,并通过调用 scrape_page 方法获得网页源代码。由于我们刚才已经实现了 scrape_page 方法,所以在这里我们不用再写一遍页面爬取的逻辑了,直接调用即可,做到了代码复用。另外有人会说,这个 scrape_detail 方法里面只调用了 scrape_page 方法,别没有别的功能,那爬取详情页直接用 scrape_page 方法不就好了,还有必要再单独定义 scrape_detail 方法吗?有必要,单独定义一个 scrape_detail 方法在逻辑上会显得更清晰,而且以后如果我们想要对 scrape_detail 方法进行改动,比如添加日志输出,比如增加预处理,都可以在 scrape_detail 里面实现,而不用改动 scrape_page 方法,灵活性会更好。
第二步:
好了,详情页的爬取方法已经实现了,接着就是详情页的解析了,实现如下:
def parse_detail(html):
cover_pattern = re.compile(‘class=\”item.*?\u003Cimg.*?src=\”(.*?)\”.*?class=\”cover\”>’, re.S)
name_pattern = re.compile(‘\u003Ch2.*?>(.*?)\u003C/h2>’)
categories_pattern = re.compile(‘\u003Cbutton.*?category.*?\u003Cspan>(.*?)\u003C/span>.*?\u003C/button>’, re.S)
published_at_pattern = re.compile(‘(\\d{4}-\\d{2}-\\d{2})\\s?上映’)
drama_pattern = re.compile(‘\u003Cdiv.*?drama.*?>.*?\u003Cp.*?>(.*?)\u003C/p>’, re.S)\n score_pattern = re.compile(‘\u003Cp.*?score.*?>(.*?)\u003C/p>’, re.S)
cover = re.search(cover_pattern, html).group(1).strip() if re.search(cover_pattern, html) else None
name = re.search(name_pattern, html).group(1).strip() if re.search(name_pattern, html) else None
categories = re.findall(categories_pattern, html) if re.findall(categories_pattern, html) else []
published_at = re.search(published_at_pattern, html).group(1) if re.search(published_at_pattern, html) else None
drama = re.search(drama_pattern, html).group(1).strip() if re.search(drama_pattern, html) else None
score = float(re.search(score_pattern, html).group(1).strip()) if re.search(score_pattern, html) else None
return {
‘cover’: cover,
‘name’: name
‘categories’: categories,
‘published_at’: published_at,
‘drama’: drama,
‘score’: score
}
这里我们定义了 parse_detail 方法用于解析详情页,它接收一个参数为 html,解析其中的内容,并以字典的形式返回结果。每个字段的解析情况如下所述:
(.*?)
(.*?)
(.*?)
(\\d{4}-\\d{2}-\\d{2})
最后,上述的字段提取完毕之后,构造一个字典返回即可。
这样,我们就成功完成了详情页的提取和分析了。最后,main 方法稍微改写一下,增加这两个方法的调用,改写如下:
def main():
for page in range(1, TOTAL_PAGE + 1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info(‘get detail data %s’, data)
这里我们首先遍历了 detail_urls,获取了每个详情页的 URL,然后依次调用了 scrape_detail 和 parse_detail 方法,最后得到了每个详情页的提取结果,赋值为 data 并输出。运行结果如下:
2020-03-08 23:37:35,936 – INFO: scraping
https://ssr1.scrape.center/page/1…
2020-03-08 23:37:36,833 – INFO: get detail url
https://ssr1.scrape.center/detail/1
2020-03-08 23:37:36,833 – INFO: scraping
https://ssr1.scrape.center/detail/1..
2020-03-08 23:37:39,985 – INFO: get detail data {‘cover’: ‘
https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c’,
…
由于内容较多,这里省略了后续内容。可以看到,这里我们就成功提取出来了每部电影的基本信息了,包括封面、名称、类别等等
五.保存数据
成功提取到详情页信息之后,我们下一步就要把数据保存起来了。由于我们到现在我们还没有学习数据库的存储,所以现在我们临时先将数据保存成文本格式,在这里我们可以一个条目一个 JSON 文本。
定义保存数据的方法如下:
import json
from os import makedirs
from os.path import exists
RESULTS_DIR = ‘results’\nexists(RESULTS_DIR) or makedirs(RESULTS_DIR)
def save_data(data):
name = data.get(‘name’)
data_path = f'{RESULTS_DIR}/{name}.json’
json.dump(data, open(data_path, ‘w’, encoding=’utf-8′), ensure_ascii=False, indent=2)
在这里我们首先定义了数据保存的文件夹 RESULTS_DIR,然后判断了下这个文件夹是否存在,如果不存在则创建。
接着,我们定义了保存数据的方法 save_data,首先我们获取了数据的 name 字段,即电影的名称,我们将电影的名称当做 JSON 文件的名称,接着构造了 JSON 文件的路径,然后用 json 的 dump 方法将数据保存成文本格式。在 dump 的方法设置了两个参数,一个是 ensure_ascii 设置为 False,可以保证的中文字符在文件中能以正常的中文文本呈现,而不是 unicode 字符;另一个 indent 为 2,则是设置了 JSON 数据的结果有两行缩进,让 JSON 数据的格式显得更加美观。
好的,那么接下来 main 方法稍微改写一下就好了,改写如下:
def main():
for page in range(1, TOTAL_PAGE + 1):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info(‘get detail data %s’, data)
logging.info(‘saving data to json file’)
save_data(data)
logging.info(‘data saved successfully’)
这里就是加了 save_data 方法的调用,并加了一些日志信息。
重新运行,我们看下输出结果:
2020-03-09 01:10:27,094 – INFO: scraping
https://ssr1.scrape.center/page/1…
2020-03-0901:10:28,019 – INFO: get detail url
https://ssr1.scrape.center/detail/1
2020-03-09 01:10:28,019 – INFO: scraping
https://ssr1.scrape.center/detail/1…
2020-03-09
01:10:29,183
– INFO: get detail data {‘cover’: ‘
https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c’,
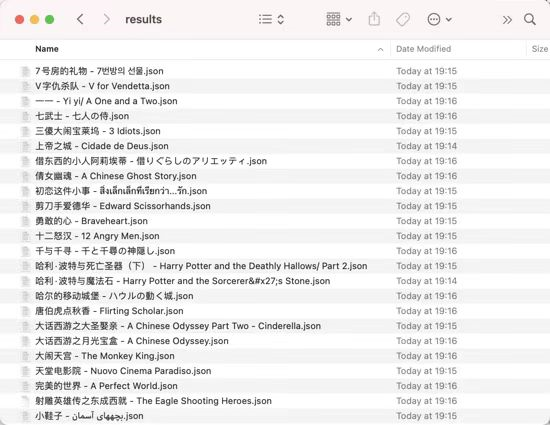
通过运行结果可以发现,这里成功输出了将数据存储到 JSON 文件的信息。\n\n运行完毕之后我们可以观察下本地的结果,可以看到 results 文件夹下就多了 100 个 JSON 文件,每部电影数据都是一个 JSON 文件,文件名就是电影名,如图所示
六.多进程加速
由于整个爬取是单进程的,而且只能逐条爬取,因此速度稍微有点慢,那有没有方法对整个爬取过程进行加速呢?
下面就来实践一下多进程爬取吧。
由于一共有10页详情页,且这 10 页内容互不于扰,因此我们可以一页开一个进程来爬取。而且因为这 10个列表页页码正好可以提前构造成一个列表,所以我们可以选用多进程里面的进程池 pool来实现这个过程。
这里我们需要改写下main方法,实现如下
def save_data(data):
name = data.get(‘name’)
data_path = f'{RESULT_DIR}/{name}.json’
json.dump(data,open(data_path,’w’,encoding=’utf-8′),ensure_ascii=False,indent=2)
if __name__ == ‘__main__’:
pool = multiprocessing.Pool()
pages = range(1,TOTAL_PAGE+1)
pool.map(main,pages)
pool.close()
pool.join()
我们首先给main 方法添加了一个参数 pege.用以表示列表页的页码。接着声明了一个进程池,并声明 pages 为所有需要逾历的页码,即1-10最后调用 map 方法,其第一个参数就是需要被调用的参数,第二个参数就是 pages,即需要遍历的页码。
这样就会依次遍历pages 中的内容,把1-10这10个页码分别传递给 main方法,并把每次的调用分别变成一个进程、加人进程池中,进程池会根据当前运行环境来决定运行多少个进程。例如我的机器的CPU有8个核、那么进程池的大小就会默认设置为 8,这样会有8个进程并行运行。
运行后的输出结果和之前类似,只是可以明显看到,多进程执行之后的爬取速度快了很多。可以清空之前的爬取数据、会发现数据依然可以被正常保存成JSON 文件。
好了、到现在为止、我们就完成了全站电影数据的爬取,并实现了爬取数据的存储和优化
七.总结
本节用到的库有roquests、multiprocessing、relogging等,通过这个案例实战,我们把前面学习到的知识都串联了起来、对于其中的一些实现方法,可以好好思考和体会,也希望这个案例能够让你对爬虫的实现有更实际的了解。
希望这篇文章能对大家有所帮助,希望大家能从中学到知识。