一、基本操作
Spark SQL提供了两个常用的加载数据和写入数据的方法:load()方法和save()方法。load()方法可以加载外部数据源为一个DataFrame,save()方法可以将一个DataFrame写入指定的数据源。
二、默认数据源
(一)默认数据源Parquet
默认情况下,load()方法和save()方法只支持Parquet格式的文件,Parquet文件是以二进制方式存储数据的,因此不可以直接读取,文件中包括该文件的实际数据和Schema信息,也可以在配置文件中通过参数spark.sql.sources.default对默认文件格式进行更改。Spark SQL可以很容易地读取Parquet文件并将其数据转为DataFrame数据集。
(二)案例演示读取Parquet文件
将数据文件users.parquet上传到master虚拟机/home
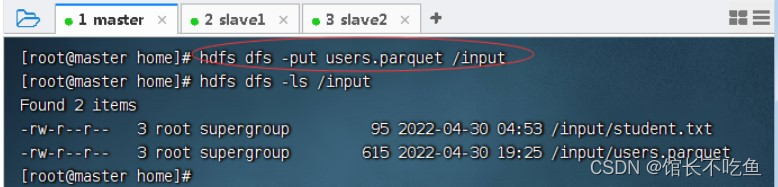
将数据文件
users.parquet
上传到HDFS的
/input
目录
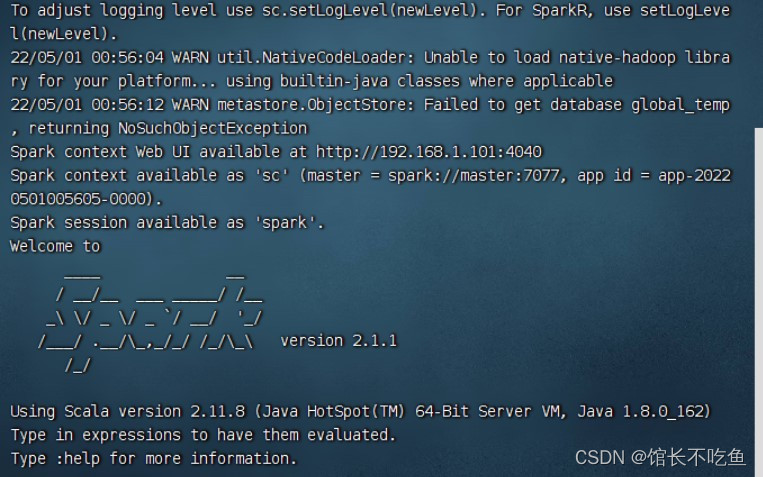
启动Spark Shell,执行命令:
spark-shell --master spark://master:7077
然后执行命令:
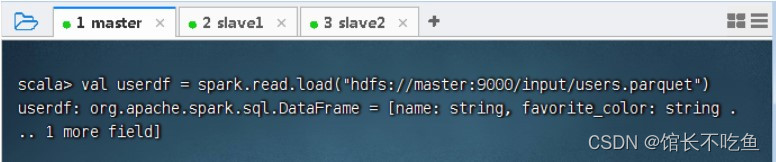
val userdf = spark.read.load("hdfs://master:9000/input/users.parquet")
执行命令:
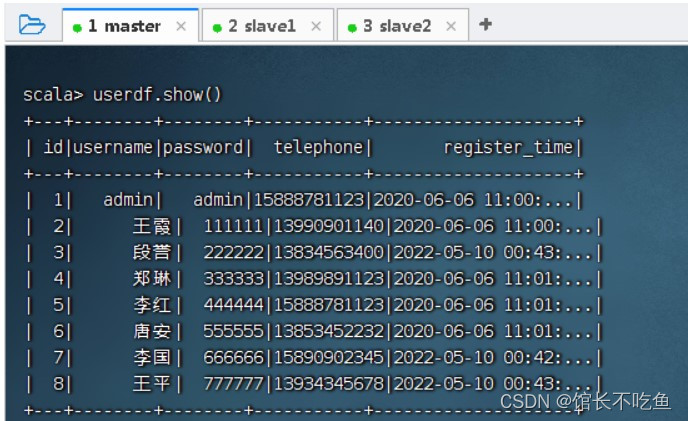
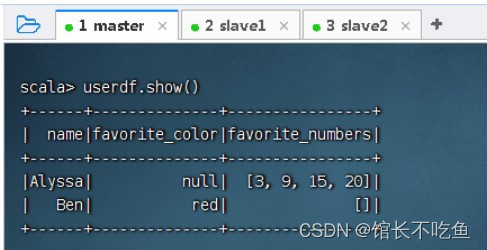
userdf.show()
,查看数据帧内容
执行命令:
userdf.select("name","favorite_color").write.save("hdfs://master:9000/result")
,对数据帧指定列进行查询,查询结果依然是数据帧,然后通过save()方法写入HDFS指定目录

使用命令:
hdfs dfs -ls/result
查看HDFS上的输出结果
基于数据帧创建临时视图,执行命令:
userdf.createTempView("t_user")
执行SQL查询,将结果写入HDFS,执行命令:
spark.sql("select name, favorite_color from t_user").write.save("hdfs://master:9000/result2")
然后再查看HDFS的输出结果
创建Maven项目 – SparkSQLDemo
创建完项目后在pom.xml文件里添加依赖与插件


创建
net.hw.sparksql
包,在包里创建
ReadParquet
对象

可手动指定数据源
(一)format()与option()方法概述
使用format()方法可以手动指定数据源。数据源需要使用完全限定名(例如org.apache.spark.sql.parquet),但对于Spark SQL的内置数据源,也可以使用它们的缩写名(JSON、Parquet、JDBC、ORC、Libsvm、CSV、Text)。
通过手动指定数据源,可以将DataFrame数据集保存为不同的文件格式或者在不同的文件格式之间转换。
在指定数据源的同时,可以使用option()方法向指定的数据源传递所需参数。例如,向JDBC数据源传递账号、密码等参数。
读取房源csv文件
-
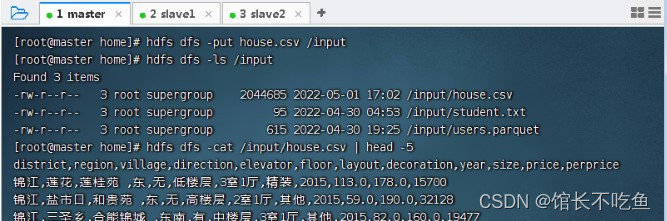
查看HDFS上
/input
目录里的
house.csv
文件
在spark shell里,执行命令:
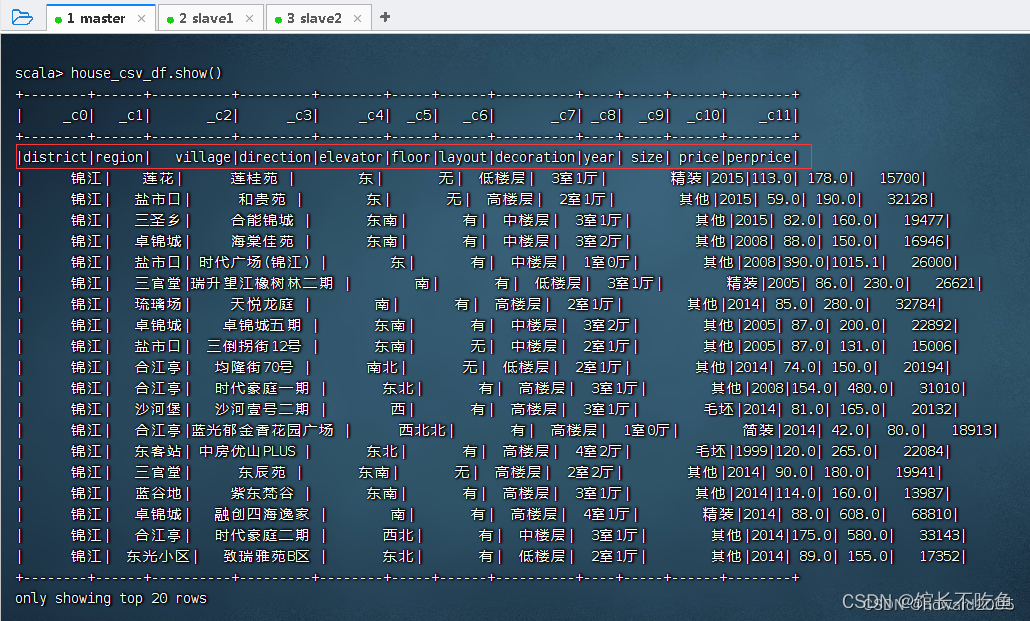
val house_csv_df = spark.read.format("csv").load("hdfs://master:9000/input/house.csv")
,读取房源csv文件,得到房源数据帧
在master中执行命令
执行命令:
val house_csv_df = spark.read.format("csv").option("header", "true").load("hdfs://master:9000/input/house.csv")
将
people.json
上传到HDFS的
/input
目录
执行命令:
val peopledf = spark.read.format("json").load("hdfs://master:9000/input/people.json")
执行命令:
peopledf.show()
执行命令:
peopledf.select("name","age").write.format("parquet").save("hdfs://master:9000/result4")
查看生成的
parquet
文件
后在SQL中查看
student
数据库里的
t_user
表,后执行命令

如果报错,找不到数据库驱动程序
com.mysql.jdbc.Driver
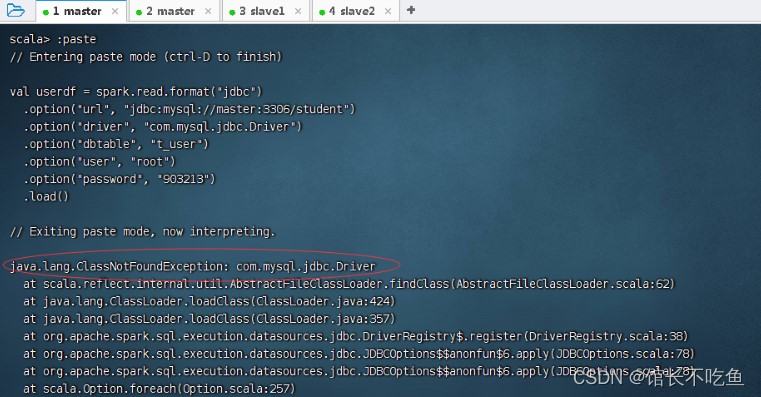
则将数据库驱动程序拷贝到
$SPARK_HOME/jars
目录
然后将数据驱动程序分发到slave1和slave2虚拟机
然后再执行命令
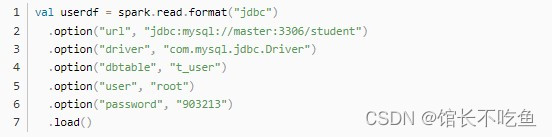
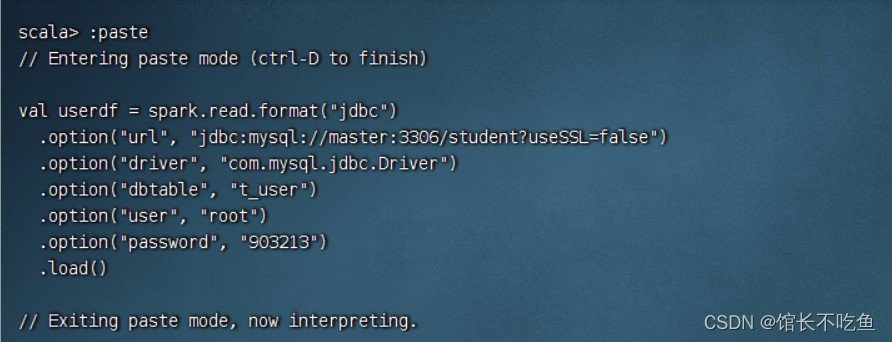
然后执行命令:
userdf.show()