什么是GAN




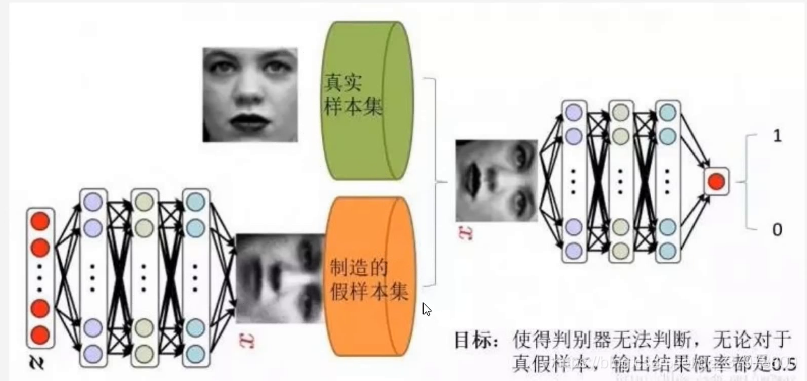






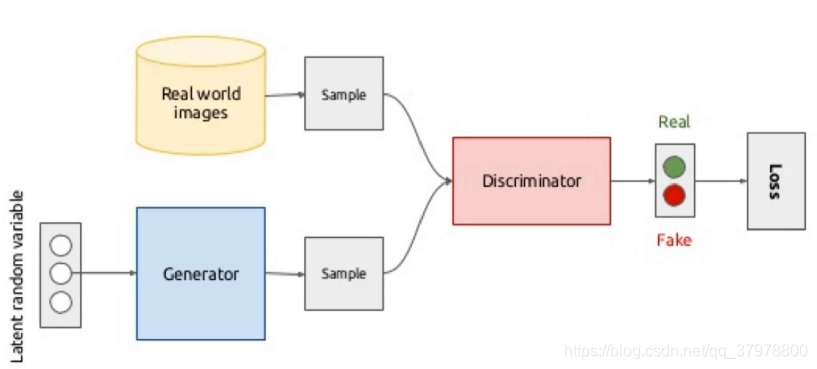


实现代码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import glob
import os
# 显存自适应分配
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练
# 手写数据集
(train_images,train_labels),(test_images,test_labels) = tf.keras.datasets.mnist.load_data()
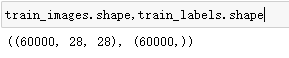
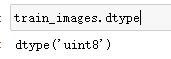
train_images = train_images.reshape(train_images.shape[0],28,28,1).astype("float32")

# 归一化
train_images = (train_images-127.5)/127.5
BATCH_SIZE = 256
BUFFER_SIZE = 60000
# 创建数据集
datasets = tf.data.Dataset.from_tensor_slices(train_images)
# 乱序
datasets = datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)

编写模型
# 生成器模型
def generator_model():
model = keras.Sequential() # 顺序模型
model.add(layers.Dense(256,input_shape=(100,),use_bias=False)) # 输出256个单元,随机数输入数据形状长度100的向量
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())# LeakyReLU()激活
model.add(layers.Dense(512,use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())# 激活
model.add(layers.Dense(28*28*1,use_bias=False,activation="tanh")) # 输出28*28*1形状 使用tanh激活得到-1 到1 的值
model.add(layers.BatchNormalization())
model.add(layers.Reshape((28,28,1))) # reshape成28*28*1的形状
return model
# 判别模型
def discriminator_model():
model = keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(512,use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())# 激活
model.add(layers.Dense(256,use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())# 激活
model.add(layers.Dense(1))
return model
# 编写loss binary_crossentropy(对数损失函数)即 log loss,与 sigmoid 相对应的损失函数,针对于二分类问题。
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
# 辨别器loss
def discriminator_loss(real_out,fake_out):
read_loss = cross_entropy(tf.ones_like(real_out),real_out) # 使用binary_crossentropy 对真实图片判别为1
fake_loss = cross_entropy(tf.zeros_like(fake_out),fake_out) # 生成的图片 判别为0
return read_loss + fake_loss
# 生成器loss
def generator_loss(fake_out):
return cross_entropy(tf.ones_like(fake_out),fake_out) # 希望对生成的图片返回为1
# 优化器
generator_opt = tf.keras.optimizers.Adam(1e-4) # 学习速率1e-4 0.0001
discriminator_opt = tf.keras.optimizers.Adam(1e-4)
EPOCHS = 100 # 训练步数
noise_dim = 100
num_exp_to_generate = 16
seed = tf.random.normal([num_exp_to_generate,noise_dim]) # 16,100 # 生成16个样本,长度为100的随机数
generator = generator_model()
discriminator = discriminator_model()
# 训练一个epoch
def train_step(images):
noise = tf.random.normal([BATCH_SIZE,noise_dim])
with tf.GradientTape() as gen_tape,tf.GradientTape() as disc_tape: # 梯度
real_out = discriminator(images,training=True)
gen_image = generator(noise,training=True)
fake_out = discriminator(gen_image,training=True)
gen_loss = generator_loss(fake_out)
disc_loss = discriminator_loss(real_out,fake_out)
gradient_gen = gen_tape.gradient(gen_loss,generator.trainable_variables)
gradient_disc = disc_tape.gradient(disc_loss,discriminator.trainable_variables)
generator_opt.apply_gradients(zip(gradient_gen,generator.trainable_variables))
discriminator_opt.apply_gradients(zip(gradient_disc,discriminator.trainable_variables))
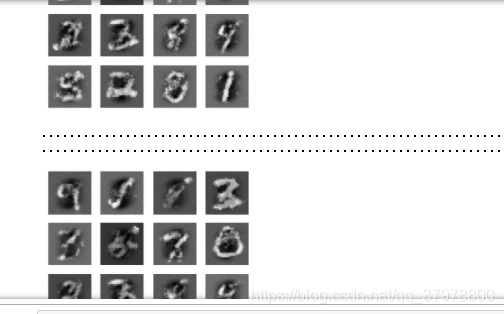
def genrate_plot_image(gen_model,test_noise):
pre_images = gen_model(test_noise,training=False)
fig = plt.figure(figsize=(4,4))
for i in range(pre_images.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow((pre_images[i,:,:,0]+1)/2,cmap="gray")
plt.axis("off")
plt.show()
def train(dataset,epochs):
for epoch in range(epochs):
for image_batch in dataset:
train_step(image_batch)
print(".",end="")
genrate_plot_image(generator,seed)
# 训练模型
train(datasets,EPOCHS)


版权声明:本文为qq_37978800原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。