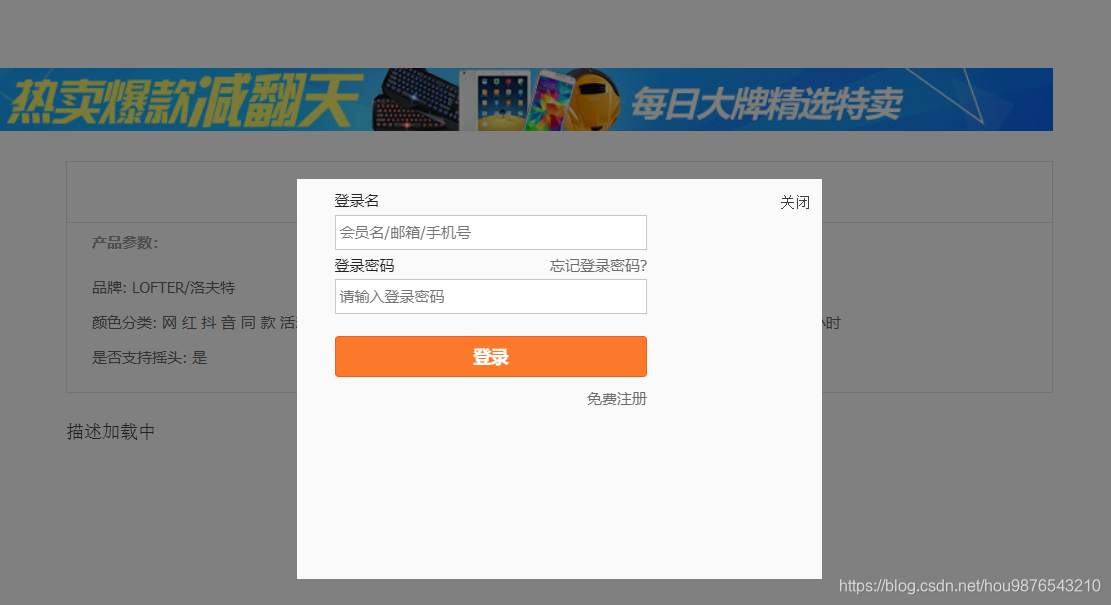
在两三年之前天猫,淘宝,美团等这类的没有加密,很容易采集到数据,刚写了个爬取天猫评论时候,发现不能获取json类的数据,用了所以我用selenium,效果还不错,我们创建对象后,会让我们登录(如下图所示),开始我的思路是点击让它关闭,但是获取不到 关闭 (看源代码想到的iframe定位),又换了一种方式,使用execute_script()方法添加属性display:none ; 本篇数据没储存(可以参考之前博客写的储存) 不说太多 上图上代码
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
import time
import random
import re
import codecs
import csv
browser = webdriver.Chrome()
# 创建等待对象
wait = WebDriverWait(browser, 60)
browser.maximize_window()
url = 'https://detail.tmall.com/item.htm?id=613496331701&ali_refid=a3_430582_1006:1105301367:N:aEuKxt8KFNFlmiouOf%20%20ow==:dbecb924121b493297350f8b4047a699&ali_trackid=1_dbecb924121b493297350f8b4047a699&spm=a230r.1.14.1&skuId=4536332663234'
browser.get(url)
# 关闭登录框
wait.until(
EC.presence_of_element_located((By.CLASS_NAME, "sufei-dialog"))
)
login = browser.find_elements_by_class_name("sufei-dialog")
if len(login)>0:
myjs = '''
var x = document.getElementsByClassName("sufei-dialog");
x[0].setAttribute("style","display:none");
'''
browser.execute_script(myjs)
# 点击评论
js="var q=document.documentElement.scrollTop=800"
browser.execute_script(js)
time.sleep(random.random()*6)
wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="J_TabBar"]/li[2]'))
)
but = browser.find_element_by_xpath('//*[@id="J_TabBar"]/li[2]')
but.click()
time.sleep(random.random()*9)
# 获取评论内容
while True:
ls = browser.find_elements_by_xpath('//*[@id="J_Reviews"]/div/div[6]/table/tbody/tr')
print('len:',len(ls))
for each in ls:
plun = each.find_element_by_xpath('.//div[@class="tm-rate-fulltxt"]').get_attribute("innerText") if len(each.find_element_by_xpath('.//div[@class="tm-rate-fulltxt"]').get_attribute("innerText"))> 0 else None
name = each.find_element_by_xpath('.//div[@class="rate-user-info"]').get_attribute("innerText") if len(each.find_element_by_xpath('.//div[@class="rate-user-info"]').get_attribute("innerText"))> 0 else None
print(name + plun)
time.sleep(random.random()*6)
wait.until(
EC.presence_of_element_located((By.XPATH, '//div[@class="rate-paginator"]/a[contains(text(),"下一页")]'))
)
pages = browser.find_elements_by_xpath('//div[@class="rate-paginator"]/a[contains(text(),"下一页")]')
if len(pages)>0:
pages[0].click()
else:
break
time.sleep(random.random()*3)

版权声明:本文为hou9876543210原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。