Background
在2D的检测中,获得当前检测目标的Bbox(Bounding box)的中心点周围往往都有实际的像素存在。但是在3D的检测中,3D传感器的成像特性都是只可以对表面进行扫描,在我物体的中心周围不会存在实际的点。因此直接在3D空间中寻找Bbox面临这巨大的挑战。在这样的基础下,作者提出了VoteNet,将Hough Voting的方法运用到了3D目标检测当中。这种方法也被3DIoUMatch和SESS作为点云特征提取的方法。
Progress
- 提出了一种端到端的可微架构,在3D点云中成功使用霍夫投票的方法
- 在SUN RGB-D和ScanNet上取得了好的成绩
- 深入分析了投票方法对3D目标检测的重要性
VoteNet Pipline
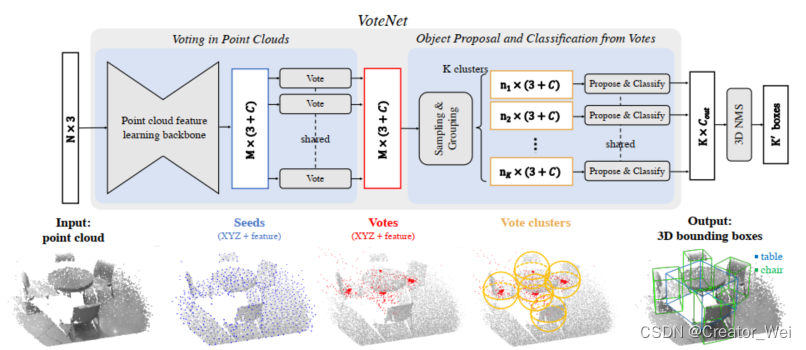
VoteNet Architecture
在上图的Pipline中可以看出,VoteNet主要分为两个部分,分别是Voting Point Clouds和Object proposal and classification from votes。前半部分的主要作用是得到预测点,后半部分的作用是根据预测点给出分类结果
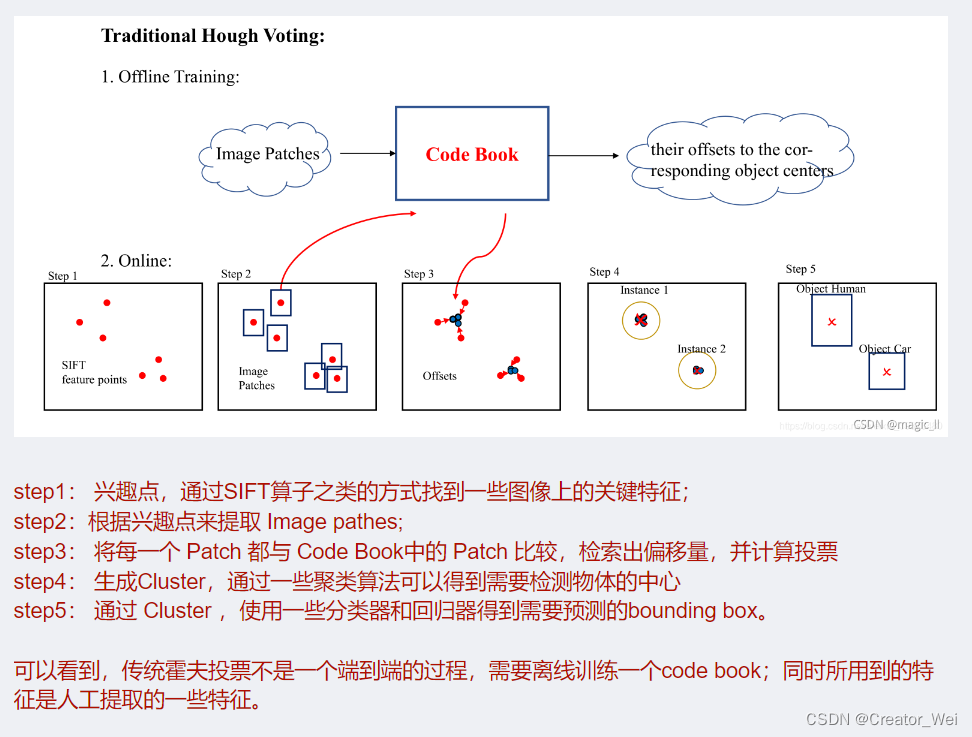
Hough Voting的基本理解
这里我参照了
这个文章
理解霍夫投票,这里的图示可以方便的表示出霍夫投票的过程,不得不说这个图很形象了。
Voting in Point Clouds

在Voting in point clouds中分为两个部分,一部分是点云特征提取层,另一部分是投票层。其中在点云特征提取层使用了
PointNet++
作为backbone。输入为点云大小为
。在经过
PointNet++
之后,输出大小为
(其中M为种子点个数),同事每个种子点还会生成一个Vote。其中的PointNet++的基本结构如下图
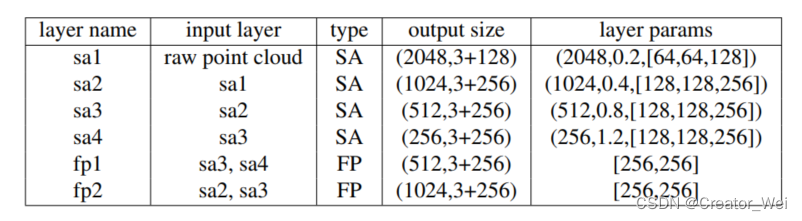
具体代码如下:
class Pointnet2Backbone(nn.Module):
r"""
Backbone network for point cloud feature learning.
Based on Pointnet++ single-scale grouping network.
Parameters
----------
input_feature_dim: int
Number of input channels in the feature descriptor for each point.
e.g. 3 for RGB.
"""
def __init__(self, input_feature_dim=0):
super().__init__()
self.sa1 = PointnetSAModuleVotes(
npoint=2048, #中心点数量
radius=0.2, #半径
nsample=64, #采样点数量
mlp=[input_feature_dim, 64, 64, 128], #mlp
use_xyz=True,
normalize_xyz=True
)
self.sa2 = PointnetSAModuleVotes(
npoint=1024,
radius=0.4,
nsample=32,
mlp=[128, 128, 128, 256],
use_xyz=True,
normalize_xyz=True
)
self.sa3 = PointnetSAModuleVotes(
npoint=512,
radius=0.8,
nsample=16,
mlp=[256, 128, 128, 256],
use_xyz=True,
normalize_xyz=True
)
self.sa4 = PointnetSAModuleVotes(
npoint=256,
radius=1.2,
nsample=16,
mlp=[256, 128, 128, 256],
use_xyz=True,
normalize_xyz=True
)
self.fp1 = PointnetFPModule(mlp=[256+256,256,256])
self.fp2 = PointnetFPModule(mlp=[256+256,256,256])
def _break_up_pc(self, pc):
xyz = pc[..., 0:3].contiguous()
features = (
pc[..., 3:].transpose(1, 2).contiguous()
if pc.size(-1) > 3 else None
)
return xyz, features
def forward(self, pointcloud: torch.cuda.FloatTensor, end_points=None):
r"""
Forward pass of the network
Parameters
----------
pointcloud: Variable(torch.cuda.FloatTensor)
(B, N, 3 + input_feature_dim) tensor
Point cloud to run predicts on
Each point in the point-cloud MUST
be formated as (x, y, z, features...)
Returns
----------
end_points: {XXX_xyz, XXX_features, XXX_inds}
XXX_xyz: float32 Tensor of shape (B,K,3)
XXX_features: float32 Tensor of shape (B,K,D)
XXX-inds: int64 Tensor of shape (B,K) values in [0,N-1]
"""
if not end_points: end_points = {}
batch_size = pointcloud.shape[0]
xyz, features = self._break_up_pc(pointcloud)
# --------- 4 SET ABSTRACTION LAYERS ---------
xyz, features, fps_inds = self.sa1(xyz, features)
end_points['sa1_inds'] = fps_inds
end_points['sa1_xyz'] = xyz
end_points['sa1_features'] = features
xyz, features, fps_inds = self.sa2(xyz, features) # this fps_inds is just 0,1,...,1023
end_points['sa2_inds'] = fps_inds
end_points['sa2_xyz'] = xyz
end_points['sa2_features'] = features
xyz, features, fps_inds = self.sa3(xyz, features) # this fps_inds is just 0,1,...,511
end_points['sa3_xyz'] = xyz
end_points['sa3_features'] = features
xyz, features, fps_inds = self.sa4(xyz, features) # this fps_inds is just 0,1,...,255
end_points['sa4_xyz'] = xyz
end_points['sa4_features'] = features
# --------- 2 FEATURE UPSAMPLING LAYERS --------
features = self.fp1(end_points['sa3_xyz'], end_points['sa4_xyz'], end_points['sa3_features'], end_points['sa4_features'])
features = self.fp2(end_points['sa2_xyz'], end_points['sa3_xyz'], end_points['sa2_features'], features)
end_points['fp2_features'] = features
end_points['fp2_xyz'] = end_points['sa2_xyz']
num_seed = end_points['fp2_xyz'].shape[1]
end_points['fp2_inds'] = end_points['sa1_inds'][:,0:num_seed] # indices among the entire input point clouds
return end_points
if __name__=='__main__':
backbone_net = Pointnet2Backbone(input_feature_dim=3).cuda()
print(backbone_net)
backbone_net.eval()
out = backbone_net(torch.rand(16,20000,6).cuda())
for key in sorted(out.keys()):
print(key, '\t', out[key].shape)
投票层使用MLP将种子点生成Vote。其中MLP以种子点特征
作为输入,并且输出在欧式空间下的
偏移量和特征偏移量
。这两个偏移量加上原本的坐标和特征便成为了Vote。也就是
和
。对于预测的Loss如下:

代码如下:
class VotingModule(nn.Module):
def __init__(self, vote_factor, seed_feature_dim):
""" Votes generation from seed point features.
Args:
vote_facotr: int
number of votes generated from each seed point
seed_feature_dim: int
number of channels of seed point features
vote_feature_dim: int
number of channels of vote features
"""
super().__init__()
self.vote_factor = vote_factor
self.in_dim = seed_feature_dim #种子点维度
self.out_dim = self.in_dim # due to residual feature, in_dim has to be == out_dim
self.conv1 = torch.nn.Conv1d(self.in_dim, self.in_dim, 1)
self.conv2 = torch.nn.Conv1d(self.in_dim, self.in_dim, 1)
self.conv3 = torch.nn.Conv1d(self.in_dim, (3+self.out_dim) * self.vote_factor, 1)
self.bn1 = torch.nn.BatchNorm1d(self.in_dim)
self.bn2 = torch.nn.BatchNorm1d(self.in_dim)
def forward(self, seed_xyz, seed_features):
""" Forward pass.
Arguments:
seed_xyz: (batch_size, num_seed, 3) Pytorch tensor
seed_features: (batch_size, feature_dim, num_seed) Pytorch tensor
Returns:
vote_xyz: (batch_size, num_seed*vote_factor, 3)
vote_features: (batch_size, vote_feature_dim, num_seed*vote_factor)
"""
batch_size = seed_xyz.shape[0] # batch_size
num_seed = seed_xyz.shape[1] # num_seed
num_vote = num_seed*self.vote_factor # num_vote 投票的数量=num_seed*vote_factor
net = F.relu(self.bn1(self.conv1(seed_features)))
net = F.relu(self.bn2(self.conv2(net)))
net = self.conv3(net) # (batch_size, (3+out_dim)*vote_factor, num_seed)
net = net.transpose(2,1).view(batch_size, num_seed, self.vote_factor, 3+self.out_dim) #求反转矩阵
offset = net[:,:,:,0:3]
vote_xyz = seed_xyz.unsqueeze(2) + offset #加入偏移量
vote_xyz = vote_xyz.contiguous().view(batch_size, num_vote, 3)
residual_features = net[:,:,:,3:] # (batch_size, num_seed, vote_factor, out_dim)
vote_features = seed_features.transpose(2,1).unsqueeze(2) + residual_features
vote_features = vote_features.contiguous().view(batch_size, num_vote, self.out_dim) #拷贝数据
vote_features = vote_features.transpose(2,1).contiguous()
return vote_xyz, vote_features在上面的步骤中,作者给出了一个比较形象化的图示表示,其中不同颜色的字代表不同的部分

Object Proposal and classification from votes
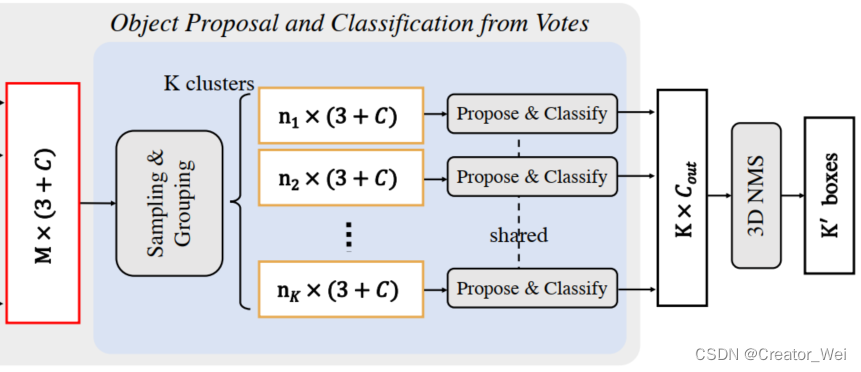
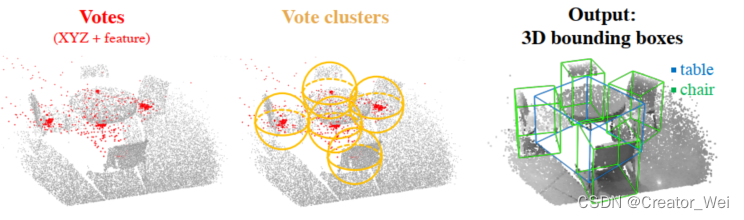
在此部分主要目的是为了聚类之前的投票,并且对他们的特征对象进行分类。在这个过程中,VoteNet根据之前的种子点和种子点的投票结果来产生聚类的结果。
在此步骤中首先使用类似于PointNet++中的方法对当前的数据进行了Sampling & Grouping(其中分为两部分,分别是
的点云和
特征)。其中Sampling使用FPS的方法选出K个中心点。之后的Grouping和PointNet++中一样,使用BallQyery的方法来产生根据之前的K个中心点的聚类结果。
在Object Proposal阶段使用了MLP,通过之前在Sampling & Grouping产生的K个聚类的结果提取特征并。在这里,每个点都进行了坐标的变换,从全局坐标系转换到了当前Group所在的中心点的相对坐标系下。之后传入PointNet++的模块中进行运算。在MLP1中的输出被最大池化并传给MLP2中使用。具体公式如下:
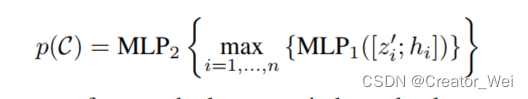
代码如下:
class ProposalModule(nn.Module):
def __init__(self, num_class, num_heading_bin, num_size_cluster, mean_size_arr, num_proposal, sampling, seed_feat_dim=256):
super().__init__()
self.num_class = num_class
self.num_heading_bin = num_heading_bin
self.num_size_cluster = num_size_cluster
self.mean_size_arr = mean_size_arr
self.num_proposal = num_proposal
self.sampling = sampling
self.seed_feat_dim = seed_feat_dim
# Vote clustering
# decoder
self.vote_aggregation = PointnetSAModuleVotes(
npoint=self.num_proposal,
radius=0.3,
nsample=16,
mlp=[self.seed_feat_dim, 128, 128, 128],
use_xyz=True,
normalize_xyz=True
)
# Object proposal/detection
# Objectness scores (2), center residual (3),
# heading class+residual (num_heading_bin*2), size class+residual(num_size_cluster*4)
self.conv1 = torch.nn.Conv1d(128,128,1)
self.conv2 = torch.nn.Conv1d(128,128,1)
self.conv3 = torch.nn.Conv1d(128,2+3+num_heading_bin*2+num_size_cluster*4+self.num_class,1)
self.bn1 = torch.nn.BatchNorm1d(128)
self.bn2 = torch.nn.BatchNorm1d(128)
def forward(self, xyz, features, end_points):
"""
Args:
xyz: (B,K,3)
features: (B,C,K)
Returns:
scores: (B,num_proposal,2+3+NH*2+NS*4)
"""
if self.sampling == 'vote_fps':
# Farthest point sampling (FPS) on votes
xyz, features, fps_inds = self.vote_aggregation(xyz, features)
sample_inds = fps_inds
elif self.sampling == 'seed_fps':
# FPS on seed and choose the votes corresponding to the seeds
# This gets us a slightly better coverage of *object* votes than vote_fps (which tends to get more cluster votes)
sample_inds = pointnet2_utils.furthest_point_sample(end_points['seed_xyz'], self.num_proposal)
xyz, features, _ = self.vote_aggregation(xyz, features, sample_inds)
elif self.sampling == 'random':
# Random sampling from the votes
num_seed = end_points['seed_xyz'].shape[1]
batch_size = end_points['seed_xyz'].shape[0]
sample_inds = torch.randint(0, num_seed, (batch_size, self.num_proposal), dtype=torch.int).cuda()
xyz, features, _ = self.vote_aggregation(xyz, features, sample_inds)
else:
log_string('Unknown sampling strategy: %s. Exiting!'%(self.sampling))
exit()
end_points['aggregated_vote_xyz'] = xyz # (batch_size, num_proposal, 3)
end_points['aggregated_vote_inds'] = sample_inds # (batch_size, num_proposal,) # should be 0,1,2,...,num_proposal
# --------- PROPOSAL GENERATION ---------
net = F.relu(self.bn1(self.conv1(features)))
net = F.relu(self.bn2(self.conv2(net)))
net = self.conv3(net) # (batch_size, 2+3+num_heading_bin*2+num_size_cluster*4, num_proposal)
end_points = decode_scores(net, end_points, self.num_class, self.num_heading_bin, self.num_size_cluster, self.mean_size_arr)
return end_points在上面的步骤中,作者给出了一个比较形象化的图示表示,其中不同颜色的字代表不同的部分
Loss
对于目标检测结果:交叉熵损失函数
对于Bbox的预测结果:交叉熵损失函数
Experiments
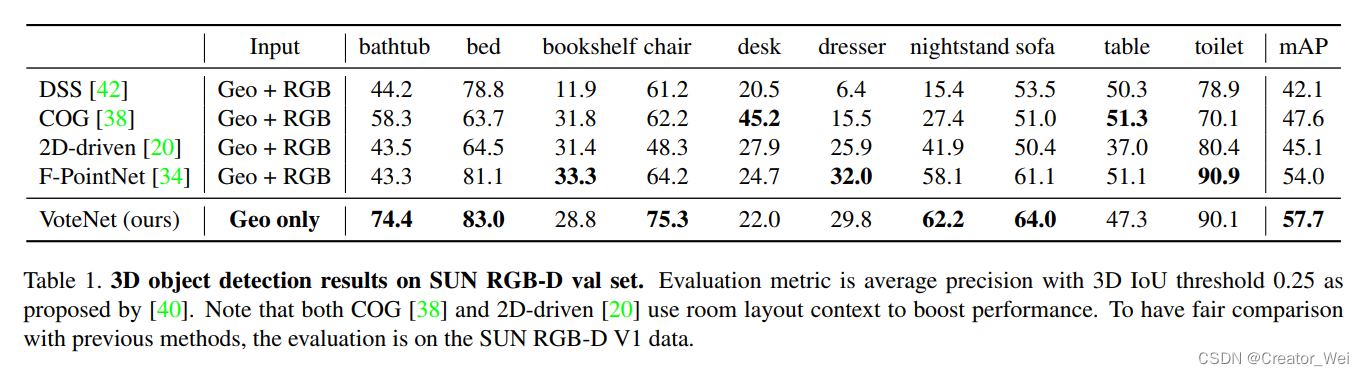
作者在SUN RGB-D上实验了自己的结果,并对比了不同的方法。结果如下图所示:
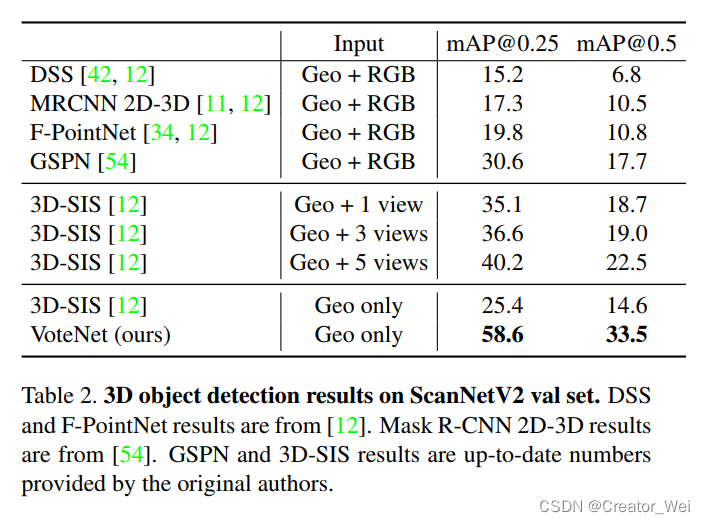
同事,作者也在ScanNetV2上验证了自己的实验结果:
除此之外,作何为了验证Hough Vote确实在实验中起到了最用,并且为了证明投票的效果确实要优于不投票的效果,作者还引入了BoxNet的对比。对比结果如下:

Improvement
这篇文章可以说是PointNet和PointNet++的延续,之后也在SESS和3DIoU中有使用,我也是看到后面这两篇文章才开始关注VoteNet的。但是这篇文章可能有几点我认为可以提升的地方,当然也在之后的一些文章中有证实。因为VoteNet是使用的传统的聚类方法,如果在一些障碍物比较密集的场景中可能VoteNet的结果不是很好。因为聚类策略会收到周围的障碍物的影响,因此投票结果也会受到影响,最终导致准确率下降。