用户分层
1、分层实施的两大核心
- 处于不同层级的用户,需要能够被通过数据字段或标签等方式识别区分出来;
- 面向每一类用户的运营机制或策略是明确稳定的。
用户分层和用户分群的区别
用户分层是以用户价值为中心,在同一分层模型下,一个用户只会处于一个层级
用户分群是以用户属性为中心划分,一个用户会同时拥有多个属性。
2、分层的原则
- 科学性:正确有效的统计模型
- 可解释性:分层界限具有业务意义
- 业务适用性:可操作性强,业务覆盖广
3、分层的方法
| 方法名称 | 适用场景 | 方法内容 |
|---|---|---|
| 用户价值区隔分层 | 业务链条标准化高,用户间互相影响低 |
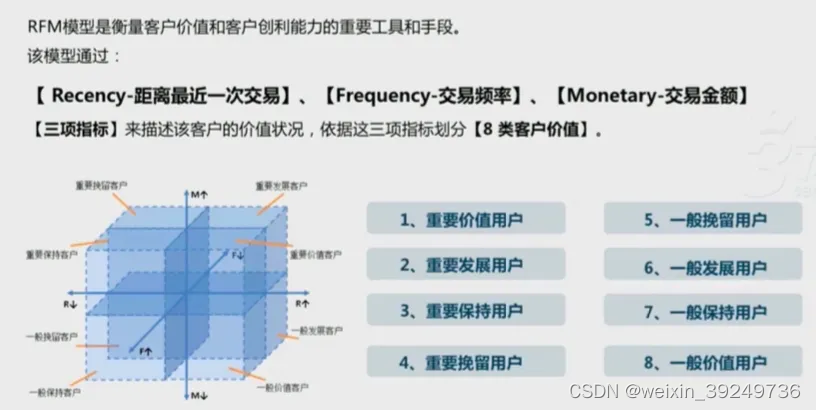
|
| AAARR模型分层 | 业务链条标准化高,用户间互相影响低 |
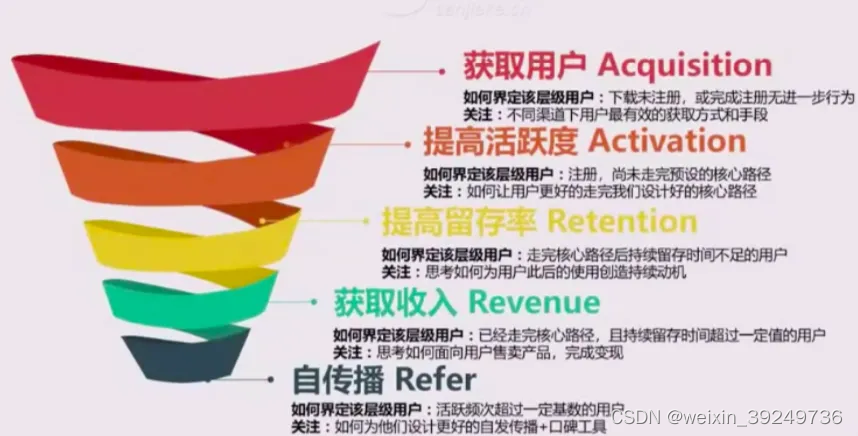
|
| 金字塔模型 |
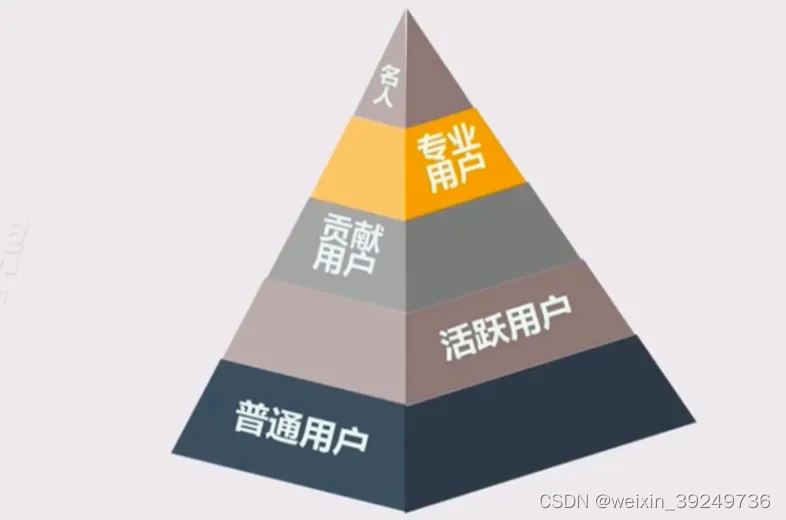
|
|
| 用个性化特质&需求区分 | 业务链条标准化低 |
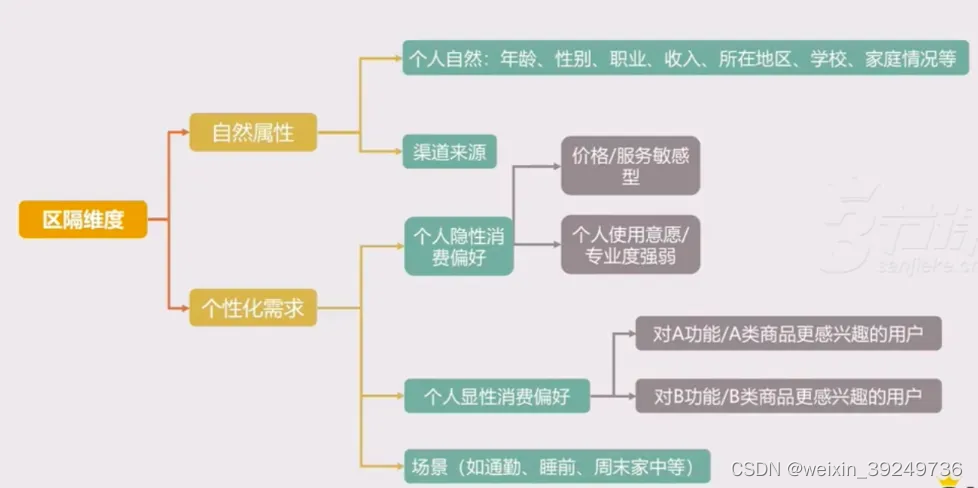
|
| 以用户成长路径为中心 | 标准化高 互相影响高 |
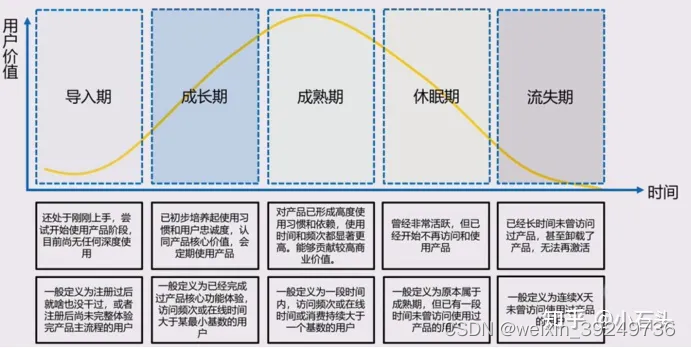
|
4、分层的流程
4.1 用户价值区隔流程
-
确定分层指标
观测周期确定的原则:
指标的累积覆盖度
足够大(接近100%),且
指标的覆盖度增量
收敛(趋于稳定)
【目标用户有目标行为日日均行为指标】 表示用户一段时间内的平均能力
【目标用户每日行为指标】、目标用户观测周期累积行为指标】表示用户一段时间内的累积能力
【目标用户当日行为指标】表示当日的能力
eg:
● 最近30天付费日日均付费金额、最近30天自然日日均付费金额、最近30天付费天数
● 最近30天区间的诜择:近30天付费用户对观测日非首次消费人数贡献度93.2%(覆盖度足够大),金额贡献度97.2%,且增量收敛(覆盖度随着天数的增加增速趋于平缓);
○ 累积覆盖度
■ 当日新付费用户,在t日人数占比~1.7%,金额占比~1.5%
■ 历史付费用户在t日,人数占比~98.3%,金额占比~98.5%(下图为剔除新付费用户的累计占比,即最终收敛至100%,因展示限制下图为近40天)
○ 覆盖度增量:
■ 14天以上人数占比增量约在0.2pp,金额占比增量约在0.4pp;
■ 30天以上人数、金额占比增量均收敛至0.1pp;
- 圈定分层对象:观测周期内有目标行为的对象
-
选择分层方法:
帕累托最适
(适用于价值累积型变量指标)
帕累托最适(Pareto efficiency)
● 分层临界值涵意为上下两能力分层区间的最公平能力分配状态,用户能力透过向分层临界值靠近的帕累托改进过程,逐渐达到效率分配,直到帕累托最适状态;
● 通过比较能力人数分布、能力值分布,计算临界值;超过临界值意味著多数能力集中于少数人,低于临界值意味著少数能力分散于多数人之中;
eg:
y1:人数占比
y2:收入占比
交点表示:收入占比=人数占比;左侧代表人数占比>收入占比,多数人拥有少数财富
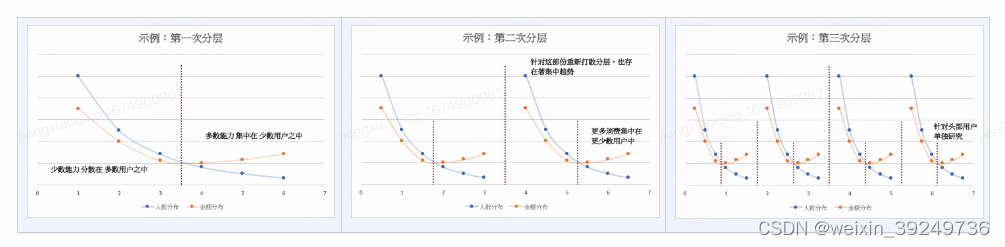
-
分层特性
● 稳定性:用户在稳定的环境中,所属层级稳定不会小概率出现大的波动
● 分层数量:满足精细化运营,分层不宜过少 -
模型构建
● 付费金额与付费人数是典型的价值累积型变量,符合Pareto准则,服从Power law分布;
Power law分布中,随机变量的X的概率密度函数为:
P
(
X
>
x
)
=
(
x
m
i
n
/
x
)
k
P(X>x) = (x_{min}/x)^{k}
P
(
X
>
x
)
=
(
x
min
/
x
)
k
注:t分布是也是幂律分布