一、深度学习基础知识
1. 深度学习发展历史
以史为鉴可以知兴替
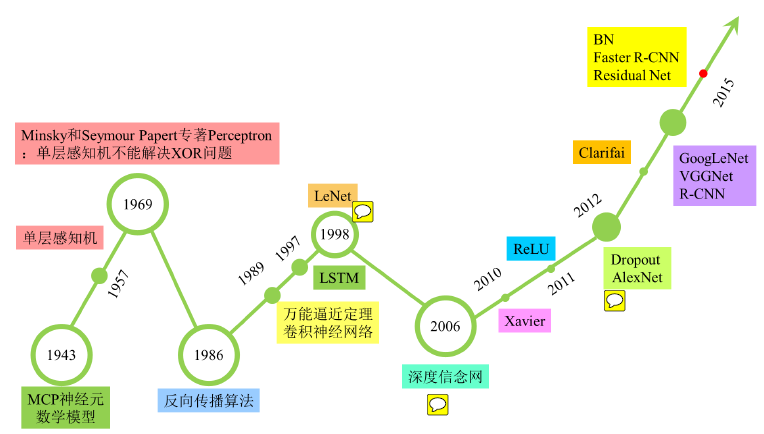
由上图可以看到,DL经历了三次热潮两次低谷。
第一代神经网络(1943~1969)
起源
最早的神经网络的思想起源于1943年神经科学家麦卡洛克(W.S.McCilloch) 和数学家皮兹(W.Pitts)在《数学生物物理学公告》上发表的论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of the Ideas Immanent in Nervous Activity)。文中建立的神经网络和数学模型,MCP人工神经元模型,当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)。如下图所示

发展
计算机科学家罗森布拉特( Rosenblatt)提出了两层神经元组成的神经网络,称之为“感知器”(Perceptrons)。第一次将MCP用于机器学习(machine learning)分类(classification)。“感知器”算法算法使用MCP模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。
第一次低谷
1969年,美国数学家及人工智能先驱 Marvin Minsky 在其著作中证明了感知器本质上是一种线性模型(linear model),只能处理线性分类问题,就连最简单的XOR(亦或)问题都无法正确分类。这等于直接宣判了感知器的死刑,神经网络的研究也陷入了将近20年的停滞。
冷静期(1969~1986)
山重水复疑无路
期间研究人员们并没有放弃对人工智能的追求,人们都在寻求出路,其研究方向也开始分裂,主要分为三派:1.连接主义学派;2.贝叶斯学派;3.类推学派。尤其是后两个学派在这个时期得到了大量新鲜血液的注入,这也为其1986年以后的崛起积淀了力量。
其中连接主义学派仍坚持主张用人工神经网络神经网络实现人工智能,但由于感知器无法解决非线性问题的打击,因此理论发展缓慢。
期间1980年。基于传统的感知器结构,深度学习创始人,加拿大多伦多大学教授杰弗里·辛顿(G. Hinton)采用多个隐含层的深度结构来代替代感知器的单层结构,多层感知器模型(Multi_Layer Perceptron)是其中最具代表性的,而且多层感知器也是最早的深度学习网络模型。1974年,Paul Werbos提出采用反向传播法来训练一般的人工神经网络,随后,该算法进一步被杰弗里·辛顿、燕·勒存(Y. LeCun)等人应用于训练具有深度结构的神经网络。
第二代神经网络(1986~1998)
破茧
雄关漫道真如铁,而今迈步从头越
第一次打破非线性诅咒的当属现代DL大牛Hinton,其在1986年发明了适用于多层感知器(MLP)的BP算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。该方法引起了神经网络的第二次热潮。鉴于现实生活中绝大部分的实际问题都是非线性的,因此可以说BP算法的发明使神经网络在真正能够解决实际问题的,犹如漫漫长夜般的探索中点亮了希望的曙光,是谓破茧。
1989年,Robert Hecht-Nielsen证明了MLP的万能逼近定理:1.如果一个隐层包含足够多的神经元,三层前馈神网络(输入-隐层-输出)能够以任意精度逼近任意预定的连续函数。2.当隐层足够宽时,双隐层感知器(输入-隐层-隐层-输出)可以逼近任意非连续函数。该定理的发现极大的鼓舞了神经网络的研究人员。
也是在1989年,LeCun发明了卷积神经网络-LeNet,并将其用于数字识别,且取得了较好的成绩,不过当时并没有引起足够的注意。而现如今
,该网络被用于各大银行和教育机构中。
第二次低谷(1998~2006)
山雨欲来风满楼
在1989年以后由于没有特别突出的方法被提出,且NN一直缺少相应的严格的数学理论支持,神经网络的热潮渐渐冷淡下去。冰点来自于1991年,BP算法被指出存在梯度消失问题,即在误差梯度后向传递的过程中,后层梯度以乘性方式叠加到前层,由于Sigmoid函数的饱和特性,后层梯度本来就小,误差梯度传到前层时几乎为0,因此无法对前层进行有效的学习,该发现对此时的NN发展雪上加霜。
反向传播法根据神经网络输出层的计算误差来调整网络的权值,直到计算误差收敛为止。但是,反向传播法训练具有多隐含层的深度网络的网络参数的学习性能并不好,因为具有多隐含层的深度网络的网络参数的训练问题是一个非凸问题,基于梯度下降的反向传播法很容易在训练网络参数时收敛于局部极小值。此外,反向传播法训练网络参数还存在很多实际问题,比如需要大量的标签样本来训练网络的权值,多隐含层的神经网络权值的训练速度很慢,权值的修正随着反向传播层数的增加逐渐削弱等。
贝叶斯学派和类推学派的崛起
面对采用反向传播法来训练具有多隐含层的深度网络的网络参数时存在的缺陷,一部分研究人员开始探索通过改变感知器的结构来改善网络学习的性能,由此产生了很多著名的单隐含层的浅层学习模型,如SVM、logistic regression、Maximum entropy model和朴素贝叶斯模型等。
1986年,决策树方法被提出,很快ID3,ID4,CART等改进的决策树方法相继出现,到目前仍然是非常常用的一种机器学习方法。该方法也是符号学习方法的代表。
1995年,线性SVM被统计学家Vapnik提出。该方法的特点有两个:由非常完美的数学理论推导而来(统计学与凸优化等),符合人的直观感受(最大间隔)。不过,最重要的还是该方法在线性分类的问题上取得了当时最好的成绩。
SVM发现的参与者Isabelle Guyon自述的一个小故事:
那时,所有人都围绕多层感知器(深度学习的雏形)开展研究,我在边缘算法上的第一项工作是受minover的启发,简化一些有效集方法来优化边缘检测,我的丈夫Bernhard甚至还为多层感知器设计了专用的硬件!我和Vapnik就此展开了热烈的讨论,他和我一个办公室,那会儿正忙着推销他在60年代发明的另一种边缘算法。Bernhard决定使用Vapnik的算法。在线性算法上获得初步的成功后,Vapnik建议引入特征的积,而我提出用隐函数算法的核技巧(kernel trick)更好。Vapnik起初很反对,因为隐函数算法的发明者(Aizerman、Braverman和Rozonoer)所在的团队是他60年代在俄罗斯呆的那个研究所的死对头。最后Bernhard还是尝试了,SVM也就诞生了!
1997年,AdaBoost被提出,该方法是PAC(Probably Approximately Correct)理论在机器学习实践上的代表,也催生了集成方法这一类。该方法通过一系列的弱分类器集成,达到强分类器的效果。
2000年,KernelSVM被提出,核化的SVM通过一种巧妙的方式将原空间线性不可分的问题,通过Kernel映射成高维空间的线性可分问题,成功解决了非线性分类的问题,且分类效果非常好。至此也更加终结了NN时代。
2001年,随机森林被提出,这是集成方法的另一代表,该方法的理论扎实,比AdaBoost更好的抑制过拟合问题,实际效果也非常不错。
2001年,一种新的统一框架-图模型被提出,该方法试图统一机器学习混乱的方法,如朴素贝叶斯,SVM,隐马尔可夫模型等,为各种学习方法提供一个统一的描述框架。
第三代神经网络DeepLearning(2006~至今)
长风破浪会有时,直挂云帆济沧海
快速发展期(2006~2012)
2006年,DL元年。是年,Hinton提出了深层网络训练中梯度消失问题的解决方案:无监督预训练对权值进行初始化+有监督训练微调。其主要思想是先通过自学习的方法学习到训练数据的结构(自动编码器),然后在该结构上进行有监督训练微调。但是由于没有特别有效的实验验证,该论文并没有引起重视。
2011年,ReLU激活函数被提出,该激活函数能够有效的抑制梯度消失问题。
2011年,微软首次将DL应用在语音识别上,取得了重大突破。微软研究院和Google的语音识别研究人员先后采用DNN技术降低语音识别错误率20%~30%,是语音识别领域十多年来最大的突破性进展。2012年,DNN技术在图像识别领域取得惊人的效果,在ImageNet评测上将错误率从26%降低到15%。在这一年,DNN还被应用于制药公司的DrugeActivity预测问题,并获得世界最好成绩。
爆发期(2012~至今)
2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引到了众多研究者的注意。
AlexNet的创新点:
(1)首次采用ReLU激活函数,极大增大收敛速度且从根本上解决了梯度消失问题;(2)由于ReLU方法可以很好抑制梯度消失问题,AlexNet抛弃了“预训练+微调”的方法,完全采用有监督训练。也正因为如此,DL的主流学习方法也因此变为了纯粹的有监督学习;(3)扩展了LeNet5结构,添加Dropout层减小过拟合,LRN层增强泛化能力/减小过拟合;(4)首次采用GPU对计算进行加速;
2013,2014,2015年,通过ImageNet图像识别比赛,DL的网络结构,训练方法,GPU硬件的不断进步,促使其在其他领域也在不断的征服战场。
2015年,Hinton,LeCun,Bengio论证了局部极值问题对于DL的影响,结果是Loss的局部极值问题对于深层网络来说影响可以忽略。该论断也消除了笼罩在神经网络上的局部极值问题的阴霾。具体原因是深层网络虽然局部极值非常多,但是通过DL的BatchGradientDescent优化方法很难陷进去,而且就算陷进去,其局部极小值点与全局极小值点也是非常接近。
2015,DeepResidualNet发明。分层预训练,ReLU和BatchNormalization都是为了解决深度神经网络优化时的梯度消失或者爆炸问题。但是在对更深层的神经网络进行优化时,又出现了新的Degradation问题,即”通常来说,如果在VGG16后面加上若干个单位映射,网络的输出特性将和VGG16一样,这说明更深次的网络其潜在的分类性能只可能>=VGG16的性能,不可能变坏,然而实际效果却是只是简单的加深VGG16的话,分类性能会下降(不考虑模型过拟合问题)“Residual网络认为这说明DL网络在学习单位映射方面有困难,因此设计了一个对于单位映射(或接近单位映射)有较强学习能力的DL网络,极大的增强了DL网络的表达能力。此方法能够轻松的训练高达150层的网络。
2016年3月,由谷歌(Google)旗下DeepMind公司开发的AlphaGo(基于深度学习)与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册帐号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩;2017年5月,在中国乌镇围棋峰会上,它与排名世界第一的世界围棋冠军柯洁对战,以3比0的总比分获胜。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平。
参考链接
1.https://blog.csdn.net/u012177034/article/details/52252851
2.https://blog.csdn.net/lqfarmer/article/details/72622348
3.https://www.sohu.com/a/108373671_218897
4.http://blog.sciencenet.cn/blog-3377239-1129327.html
5.https://www.sohu.com/a/117196433_224832