Video Swin Transformer
文章链接:
https://arxiv.org/abs/2106.13230
代码链接:
https://github.com/SwinTransformer/Video-Swin-Transformer
介绍
本文提出的Video Swin Transformer,严格遵循原始Swin Transformer的层次结构,但将局部注意力计算的范围从空间域扩展到时空域。由于局部注意力是在非重叠窗口上计算的,因此原始Swin Transformer的滑动窗口机制也被重新定义了,以适应时间和空间两个域的信息。
在时空距离上更接近的像素更有可能相关
,作者在网络结构中利用了这个假设偏置,所以达到了更高的建模效率。
架构
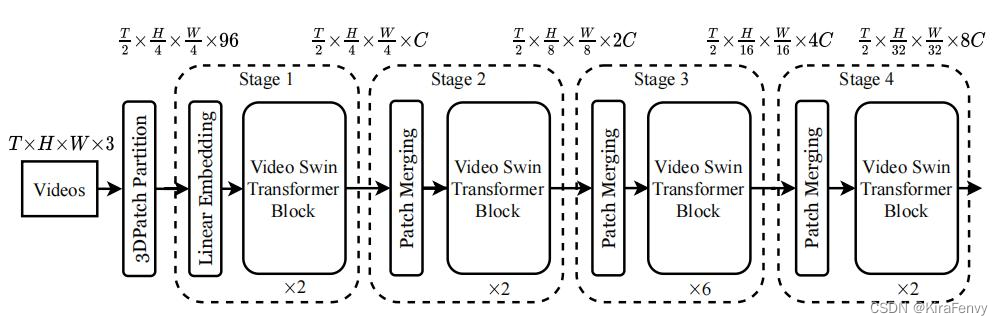
Video Swin Transformer的总体结构如上图所示。输入的视频数据为
T
×
H
×
W
×
3
T×H×W×3
T
×
H
×
W
×
3
的张量,由T帧的
H
×
W
×
3
H×W×3
H
×
W
×
3
的图片组成。在Video Swin Transformer中,作者用的3D patch的大小为$ 2×4×4×3$,因此就可以得到
T
/
2
×
H
/
4
×
W
/
4
×
3
T/2×H/4×W/4×3
T
/2
×
H
/4
×
W
/4
×
3
个 3D Patch,然后用线性embedding层将特征映射到维度为C的token embedding。
为了能够严格遵循Swin Transformer的层次结构,作者在时间维度上没有进行降采样,每个stage只在空间维度上进行了
2
×
2
2×2
2
×
2
的降采样。Patch合并层连接每组2×2个空间相邻patch的特征,并应用一个线性层将连接的特征投影到原来通道尺寸的一半。例如,第二阶段中的线性层将每个通道维度为4C的token映射为2C。
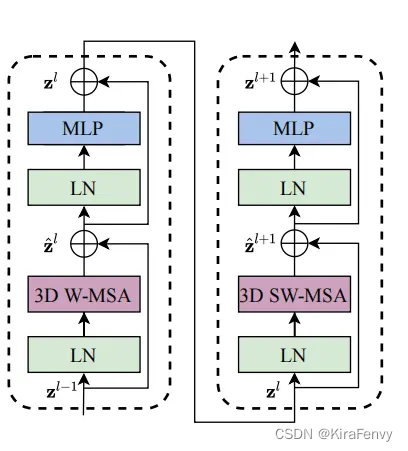
该体系结构的主要组件是 Video Swin Transformer block,这个模块就是
将Transformer中 multi-head self-attention (MSA)替换成了基于3D滑动窗口的MSA模块
。具体地说,一个
Video Transformer block
由一个基于
3D滑动窗口的MSA模块和一个前馈网络(FFN)
组成,其中
FFN由两层的MLP和激活函数GELU组成
。
Layer Normalization(LN)被用在每个MSA和FFN模块之前,残差连接被用在了每个模块之后
。
3.2 3D Shifted Window based MSA Module
与图像相比,视频需要更多的输入token来表示它们,因为视频另外有一个时间维度。因此,一个全局的自注意模块将不适合视频任务,因为这将导致巨大的计算和内存成本。在这里,作者遵循Swin Transformer的方法,在自注意模块中引入了一个局部感应偏置。
3.2.1 在不重叠的三维窗口上的MSA
在每个不重叠的二维窗口上的MSA机制已被证明对图像识别是有效并且高效的。在这里,作者直接扩展了这种设计到处理视频输入中。给定一个由
T
’
×
H
′
×
W
′
T’×H’×W’
T
’
×
H
′
×
W
′
个3D token组成的视频,3D窗口大小为
P
×
M
×
M
P×M×M
P
×
M
×
M
,这些窗口以不重叠的方式均匀地分割视频输入。这些token被分成了多个不重叠的3D窗口。
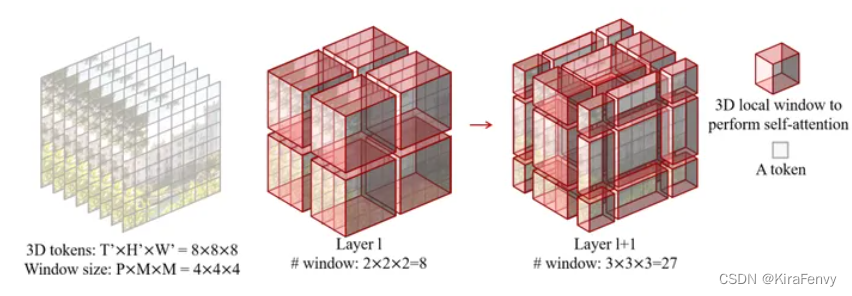
如上图(中)所示,对于输入大小为8×8×8的token和窗口大小为4×4×4,第
层中的窗口数将为2×2×2=8。
3.2.2 3D Shifted Windows
由于在每个不重叠的三维窗口中都应用了多头自注意机制,因此缺乏跨不同窗口的关系建模,这可能会限制特征的表示能力。因此,作者将Swin Transformer的移位二维窗口(shifted 2D window)机制扩展到3D窗口,以引入跨窗口连接,同时保持基于非重叠自注意的高效窗口计算。
对于Self-Attention模块的第一层,就如上面所示采用均匀分块的方式。对于第二层,窗口分区配置沿着来自上一层自注意模块的时间、高度和宽度方向分别移动
P
/
2
、
M
/
2
、
M
/
2
P/2、M/2、M/2
P
/2
、
M
/2
、
M
/2
个token的距离。
如上图(右)所示,输入大小为8×8×8,窗口大小为4×4×4。由于l层采用常规的窗口划分,l层中的窗口数为2×2×2=8。对于第l+1
层,当窗口会在三个方向上分别移动
(
P
/
2
,
M
/
2
,
M
/
2
)
=
(
2
,
2
,
2
)
(P/2,M/2,M/2) = (2,2,2)
(
P
/2
,
M
/2
,
M
/2
)
=
(
2
,
2
,
2
)
个token的距离,因此窗口数量为3×3×3=27。
采用滑动窗口划分的方法,两个连续的Video Swin Transformer块计算如下所示:

3.2.3. 3D Relative Position Bias
先前的工作已经表明,在
自注意计算中包含相对位置编码
对于performance的提升是有用的。因此作者在Video Swin Transformer也引入了3D相对位置编码,计算方式如下:
Attention
(
Q
,
K
,
V
)
=
SoftMax
(
Q
K
T
/
d
+
B
)
V
\text{Attention}(Q,K,V)=\text{SoftMax}(QK^T/\sqrt{d}+B)V
Attention
(
Q
,
K
,
V
)
=
SoftMax
(
Q
K
T
/
d
+
B
)
V
3.3 Architecture Variants
基于上面的设计,作者提出了下面四种不同参数量和计算量的网络结构:

3.4 Initialization from Pre-trained Model
由于Video Swin Transformer改编于Swin Transformer,因此Video Swin Transformer可以用在大型图像数据集上预训练的模型参数进行初始化。与Swin Transformer相比,Video Swin Transformer中只有两个模块具有不同的形状,分别为:线性embedding层和相对位置编码。
输入token在时间维度上变成了2,因此线性embedding层的形状从Swin Transformer的48×C变为96×C。在这里,作者直接复制预训练过的模型中的参数两次,然后将整个矩阵乘以0.5,以保持输出的均值和方差不变。
相对位置编码矩阵的形状为
(
2
P
−
1
,
2
M
−
1
,
2
M
−
1
)
(2P-1,2M-1,2M-1)
(
2
P
−
1
,
2
M
−
1
,
2
M
−
1
)
,而原始Swin Transformer中的形状为
(
2
M
−
1
,
2
M
−
1
)
(2M-1,2M-1)
(
2
M
−
1
,
2
M
−
1
)
。为了使相对位置编码的矩阵一样,作者将原来的
(
2
M
−
1
,
2
M
−
1
)
(2M-1,2M-1)
(
2
M
−
1
,
2
M
−
1
)
相对位置编码矩阵复制了
2
P
−
1
2P-1
2
P
−
1
次。
总结
在本文中,作者提出了一种基于时空局部感应偏置的视频识别纯Transformer的结构。该模型从用于图像识别的Swin Transformer改变而来,因此它可以利用预训练的Swin Transformer模型进行参数的初始化。该方法在三个广泛使用的视频基准数据集上(Kinetics-400, Kinetics-600, Something-Something v2)测试,并且实现了SOTA的性能,