数据集介绍
CIFAR 10 和MNIST 一样是一个很适合机器学习入门的数据集,它一共包含了50000张训练图片以及10000张测试图片。 在这些图片中,一共包含了十个类别。 在这篇文章中,我们将会建立一个很简单的卷积神经网络模型,并以此作为训练。
数据集导入以及处理
import keras as keras
import os
os.environ['KERAS_BACKEND']='tensorflow'
import numpy as np
from keras.datasets import cifar10
from keras.layers import Conv2D, MaxPooling2D, Dropout, Dense, Flatten, BatchNormalization
from keras.utils import plot_model
import matplotlib.pyplot as plt
这个数据集集成在了KERAS 里面,使用起来很方便。
(images, labels),(images_test, labels_test) = cifar10.load_data()
这样我们就导入了数据集。 这些图片全都是
32
×
32
×
3
32 \times 32 \times 3
3
2
×
3
2
×
3
的RGB图片,我们先将其做归一化处理:
images = images / 255.0
images_test = images_test / 255.0
另外,对于图片标签的部分,我们需要将其转换成one hot 编码, 方便我们训练。
labels_onehot = np.zeros([labels.shape[0], 10])
labels_test_onehot = np.zeros([labels_test.shape[0], 10])
for i, j in enumerate(labels):
labels_onehot[i][j] = 1
for i, j in enumerate(labels_test):
labels_test_onehot[i][j] = 1
CNN搭建
现在我们可以利用keras搭建一个简单的神经网络模型:
dropout_rate = 0.3
batch_size = 256
epochs = 20
model = keras.Sequential()
model.add(Conv2D(16, (3, 3), padding='same', input_shape=(32,32,3), activation = 'relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(dropout_rate))
model.add(BatchNormalization())
model.add(Conv2D(32, (3, 3), padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(dropout_rate))
model.add(BatchNormalization())
model.add(Conv2D(64, (3, 3), padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(dropout_rate))
model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3), padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(dropout_rate))
model.add(BatchNormalization())
model.add(Conv2D(256, (3, 3), padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(dropout_rate))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(dropout_rate))
model.add(Dense(10, activation = 'softmax'))
model.compile(optimizer = "adam",
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
这是一个很基础的CNN模型,我们可以通过keras将其画出来:
plot_model(model, show_shapes=True)
我们得到如下图像:
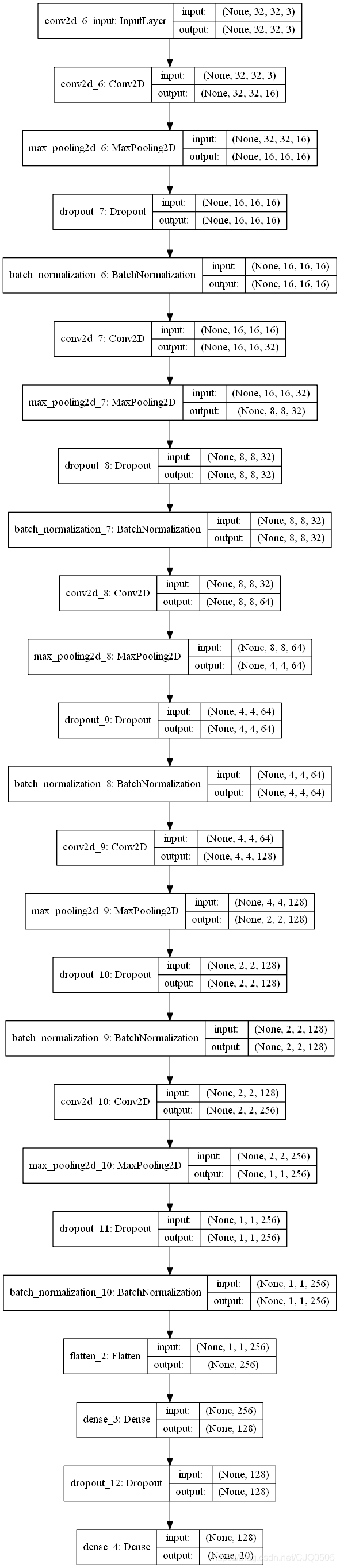
最后我们可以开始训练这个模型
history = model.fit(images, labels_onehot, batch_size = 256, epochs = 50,
validation_data = [images_test, labels_test_onehot])
plt.plot(history.epoch, history.history.get("loss"), label = 'loss')
plt.plot(history.epoch, history.history.get("acc"), label = 'accuracy')
结果如下:
Epoch 50/50
50000/50000 [==============================] - 70s 1ms/step - loss: 0.7553 - acc: 0.7339 - val_loss: 0.7950 - val_acc: 0.7266
这个简单的CNN 模型在CIFAR 10 数据集上的识别准确率在70%以上。