问题描述:
我现在有两张表,一张业务表 rk_newpeople_subsingle,一张手机号码加密记录表rk_mobiletel_encrpt数据量在9万多条。现在我要查询rk_newpeople_subsingle中的手机号原文,sql语句如下:
explain select (select rme.mobiletelval from rk_mobiletel_encrpt rme where rme.mobiletelencrpt=rns.TEL) as tel from rk_newpeople_subsingle rns where `Type` ='02' and Status ='01' and yearflag ='2023';
执行结果:
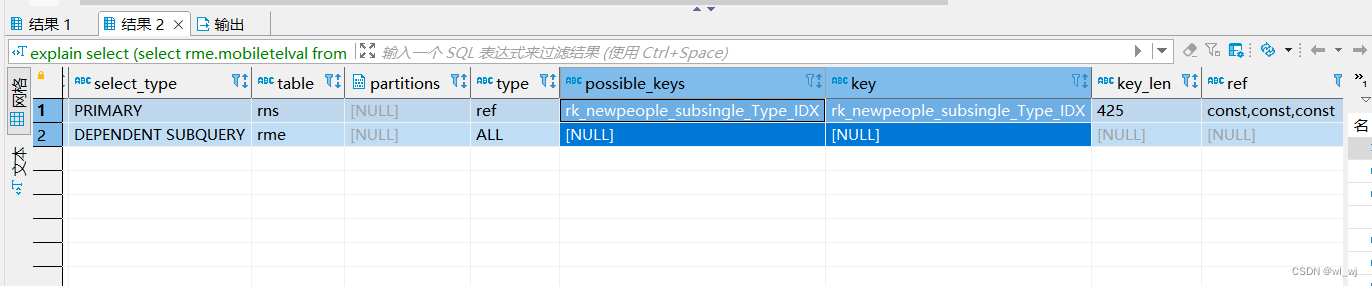
查询时长在1m30s ,尝试对mobiletelencrpt字段加索引后发现无效,用不到索引,猜测是因为用索引查询的效率还不如全表查询效率,所以没用到索引。
解决办法
想到了建立前缀索引来优化:
执行:
SELECT COUNT(DISTINCT mobiletelencrpt) / COUNT(*) FROM rk_mobiletel_encrpt;结果为1,说明字段不重复
执行:
SELECT COUNT(DISTINCT LEFT(mobiletelencrpt, 6)) / COUNT(*) FROM rk_mobiletel_encrpt;结果为1,说明mobiletelencrpt的前6位就可以区分唯一值了。
这里的6是从1开始一步步试出来的。
好了,建立前缀索引:
alter table rk_mobiletel_encrpt add index mobiletelencrpt_index(mobiletelencrpt(6));看下效果:
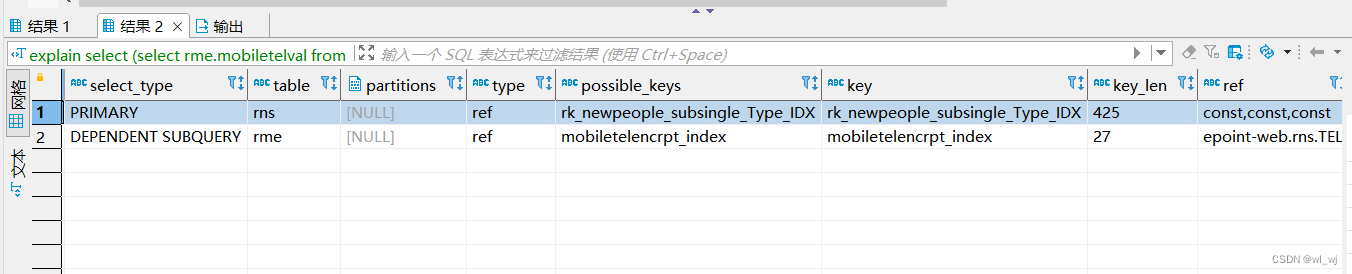
可以用到索引了,看下查询效率:
![]()
只有59ms了
版权声明:本文为wl_heike原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。