今天在测试模型时发现一个问题,
keras训练模型,训练集准确率很高,测试集准确率很低
,因此记录一下希望能帮助大家也避坑:
首先keras本身不同的版本都有些不同的或大或小的bug,包括之前也困扰过我的BN层问题(相信很多人都中过招),因此我先说下我的对应版本:
keras:2.3.1 tensorflow-gpu:1.15 CUDA:10.0 cudnn:7.6.3
在训练模型完成后在测试集测试模型准确率:
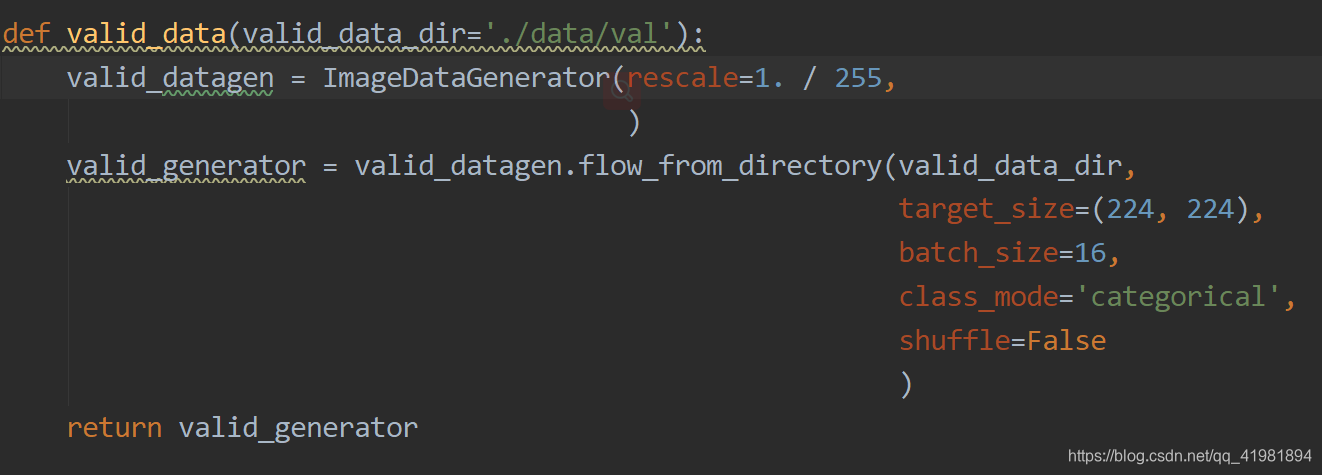
def valid_data(valid_data_dir='./data/val'):
valid_datagen = ImageDataGenerator(rescale=1. / 255)
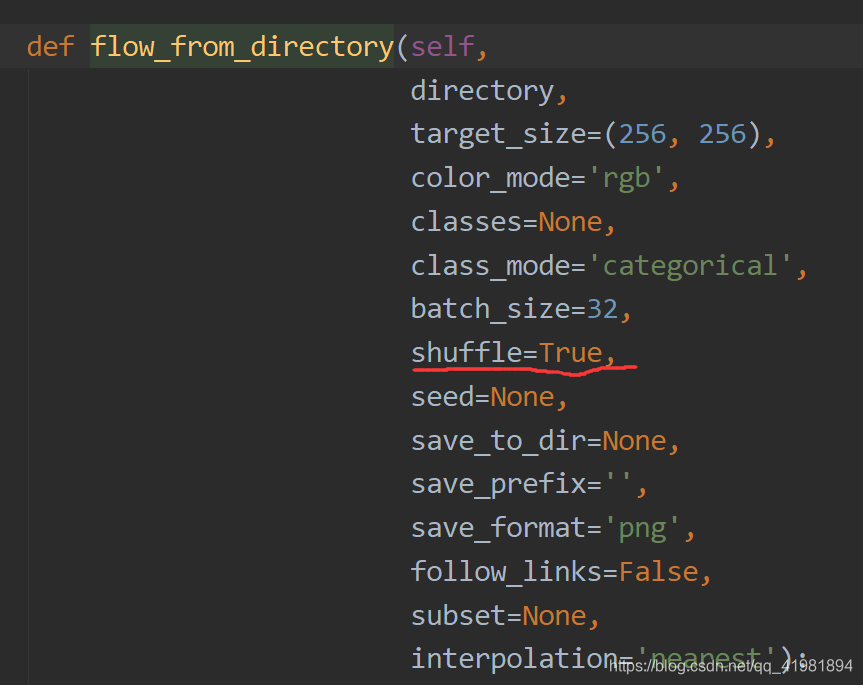
valid_generator = valid_datagen.flow_from_directory(valid_data_dir,
target_size=(224, 224),
batch_size=16,
class_mode='categorical',
)
return valid_generator
valid_generator = valid_data()
model = load_model('resnet.h5')
predictions = model.predict_generator(valid_generator,verbose=1)
predict_label = predictions.argmax(axis=-1)
true_label = valid_generator.classes
acc=accuracy_score(true_label,predict_label)
print(acc, end='\n\n')
乍一看代码其实没有太大问题,但是最后准确率很低:
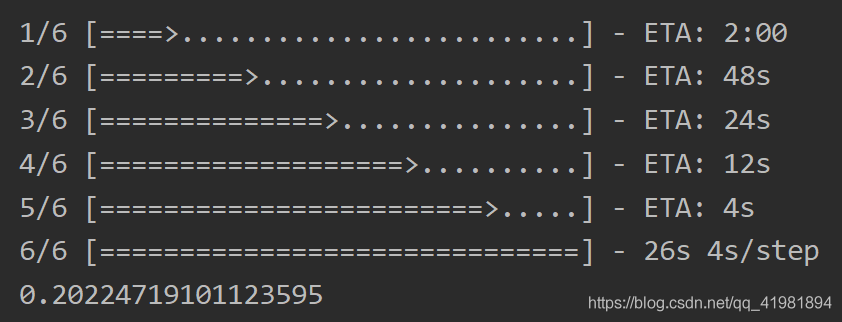
核心原因是对测试集的数据顺序做了打乱,使得预测label与真实label无法对应:
预测label是对打乱的数据预测的:

但是真实label是未打乱的:

解决的办法是对代码进行修改:
shuffle=False
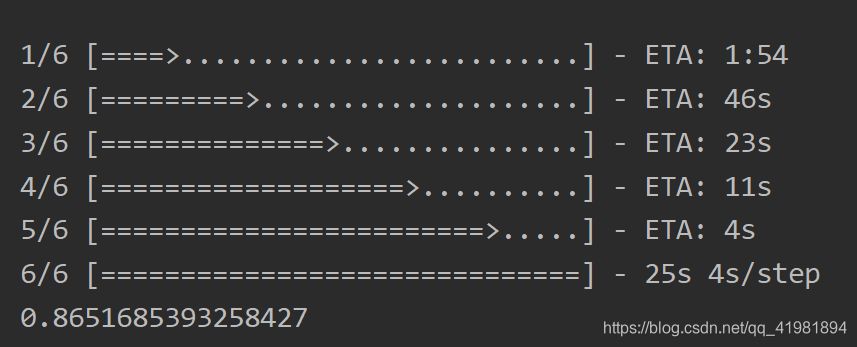
修改后的模型测试准确率就正常了:
当然,导致模型测试集准确率低的原因远不止这一种,还有很多其他的可能,所以希望大家在遇见具体问题的时候还是能够具体分析。
版权声明:本文为qq_41981894原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。