大家好,最近有不少新朋友咨询怎么学Python,从哪找学习资源等等。
由于我个人也是从网易云课程的免费资源入门的,这里就扒一扒了网易云课程的Python课程资源,做简单的处理分析,让大家对这个平台的免费好资源有个了解,然后白嫖起来就好了。
关于免费课程方面,其实有很多都讲的很详细,新人朋友选择某个完整的学习下去基本就能对基础有一定的掌握,然后再进行更深入的学习就行了。
目录:
文章目录
1. python课程数据采集
网易云课堂的课程列表数据爬取比较简单,直接关键字搜索出结果之后在开发者模式找到请求源地址即可,通过接口发现数据起始就是json格式的,处理也比较简单,附完整代码如下:
import pandas as pd
import requests
from tqdm import tqdm
# 请求头
headers = {
"Accept-Encoding": "Gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
}
# 数据接口地址
url = 'https://study.163.com/p/search/studycourse.json'
# 获取数据函数
def getData(page):
pageIndex = page
relativeOffset = (page-1)*50
Payload = {
'activityId': 0,
'keyword': "python", # python关键字,你也可以改为别的
'orderType': 5,
'pageIndex': pageIndex,
'pageSize': 50,
'priceType': -1,
'qualityType': 0,
'relativeOffset': relativeOffset,
'searchTimeType': -1,
}
r = requests.post(url, json=Payload, headers=headers)
data = r.json()
return data
# 获取总页数
data = getData(1)
pages = data['result']['query']['totlePageCount']
dataList = []
for page in tqdm(range(1, pages+1)):
data = getData(page)
dataList.extend(data['result']['list'])
# 将数据转为dataframe类型
df = pd.DataFrame(dataList)
# 只选取自己需要的字段
df = df[['courseId', 'productName', 'description', 'provider', 'score',
'learnerCount', 'lessonCount',
'originalPrice', 'discountPrice', 'discountRate','vipPrice']]
df['平台'] = '网易云课堂'
# 存储数据到本地
df.to_csv('网易云课堂python课程.csv',index=None)
数据预览:
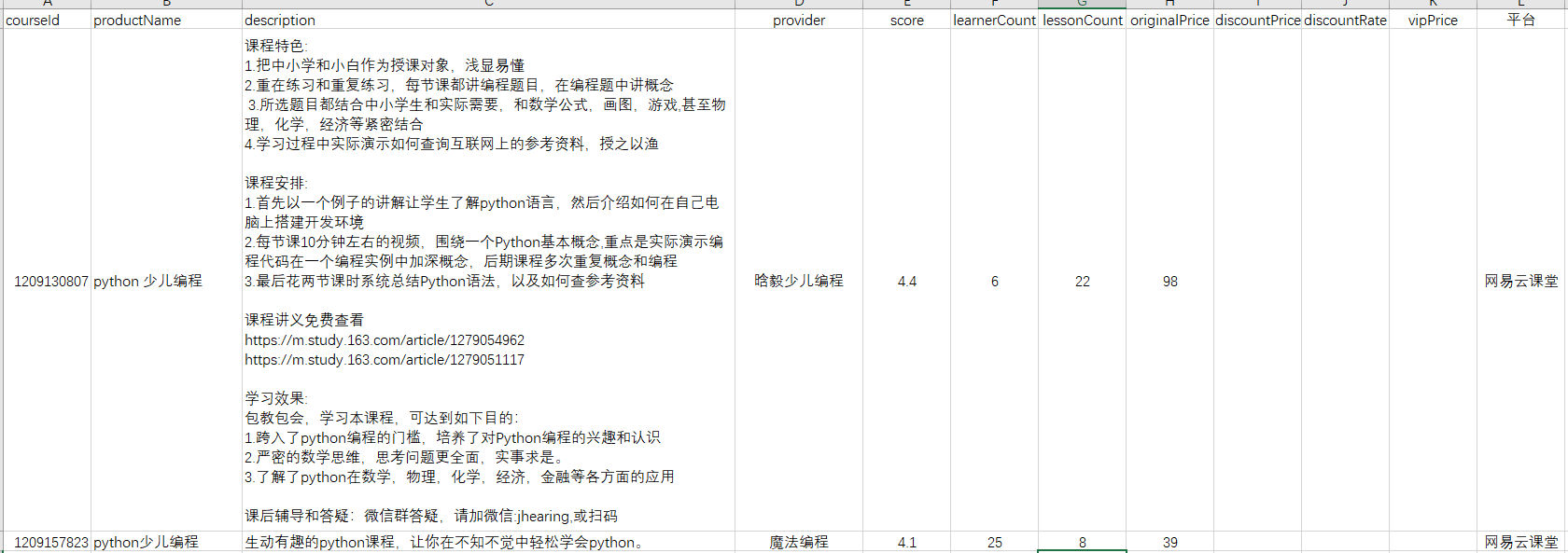
2. 简单的数据处理
由于我们在查看原始数据发现存在评分超过5,课程实际为Java或Power bi类的,这里需要进行删除:
# 删除score异常的数据及非python课程
df = df[df['score']<=5]
df = df[~df.productName.str.contains('Java')]
df = df[~df.productName.str.contains('Power')]
另外,我们在后续需要对
评分
、
价格
以及
学习人数
进行分箱操作后做数据可视化,这里也直接进行一次
分箱
操作:
# 设置评分区间
bins = [0,2,3,4,4.5,5]
df['评分区间'] = pd.cut(df.score,bins)
# 计算评分区间分布
score = df.groupby('评分区间')['courseId'].nunique().reset_index()
score.评分区间 = score.评分区间.astype('str')
# 设置原价区间
bins = [0,10,50,100,200,500,1000]
df['原价区间'] = pd.cut(df.originalPrice,bins,right=False)
# 计算原价区间分布
price = df.groupby('原价区间')['courseId'].nunique().reset_index()
price.原价区间 = price.原价区间.astype('str')
# 设置学习人次区间
bins = [0,100,200,500,1000,2000,5000,100000,1000000]
df['学习人次区间'] = pd.cut(df.learnerCount,bins,right=False)
# 计算学习人次区间分布
learner = df.groupby('学习人次区间')['courseId'].nunique().reset_index()
learner.学习人次区间 = learner.学习人次区间.astype('str')
# 计算各培训机构python课程数
provider = df.groupby('provider')['courseId'].nunique().reset_index()
3. 都有哪些不错的课程
由于评分最高的一批课程以及学习人数最多的课程都是免费的,所以这里就直接简单做排序处理就好了。
3.1. 评分最高的课程
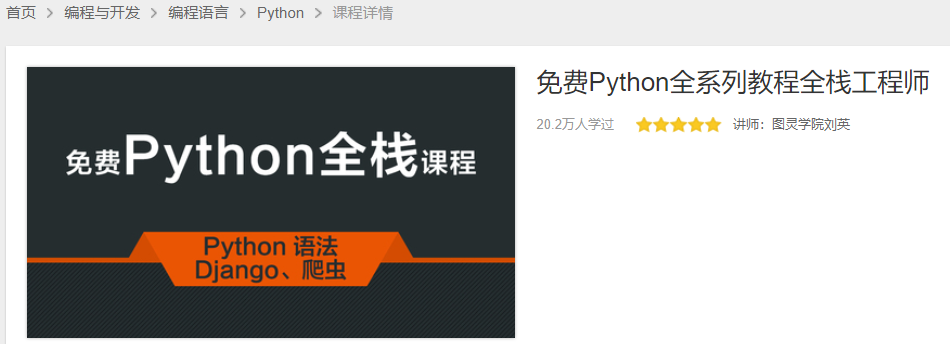
评分最高的课程都是满分5分,学习人数超过20万的免费课程《
免费Python全系列教程全栈工程师
》真的超级推荐,不仅包含了python基础,还包含了GUI库Tkinter、爬虫、Django等内容共128课时。
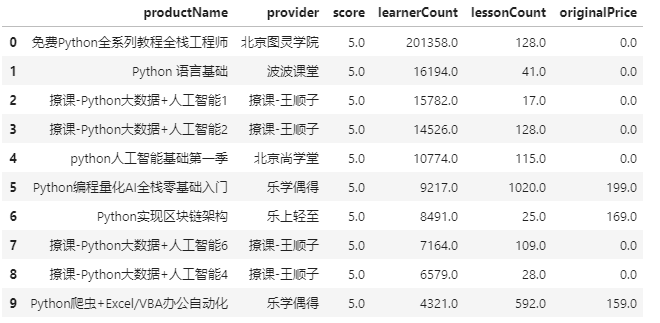
评分最高且学习人数最多的前10课程:
score10 = df.sort_values(['score','learnerCount'],ascending=False).head(10)
score10[['productName','provider','score','learnerCount','lessonCount']].reset_index(drop=True)
有兴趣的同学可以都看看,根据自己的需求,免费的好资源,白嫖起来!
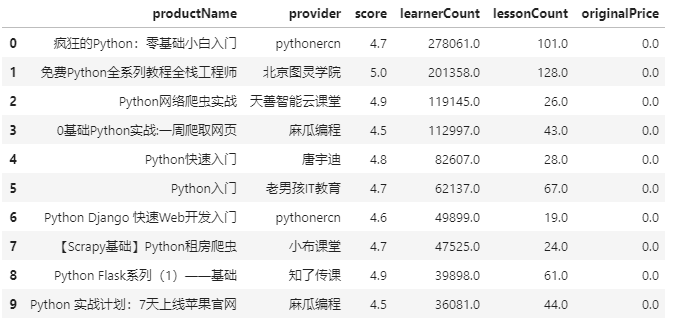
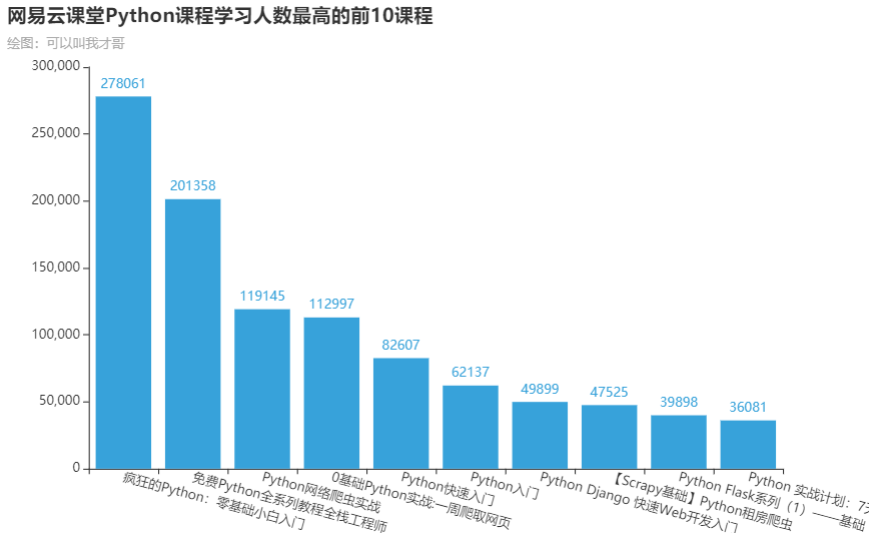
3.2. 学习人数最多的课程
在学习人数最多的课程中,
python基础
、
python爬虫
和
python-web
开发居多,大家依旧是可以根据自己的需求,有选择的进行学习。
learnerCount10 = df.sort_values(['learnerCount','score'],ascending=False).head(10)
learnerCount10[['productName','provider','score','learnerCount','lessonCount','originalPrice']].reset_index(drop=True)
绘图展示:
绘图代码:
from pyecharts import options as opts
from pyecharts.charts import Bar
x_data = learnerCount10.productName.to_list()
y_data = learnerCount10.learnerCount.to_list()
bar = (Bar(init_opts=opts.InitOpts(theme="light", width='800px',
height='490px',
))
.add_xaxis(x_data)
.add_yaxis('', y_data)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="网易云课堂Python课程学习人数最高的前10课程", subtitle="绘图:可以叫我才哥"),
)
)
bar.render_notebook()
3.3. 数据分析及可视化类的课程
我们通过关键字过滤课程,看看都有哪些关于数据分析、可视化及pandas的免费课程资源
数据分析主题课程
data = df[df['productName'].str.contains('数据分析')]
learnerCount10 = data.sort_values(['learnerCount','score'],ascending=False).head(10)
learnerCount10[['productName','provider','score','learnerCount','lessonCount','originalPrice']].reset_index(drop=True)
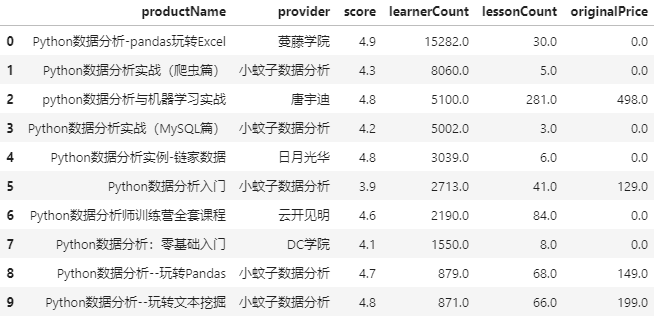
大家就找
originalPrice = 0
且
score
高的就可以看看了。
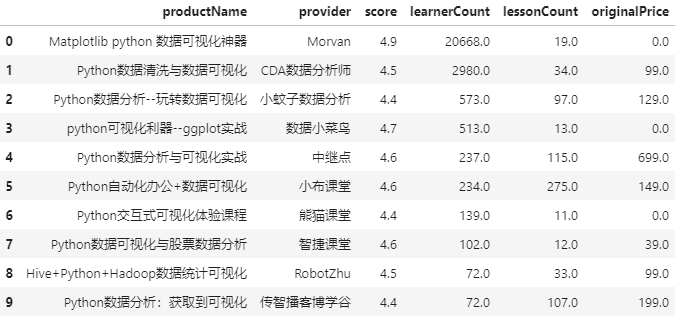
可视化主题课程
data = df[df['productName'].str.contains('可视化')]
learnerCount10 = data.sort_values(['learnerCount','score'],ascending=False).head(10)
learnerCount10[['productName','provider','score','learnerCount','lessonCount','originalPrice']].reset_index(drop=True)
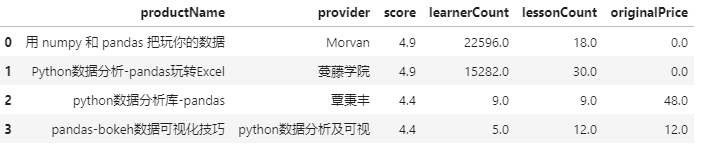
pandas主题课程
data = df[df['productName'].str.contains('pandas')]
learnerCount10 = data.sort_values(['learnerCount','score'],ascending=False).head(10)
learnerCount10[['productName','provider','score','learnerCount','lessonCount','originalPrice']].reset_index(drop=True)
4. 网易云课程Python课程数据统计
网易云课堂一共有1,544种python关键字课程,其中有400门是免费课程,占比达到25.91%超过1/4。在网易云课堂发布课程的机构有491家,其中最多的发了59门课程。
4.1. 评分区间分布
可以看到,网易云课程中,超过3/4大部分课程的评分在4-4.5分之间,超高分的4.5以上也有接近20%,整体来说还是可以的。
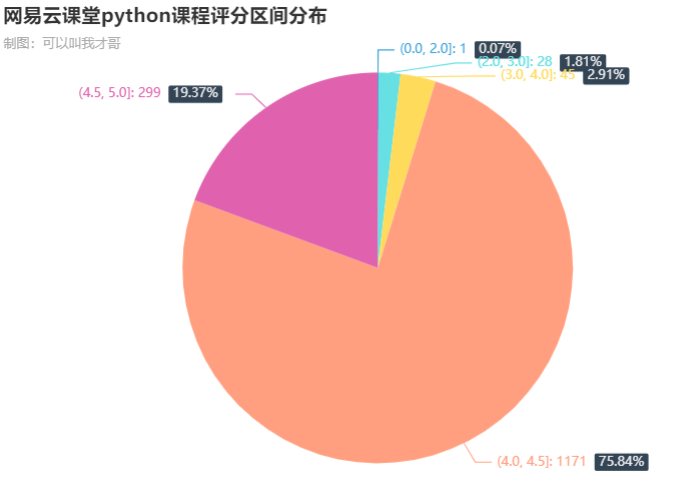
绘图代码
:
from pyecharts.charts import Pie
# 富文本
rich_text = {
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"b": {"fontSize": 12, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
}
cate = score.评分区间.to_list()
data = score.courseId.to_list()
pie = (Pie(init_opts=opts.InitOpts(theme='light', width='700px',
height='490px',
))
.add('', [list(z) for z in zip(cate, data)],
radius=180, #设置饼图半径
label_opts=opts.LabelOpts(position='outsiede',
formatter="{b|{b}: }{c} {per|{d}%} ",
rich=rich_text))
.set_global_opts(legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(title="网易云课堂python课程评分区间分布",
subtitle='制图:可以叫我才哥'),)
)
pie.render_notebook()
4.2. 课程单价区间分布(原价)
在1544门课程中,有400门免费课程,1144门付费课程。在付费课程中大部分其实在100元以内,其中10元以内 139门占比12.18%,1000元以上42门占比3.68%。
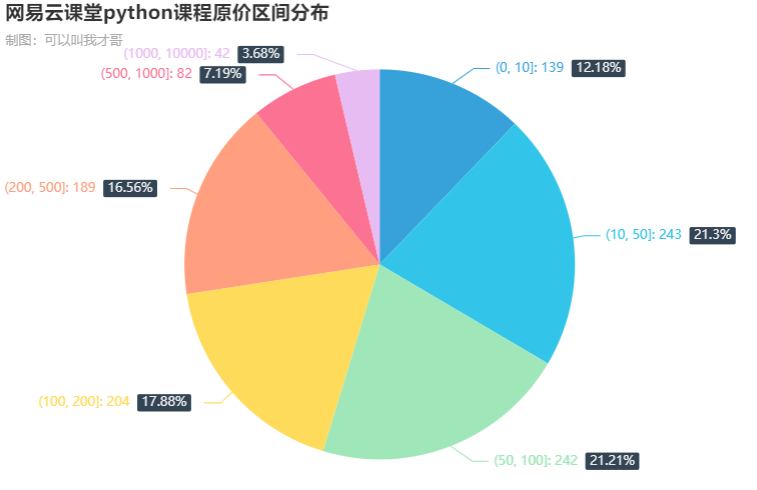
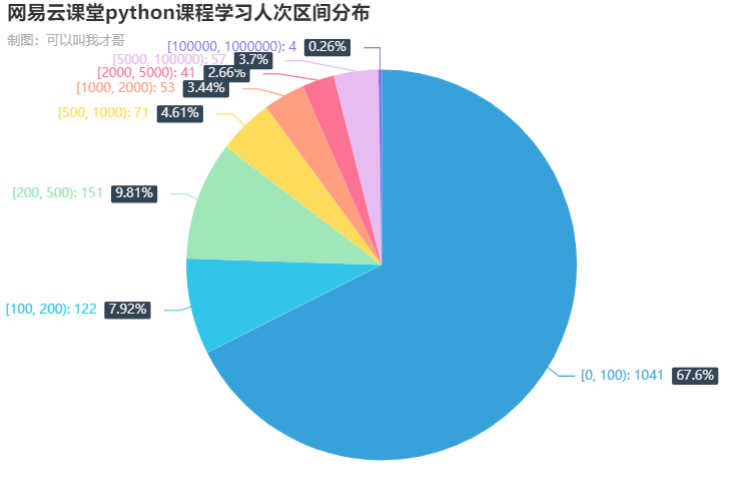
4.3. 课程学习人次区间分布
其实,有67.6%的大部分课程学习人次都较少低于100,差不多就是那些知名度低或者价格高的课程吧。另外,还有4门课的学习人次超过了10万次,这部分就是上面提到的python基础免费课程。
4.4. 课程名称常用关键词
对于python课程,大家都喜欢起什么名字呢,以python为核心关键字之外,常见的关键字还有
基础
、
入门
、
爬虫
、
开发
、
编程
、
实战
等等。
我们可以看到,爬虫 作为特殊关键词的存在,一定程度上表明了这类型可能很受python学习者的青睐!

4.4. 课程描述常用关键词
在课程描述中,依旧是以Python为核心关键字,此外
课程
、
数据
、
开发
、
学习
、
基础
、
讲解
、
介绍
、
数据分析
和
项目
等字眼也频繁被用到。

以上就是本次全部内容,关于爬虫源码、课程数据文件、数据处理及可视化过程代码大家可以回复0411领取。
现在其实各种在线教育平台提供了很多不错的免费课程资源,不需要被眼花缭乱而不知所选,其实
挑选某个比较全面的课程,然后按照课时顺序学完就够了
。