Pandas绘图
Pandas数据可视化简介
-
pandas库是Python数据分析的核心库
-
它不仅可以加载和转换数据,还可以做更多的事情:它还可以可视化
-
pandas绘图API简单易用,是pandas流行的重要原因之一
Pandas 单变量可视化
-
单变量可视化, 包括条形图、折线图、直方图、饼图等
-
数据使用葡萄酒评论数据集, 来自葡萄酒爱好者杂志(
wineEnthusiast
),包含10个字段,150929行,每一行代表一款葡萄酒字段名 字段描述 country 葡萄酒产地(国家) description 对酒的评语(气味,味道,外观,感觉等) designation 用于酿酒的葡萄产自哪个葡萄园 points WineEnthusiast(葡萄酒爱好者杂志)对葡萄酒的评分(1~100) price 价格 province 葡萄酒产地(省/州) region_1 葡萄种植区_1 region_2 葡萄种植区_2(有可能为空) variety 用于酿酒的葡萄种类 winery 酿酒厂名
-
加载数据
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#aa5500">#加载数据</span>
<span style="color:#770088">import</span> <span style="color:#000000">pandas</span> <span style="color:#770088">as</span> <span style="color:#000000">pd</span>
<span style="color:#000000">reviews</span> = <span style="color:#000000">pd</span>.<span style="color:#000000">read_csv</span>(<span style="color:#aa1111">"data/winemag-data_first150k.csv"</span>, <span style="color:#000000">index_col</span>=<span style="color:#116644">0</span>)
<span style="color:#000000">reviews</span>.<span style="color:#000000">head</span>(<span style="color:#116644">3</span>)</span></span>
显示结果:
country description designation points price province region_1 region_2 variety winery 0 US This tremendous 100% varietal wine hails from … Martha’s Vineyard 96 235.0 California Napa Valley Napa Cabernet Sauvignon Heitz 1 Spain Ripe aromas of fig, blackberry and cassis are … Carodorum Selección Especial Reserva 96 110.0 Northern Spain Toro NaN Tinta de Toro Bodega Carmen Rodríguez 2 US Mac Watson honors the memory of a wine once ma… Special Selected Late Harvest 96 90.0 California Knights Valley Sonoma Sauvignon Blanc Macauley
柱状图和分类数据
条形图(柱状图)非常灵活:
高度可以代表任何东西,只要它是数字即可
每个条形可以代表任何东西,只要它是一个类别即可。
-
条形图是最简单最常用的可视化图表。 在下面的案例中,将所有的葡萄酒品牌按照产区分类,看看哪个产区的葡萄酒品种多:
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#aa5500"># figsize 绘图区域大小, fontsize 字体大小 color 颜色</span>
<span style="color:#000000">text_kwargs</span> = <span style="color:#3300aa">dict</span>(
<span style="color:#000000">figsize</span>=(<span style="color:#116644">16</span>,<span style="color:#116644">8</span>),
<span style="color:#000000">fontsize</span>=<span style="color:#116644">20</span>,
<span style="color:#000000">color</span>=[<span style="color:#aa1111">'b'</span>,<span style="color:#aa1111">'orange'</span>,<span style="color:#aa1111">'g'</span>,<span style="color:#aa1111">'r'</span>,<span style="color:#aa1111">'purple'</span>,<span style="color:#aa1111">'brown'</span>,<span style="color:#aa1111">'pink'</span>,<span style="color:#aa1111">'gray'</span>,<span style="color:#aa1111">'cyan'</span>,<span style="color:#aa1111">'y'</span>]
)
<span style="color:#aa5500"># 计算省份出现次数,取前10,画图;**text_kwargs表示解包</span>
<span style="color:#000000">reviews</span>[<span style="color:#aa1111">'province'</span>].<span style="color:#000000">value_counts</span>().<span style="color:#000000">head</span>(<span style="color:#116644">10</span>).<span style="color:#000000">plot</span>.<span style="color:#000000">bar</span>(<span style="color:#981a1a">**</span><span style="color:#000000">text_kwargs</span>)</span></span>
显示结果:
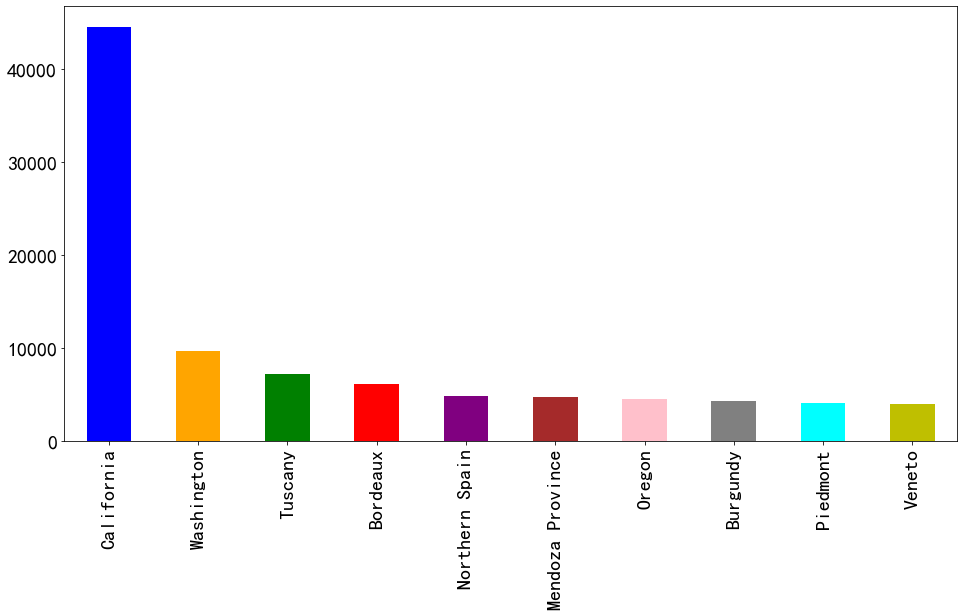
-
上面的图表说明加利福尼亚生产的葡萄酒比其他省都多, 也可以折算成比例, 计算加利福尼亚葡萄酒占总数的百分比
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#aa5500"># 计算省份出现次数,取前10,再分别除以数据的总数,就得到省份出产葡萄酒的占比</span>
(<span style="color:#000000">reviews</span>[<span style="color:#aa1111">'province'</span>].<span style="color:#000000">value_counts</span>().<span style="color:#000000">head</span>(<span style="color:#116644">10</span>) <span style="color:#981a1a">/</span> <span style="color:#3300aa">len</span>(<span style="color:#000000">reviews</span>)).<span style="color:#000000">plot</span>.<span style="color:#000000">bar</span>(<span style="color:#981a1a">**</span><span style="color:#000000">text_kwargs</span>)</span></span>
显示结果:
在《葡萄酒杂志》(Wine Magazine)评述的葡萄酒中,加利福尼亚生产了近三分之一!
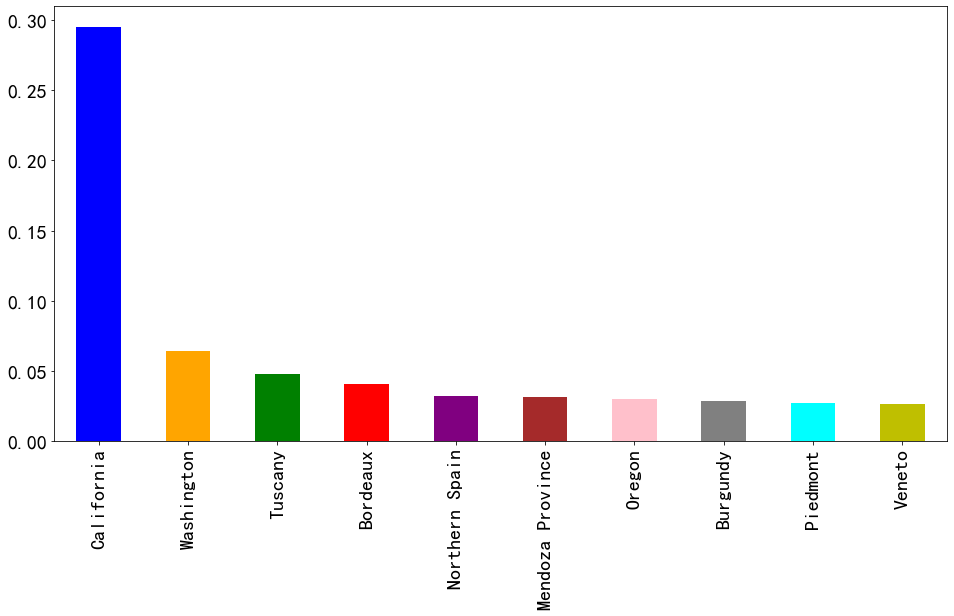
-
也可以用来展示《葡萄酒杂志》(Wine Magazine)给出的评分数量的分布情况:
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#aa5500"># 计算所有不同评分的各自数量,再根据评分进行排序,再画图</span>
<span style="color:#000000">reviews</span>[<span style="color:#aa1111">'points'</span>].<span style="color:#000000">value_counts</span>().<span style="color:#000000">sort_index</span>().<span style="color:#000000">plot</span>.<span style="color:#000000">bar</span>(<span style="color:#981a1a">**</span><span style="color:#000000">text_kwargs</span>)</span></span>
显示结果:
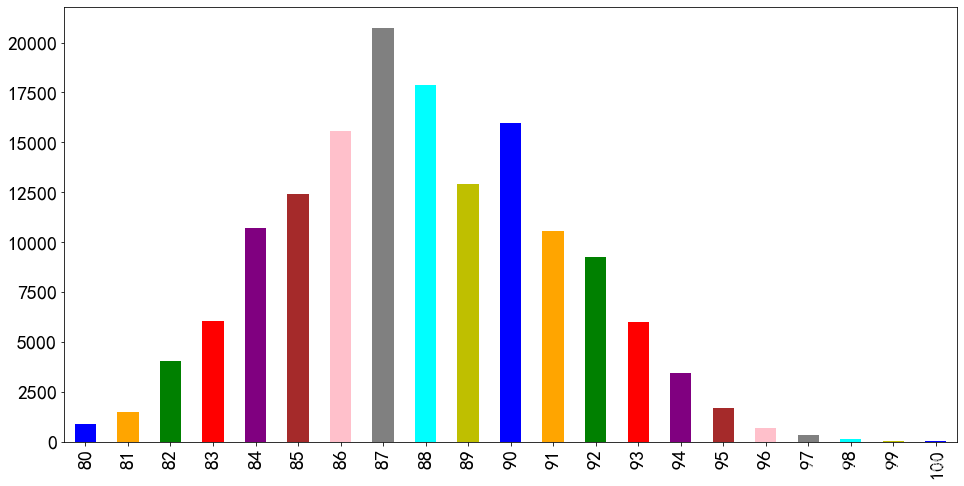
折线图
-
如果要绘制的数据不是类别值,而是连续值比较适合使用折线图
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#000000">reviews</span>[<span style="color:#aa1111">'points'</span>].<span style="color:#000000">value_counts</span>().<span style="color:#000000">sort_index</span>().<span style="color:#000000">plot</span>.<span style="color:#000000">line</span>()</span></span>
显示结果:
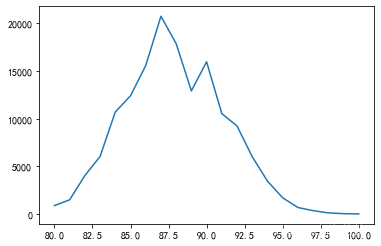
-
柱状图和折线图区别
-
柱状图:简单直观,很容易根据柱子的长短看出值的大小,易于比较各组数据之间的差别
-
折线图:
-
易于比较各组数据之间的差别
-
能比较多组数据在同一个维度上的趋势
-
每张图上不适合展示太多折线
-
-
-
小练习:柱状图或折线图
-
5种不同口味冰激凌,不同口味冰激凌的销售数量。
-
国产轿车不同品牌的月销售数量。
-
学生的考试分数,范围为0-100
-
面积图
-
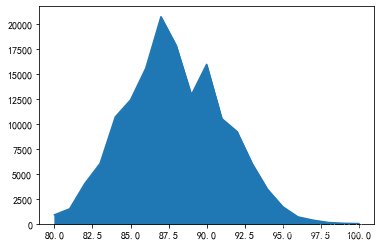
面积图就是在折线图的基础上,把折线下面的面积填充颜色;当只有一个变量需要制图时,面积图和折线图之间差异不大,在这种情况下,折线图和面积图可以互相替换
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#000000">reviews</span>[<span style="color:#aa1111">'points'</span>].<span style="color:#000000">value_counts</span>().<span style="color:#000000">sort_index</span>().<span style="color:#000000">plot</span>.<span style="color:#000000">area</span>()</span></span>
显示结果:
直方图
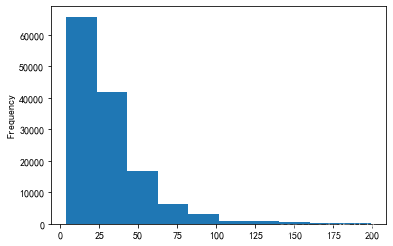
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#aa5500"># price小于200的所有数据df,取price列的值,画图</span>
<span style="color:#000000">reviews</span>[<span style="color:#000000">reviews</span>[<span style="color:#aa1111">'price'</span>] <span style="color:#981a1a"><</span> <span style="color:#116644">200</span>][<span style="color:#aa1111">'price'</span>].<span style="color:#000000">plot</span>.<span style="color:#000000">hist</span>()</span></span>
显示结果:
-
直方图看起来很像条形图。 直方图是一种特殊的条形图,它可以将数据分成均匀的间隔,并用条形图显示每个间隔中有多少行。 直方图柱子的宽度代表了分组的间距,柱状图柱子宽度没有意义。直方图缺点:将数据分成均匀的间隔区间,所以它们对歪斜的数据的处理不是很好:
<span style="background-color:#f8f8f8"><span style="color:#333333"><span style="color:#000000">reviews</span>[<span style="color:#aa1111">'price'</span>].<span style="color:#000000">plot</span>.<span style="color:#000000">hist</span>()</span></span>
显示结果:

-
在第一个直方图中,将价格>200的葡萄酒排除了
-
在第二个直方图中,没有对价格做任何处理,由于有个别品种的酒价格极高,导致直方图的价格分布发生变化
<span style="background-color:#f8f8f8"><span style="color:#333333">#查看价格较高的葡萄酒情况
reviews[reviews['price'] > 1500]
</span></span>
显示结果:
country description designation points price province region_1 region_2 variety winery 13318 US The nose on this single-vineyard wine from a s… Roger Rose Vineyard 91 2013.0 California Arroyo Seco Central Coast Chardonnay Blair 34920 France A big, powerful wine that sums up the richness… NaN 99 2300.0 Bordeaux Pauillac NaN Bordeaux-style Red Blend Château Latour 34922 France A massive wine for Margaux, packed with tannin… NaN 98 1900.0 Bordeaux Margaux NaN Bordeaux-style Red Blend Château Margaux
-
数据倾斜:
-
当数据在某个维度上分布不均匀,称为数据倾斜
-
一共15万条数据,价格高于1500的只有三条
-
价格高于500的只有73条数据,说明在价格这个维度上,数据的分布是不均匀的
-
直方图适合用来展示没有数据倾斜的数据分布情况,不适合展示数据倾斜的数据
-
<span style="background-color:#f8f8f8"><span style="color:#333333">reviews.shape
</span></span>
显示结果:
共计150930条数据<span style="background-color:#f8f8f8">(150930, 10) </span>
<span style="background-color:#f8f8f8"><span style="color:#333333">reviews[reviews['price'] >500].shape
</span></span>
显示结果:
价格大于500的数据只有73条<span style="background-color:#f8f8f8">(73, 10) </span>
-
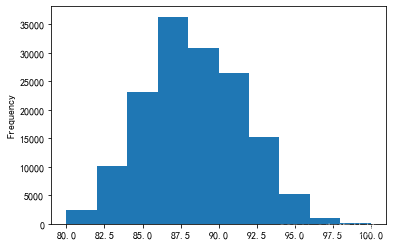
对葡萄就的评分不存在数据倾斜的情况,评分数据的分布情况比较适合用直方图展示
<span style="background-color:#f8f8f8"><span style="color:#333333">reviews['points'].plot.hist()
</span></span>
显示结果:
饼图
-
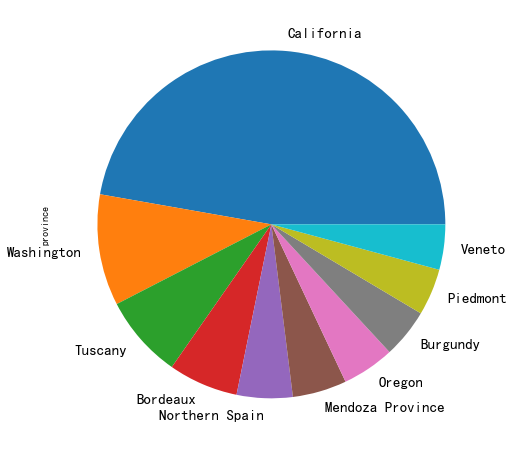
饼图也是一种常见的可视化形式
<span style="background-color:#f8f8f8"><span style="color:#333333">reviews['province'].value_counts().head(10).plot.pie()
</span></span>
显示结果:
-
饼图的缺陷:饼图只适合展示少量分类在整体的占比
-
如果分类比较多,必然每个分类的面积会比较小,这个时候很难比较两个类别
-
如果两个类别在饼图中彼此不相邻,很难进行比较
-
可以使用柱状图图来替换饼图
-
Pandas 双变量可视化
-
在上一小结中,介绍了使用Pandas绘图,理解单个变量在数据中的互相关系,本小节会考察两个变量如何进行可视化
-
数据分析时,我们需要找到变量之间的相互关系,比如一个变量的增加是否与另一个变量有关,数据可视化是找到两个变量的关系的最佳方法
散点图
-
最简单的两个变量可视化图形是散点图,散点图中的一个点,可以表示两个变量
<span style="background-color:#f8f8f8"># 价格小于100的葡萄酒,随机取样100个数据,评分分布 reviews[reviews['price'] < 100].sample(100).plot.scatter(x='price', y='points') </span>
显示结果:
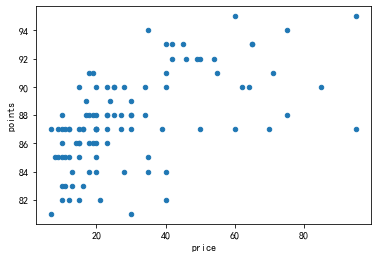
-
调整图形大小,字体大小,由于pandas的绘图功能是对Matplotlib绘图功能的封装,所以很多参数pandas 和 matplotlib都一样
<span style="background-color:#f8f8f8">reviews[reviews['price'] < 100].sample(100).plot.scatter(x='price', y='points', figsize=(14,8), fontsize = 16) </span>-
修改x轴 y轴标签字体
<span style="background-color:#f8f8f8">from matplotlib import pyplot as plt # 创建绘图区域和坐标轴 fig, axes = plt.subplots(ncols=1, figsize=(20,10)) # 使用pandas 在指定坐标轴内绘图 reviews[reviews['price'] < 100].sample(100).plot.scatter(x='price', y='points', figsize=(14,8), fontsize=16, ax=axes) # 通过坐标轴修改标签内容和字体大小 axes.set_xlabel('price', fontdict={'fontsize':16}) </span>
显示结果:
价格和评分之间有一定的相关性:也就是说,价格较高的葡萄酒通常得分更高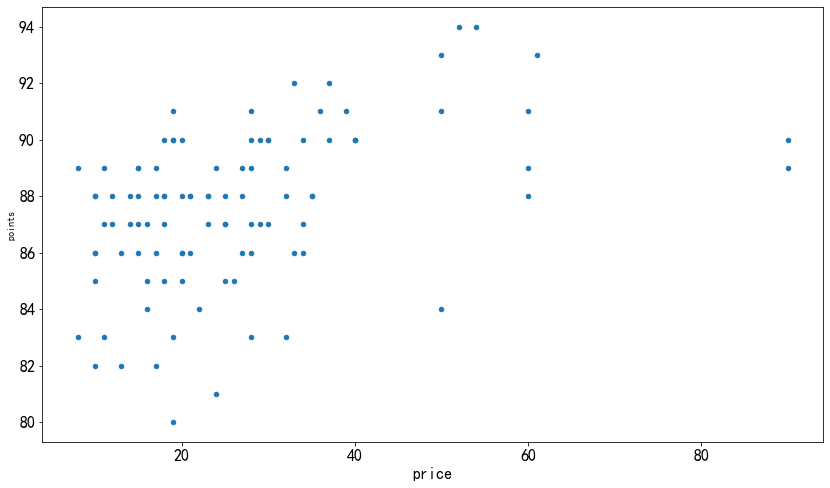
-
-
请注意,我们必须对数据进行采样,从所有数据中抽取100条数据,如果将全部数据(15万条)都绘制到散点图上,会有很多点重叠在一起,不方便观察
<span style="background-color:#f8f8f8">reviews[reviews['price'] < 100].plot.scatter(x='price', y='points',figsize=(12,8)) </span>
显示结果:
-
由于散点图的缺点,因此散点图最适合使用相对较小的数据集以及具有大量唯一值的变量。
-
有几种方法可以处理过度绘图。 一:对数据进行采样 二:hexplot(蜂巢图)
hexplot蜂巢图
-
hexplot将数据点聚合为六边形,然后根据其内的值为这些六边形上色:
<span style="background-color:#f8f8f8"><span style="color:#333333">reviews[reviews['price'] < 100].plot.hexbin(x='price', y='points', gridsize=15, figsize=(14,8))
</span></span>
显示结果:

-
上图x轴坐标缺失,属于bug,可以通过调用matplotlib的api添加x坐标
<span style="background-color:#f8f8f8"><span style="color:#333333">fig, axes = plt.subplots(ncols=1, figsize = (12,8))
reviews[reviews['price'] < 100].plot.hexbin(x='price', y='points', gridsize=15,ax = axes)
axes.set_xticks([0,20,40,60,80,100])
</span></span>
显示结果:

-
该图中的数据可以和散点图中的数据进行比较,但是hexplot能展示的信息更多
-
从hexplot中,可以看到《葡萄酒杂志》(Wine Magazine)评论的葡萄酒瓶大多数是87.5分,价格20美元
-
Hexplot和散点图可以应用于区间变量和有序分类变量的组合。
堆叠图(Stacked plots)
-
展示两个变量,除了使用散点图,也可以使用堆叠图
-
堆叠图是将一个变量绘制在另一个变量顶部的图表
-
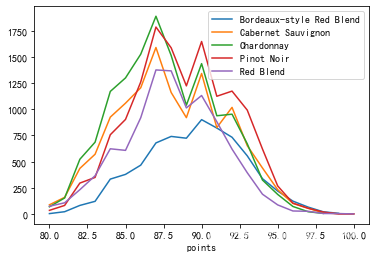
接下来通过堆叠图来展示最常见的五种葡萄酒
<span style="background-color:#f8f8f8"><span style="color:#333333"># 将葡萄酒种类分组,找到最常见的五种葡萄酒
reviews.groupby(['variety'])['country'].count().sort_values(ascending = False)
</span></span>
显示结果:
<span style="background-color:#f8f8f8">variety Chardonnay 14482 Pinot Noir 14288 Cabernet Sauvignon 12800 Red Blend 10061 Bordeaux-style Red Blend 7347 ... Chinuri 1 Petit Meslier 1 Espadeiro 1 Parraleta 1 Erbaluce 1 Name: country, Length: 632, dtype: int64 </span>
-
从结果中看出,最受欢迎的葡萄酒是,Chardonnay(霞多丽白葡萄酒),Pinot Noir(黑皮诺),Cabernet Sauvignon(赤霞珠),Red Blend(混酿红葡萄酒) ,Bordeaux-style Red Blend (波尔多风格混合红酒)
-
从数据中取出最受欢迎的五种葡萄酒
<span style="background-color:#f8f8f8"><span style="color:#333333">top_5_wine = reviews[reviews.variety.isin(['Chardonnay','Pinot Noir','Cabernet Sauvignon','Red Blend','Bordeaux-style Red Blend'])]
</span></span>-
通过透视表找到每种葡萄酒中,不同评分的数量
<span style="background-color:#f8f8f8"><span style="color:#333333"># 透视表计数
wine_counts = top_5_wine.pivot_table(index=['points'], columns ==['variety'], values='country', aggfunc='count')
# 修改列名
wine_counts.columns = ['Bordeaux-style Red Blend','Cabernet Sauvignon','Chardonnay','Pinot Noir','Red Blend']
wine_counts
</span></span>
显示结果:
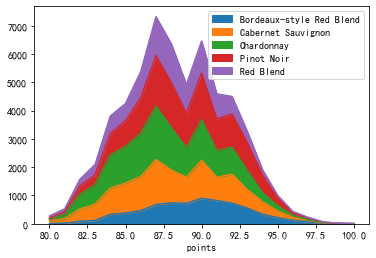
points Bordeaux-style Red Blend Cabernet Sauvignon Chardonnay Pinot Noir Red Blend 80 5.0 89.0 70.0 36.0 75.0 81 23.0 160.0 154.0 83.0 108.0 82 83.0 436.0 523.0 296.0 233.0 83 122.0 571.0 686.0 350.0 366.0 84 334.0 925.0 1170.0 757.0 623.0 85 379.0 1058.0 1299.0 903.0 608.0 86 467.0 1205.0 1525.0 1260.0 919.0 87 679.0 1589.0 1887.0 1784.0 1375.0 88 741.0 1160.0 1513.0 1586.0 1366.0 89 724.0 920.0 1039.0 1223.0 1013.0 90 901.0 1341.0 1435.0 1646.0 1131.0 91 821.0 825.0 938.0 1124.0 881.0 92 733.0 1018.0 953.0 1173.0 620.0 93 556.0 653.0 671.0 992.0 395.0 94 338.0 440.0 325.0 621.0 190.0 95 220.0 233.0 188.0 269.0 88.0 96 124.0 102.0 73.0 105.0 30.0 97 67.0 56.0 23.0 56.0 27.0 98 22.0 12.0 7.0 20.0 6.0 99 8.0 4.0 NaN 2.0 5.0 100 NaN 3.0 3.0 2.0 2.0
-
从上面的数据中看出,行列分别表示一个类别变量(评分,葡萄酒类别),行列交叉点表示计数,这类数据很适合用堆叠图展示
<span style="background-color:#f8f8f8"><span style="color:#333333">wine_counts.plot.bar(stacked=True)
</span></span>
显示结果:
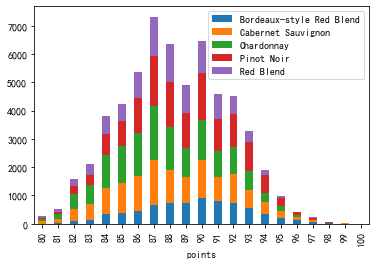
-
上图为堆积柱状图,适合展示少量类别的分类数据;也可以使用面积堆积图:
<span style="background-color:#f8f8f8"><span style="color:#333333">wine_counts.plot.area()
</span></span>
显示结果:
-
面积堆积图的使用限制:
-
① 种类较多的数据不适合用堆积图,图中显示的数据有五个种类,比较合适,一般不要超过8个种类
-
② 堆积图的可解释性(读图)较差
-
-
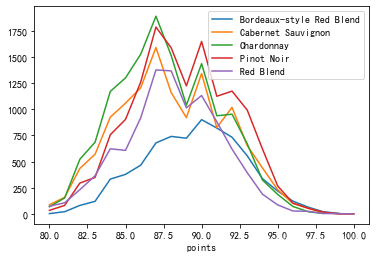
折线图
-
折线图在双变量可视化时,仍然非常有效
-
<span style="background-color:#f8f8f8"><span style="color:#333333">wine_counts.plot.line()
</span></span>
显示结果:
-
从上图看出,折线图的读图更容易,更容易对不同类别做对比
例如,在87分的酒中,哪个类别更多?从图中很容易看出,绿色的霞多丽比红色的黑比诺略多
总结
-
Pandas绘图是对Matplotlib的封装
-
Series和DataFrame 都有plot属性,根据不同的图形类型,调用对应的函数
-
可以通过Matplotlib控制图片的方法来控制Pandas绘图的效果