第一章
大数据的4V特性不包括________。(2.0分)
-
A、
数据量大 -
B、
数据类型繁多 -
C、
数据传输快 -
D、
价值密度低
正确答案: C
下列哪个不是大数据时代的新兴技术________。(2.0分)
-
A、
Hadoop -
B、
Spark -
C、
HBase -
D、
SQL Server -
正确答案: D
就数据的量级而言,1PB的数据是_______TB。(2.0分)
-
A、
1024 -
B、
1000 -
C、
1024×1024 -
D、
512
正确答案: A
大数据对思维方式的影响包括________。(2.0分)
-
A、
全样而非抽样 -
B、
效率而非精确 -
C、
片段而非全面 -
D、
相关而非因果
正确答案: ABD
云计算的典型服务模式是________。(2.0分)
-
A、
基础设施即服务 -
B、
计算即服务 -
C、
平台即服务 -
D、
软件即服务
正确答案: ACD
云计算的关键技术包括________。(2.0分)
-
A、
虚拟化 -
B、
分布式存储 -
C、
分布式计算 -
D、
多租户
正确答案: ABCD
按照服务对象划分,云计算包括________。(2.0分)
-
A、
定向云 -
B、
公有云 -
C、
私有云 -
D、
混合云
正确答案: BCD
第三次信息化浪潮的标志是物联网、____________、大数据。(2.0分)
正确答案:
第一空:
云计算;云计算技术
大数据的计算模式包括____________、流计算、图计算和查询分析计算。(2.0分)
正确答案:
第一空:
批处理;批处理计算
第二章
启动hadoop所有进程的命令是________。
-
A、
start-all.sh -
B、
start-hdfs.sh -
C、
start-hadoop.sh -
D、
start-dfs.sh
正确答案: A
以下对Hadoop的说法错误的是________。
-
A、
Hadoop MapReduce是针对谷歌MapReduce的开源实现,通常用于大规模数据集的并行计算 -
B、
Hadoop2.0增加了NameNode HA和Wire-compatibility两个重大特性 -
C、
Hadoop是基于Java语言开发的,只支持Java语言编程 -
D、
Hadoop的核心是HDFS和MapReduce
正确答案: C
以下哪个不是hadoop的特性________。
-
A、
成本高 -
B、
高可靠性 -
C、
支持多种编程语言 -
D、
高容错性
正确答案: A
以下名词解释不正确的是________。
-
A、
HDFS:分布式文件系统,是Hadoop项目的两大核心之一,是谷歌GFS的开源实现 -
B、
Hive:一个基于Hadoop的数据仓库工具,用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储 -
C、
HBase:提供高可靠性、高性能、分布式的行式数据库,是谷歌BigTable的开源实现 -
D、
Zookeeper:针对谷歌Chubby的一个开源实现,是高效可靠的协同工作系统
正确答案: C
Hadoop是________公司旗下的分布式计算平台。
-
A、
Oracle -
B、
Google -
C、
Apache -
D、
Amazon
正确答案: C
Hadoop项目结构中,________负责资源管理和调度。
-
A、
YARN -
B、
HA -
C、
Hive -
D、
Storm
正确答案: A
下列选项中哪一门技术属于大数据平台________。
-
A、
Tomcat -
B、
Hadoop -
C、
ASP.NET -
D、
Apache
正确答案: B
下列不属于Hadoop生态的技术是________。
-
A、
Hive -
B、
HDFS -
C、
HBase -
D、
SQL Server
正确答案: D
Hadoop运行在________操作系统之上。
-
A、
Windows -
B、
Linux -
C、
Unix -
D、
IOS
正确答案: B
以下哪些组件是Hadoop的生态系统的组件________。
-
A、
MapReduce -
B、
Oracle -
C、
HBase -
D、
HDFS
正确答案: ACD
Hadoop的核心组件是________和________。
-
A、
GFS -
B、
HDFS -
C、
Spark -
D、
MapReduce
正确答案: BD
Hadoop的核心组件不包括________。
-
A、
GFS -
B、
HDFS -
C、
BigTable -
D、
MapReduce
正确答案: AC
Hadoop生态系统的优势包含________。
-
A、
高扩展 -
B、
低成本 -
C、
开源工具成熟 -
D、
大型关系数据库系统
正确答案: ABC
下列________不属于Hadoop生态系统的优势。
-
A、
高扩展 -
B、
低成本 -
C、
低容错性 -
D、
大型关系数据库系统
正确答案: CD
大数据技术方案为了简化并行分布式计算,采用________软件模块进行处理。
-
A、
Java -
B、
Map -
C、
Reduce -
D、
SQL
正确答案: BC
以下________工具属于Hadoop生态系统的开源工具。
-
A、
Hive -
B、
HBase -
C、
Mysql -
D、
Zookeeper
正确答案: ABD
对Hadoop中JobTacker的工作角色,以下说法正确的是________。
-
A、
作业调度 -
B、
分配任务 -
C、
监控CPU运行效率 -
D、
监控任务执行进度
正确答案: ABD
Hadoop是IBM公司开发的一款商用大数据软件。
正确答案:
×
Hadoop是基于Java语言开发的,具有很好的跨平台特性。
正确答案:
√
Hadoop是跨平台的,安装Hadoop时没必要安装JDK。
正确答案:
×
第三章
HDFS的命名空间不包含________。
-
A、
字节 -
B、
文件 -
C、
目录 -
D、
块
正确答案: A
对HDFS通信协议的理解错误的是________。
-
A、
名称节点和数据节点之间则使用数据节点协议进行交互 -
B、
客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互 -
C、
HDFS通信协议都是构建在IoT协议基础之上的 -
D、
客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的
正确答案: C
采用多副本冗余存储的优势不包含________。
-
A、
保证数据可靠性 -
B、
节约存储空间 -
C、
加快数据传输速度 -
D、
容易检查数据错误
正确答案: B
假设已经配置好环境变量,启动HDFS和关闭HDFS的命令分别是________。
-
A、
start-hdfs.sh,stop-hdfs.sh -
B、
start-dfs.sh,stop-dfs.sh -
C、
start-dfs.sh,stop-hdfs.sh -
D、
start-hdfs.sh,stop-dfs.sh
正确答案: B
分布式文件系统HDFS采用了主从结构模型,由计算机集群中的多个节点构成的,这些节点分为两类,一类存储元数据叫________,另一类存储具体数据叫 ________。
-
A、
名称节点,数据节点 -
B、
从节点,主节点 -
C、
数据节点,名称节点 -
D、
名称节点,主节点
正确答案: A
下面关于分布式文件系统HDFS的描述正确的是________。
-
A、
分布式文件系统HDFS是Google Bigtable的一种开源实现 -
B、
分布式文件系统HDFS比较适合存储大量零碎的小文件 -
C、
分布式文件系统HDFS是一种关系型数据库 -
D、
分布式文件系统HDFS是谷歌分布式文件系统GFS(Google File System)的一种开源实现
正确答案: D
查看HDFS系统版本的Shell命令,以下正确的是________。
-
A、
hadoop -ver -
B、
hdfs version -
C、
dfsadmin version -
D、
hdfs -ver
正确答案: B
查看HDFS系统运行状态的Shell命令,以下正确的是________。
-
A、
hdfs dfsadmin -report -
B、
hadoop –report -
C、
dfsadmin -report -
D、
hdfs -report
正确答案: A
HDFS的名称节点保存两个核心的数据结构是________。
-
A、
FsImage和Edit.new。 -
B、
Map和EditLog -
C、
FsImage和EditLog。 -
D、
FsImage和HLog
正确答案: C
HDFS中使用Shell命令对Hadoop进行操作时,________实现了创建目录的功能。
-
A、
hadoop fs -mkdir /dir1 -
B、
hadoop fs -ls /usr -
C、
hadoop fs -touchz /dir -
D、
hadoop fs -cat /usr
正确答案: A
采用HDFS Java API进行程序设计时,创建FileSystem对象的语句是________。
-
A、
FileSystem fs = new FileSystem( ); -
B、
FileSystem fs = FileSystem.Create( ); -
C、
FileSystem fs = FileSystem.getInstance(); -
D、
FileSystem fs = FileSystem.get(uri, conf);
正确答案: D
以下对名称节点理解正确的是________。
-
A、
名称节点的数据保存在内存中 -
B、
名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问 -
C、
名称节点通常用来保存元数据 -
D、
名称节点用来负责具体用户数据的存储
正确答案: ABC
以下对数据节点理解正确的是________。
-
A、
数据节点的数据保存在磁盘中 -
B、
数据节点通常只有一个 -
C、
数据节点在名称节点的统一调度下进行数据块的创建、删除和复制等操作 -
D、
数据节点用来存储具体的文件内容
正确答案: ACD
HDFS只设置唯一一个名称节点带来的局限性包括________。
-
A、
隔离问题 -
B、
命名空间的限制 -
C、
集群的可用性 -
D、
性能的瓶颈
正确答案: ABCD
以下HDFS相关的shell命令不正确的是________。
-
A、
hadoop fs -ls <path>:显示<path>指定的文件的详细信息 -
B、
hadoop dfs mkdir <path>:创建<path>指定的文件夹 -
C、
hdfs dfs -rm <path>:删除路径<path>指定的文件 -
D、
hadoop fs -copyFromLocal <path1> <path2>:将路径<path2>指定的文件或文件夹复制到路径<path1>指定的文件夹中
正确答案: BD
HDFS中的NameNode节点用于存放元数据,数据内容包含________。
-
A、
文件与数据块的映射表 -
B、
每个数据块的内容 -
C、
数据块与数据节点的映射表 -
D、
客户端硬件配置数据
正确答案: AC
对HDFS内的文件进行操作,以下说法正确的是________。
-
A、
HDFS提供了Shell的操作接口 -
B、
不允许对文件进行列表查看 -
C、
文件操作命令与Linux相似 -
D、
采用Windows系统对文件进行操作
正确答案: AC
HDFS与传统数据存储对比,主要特点包含________。
-
A、
数据冗余,硬件容错 -
B、
流式的数据访问 -
C、
适合存储大量小文件 -
D、
适合存储大量大文件
正确答案: ABD
Hadoop存储系统HDFS的体系结构的设计目标包含________。
-
A、
自动检测处理硬件错误 -
B、
流式访问数据 -
C、
转移计算,不移动数据位置 -
D、
简单数据一致性模型
正确答案: ABCD
HDFS的适用性和局限性,以下说法正确的是________。
-
A、
适合数据批量读写、吞吐量高 -
B、
不适合交互式应用,低延迟很难满足 -
C、
适合一次写入多次读取、顺序读写 -
D、
不支持多用户并发写相同文件
正确答案: ABCD
HDFS中第二名称节点的作用是________。
-
A、
名称节点的热备份 -
B、
合并FsImage和EditLog文件 -
C、
作为名称节点的检查点 -
D、
提高集群的可用性
正确答案: BC
HDFS的命名空间包括目录、文件和________。
正确答案:
第一空:
块
用户可以通过”hadoop fs –put ”命令获取远端文件数据。
正确答案:
×
Hadoop存储系统HDFS的文件是分块存储,每个文件块默认大小为32MB。
正确答案:
×
HDFS系统为了容错保证数据块完整性,每一块数据都采用2份副本。
正确答案:
×
第四章
下列说法错误的是________。
-
A、
Map函数将输入的元素转换成<key,value>形式的键值对 -
B、
Hadoop框架是用Java实现的,MapReduce应用程序则一定要用Java来写 -
C、
不同的Map任务之间不能互相通信 -
D、
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave
正确答案: B
在使用MapReduce程序WordCount进行词频统计时,对于文本行“hello hadoop hello world”,经过WordCount程序的Map函数处理后直接输出的中间结果,应该是下面哪种形式________。
-
A、
<“hello”,1>、<“hello”,1>、<“hadoop”,1>和<“world”,1> -
B、
<“hello”,1,1>、<“hadoop”,1>和<“world”,1> -
C、
<“hello”,<1,1>>、<“hadoop”,1>和<“world”,1> -
D、
<“hello”,2>、<“hadoop”,1>和<“world”,1>
正确答案: A
在词频统计中,对于文本行”hello hadoop hello world”,经过WordCount的Reduce函数处理后的结果是________。
-
A、
<“hello”,<1,1>><“hadoop”,1><“world”,1> -
B、
<“hello”,2><“hadoop”,1><“world”,1> -
C、
<“hello”,1,1><“hadoop”,1><“world”,1> -
D、
<“hello”,1><“hello”,1><“hadoop”,1><“world”,1>
正确答案: B
关于Hadoop MapReduce的叙述错误的是________。
-
A、
MapReduce采用“分而治之”的思想 -
B、
MapReduce的输入和输出都是键值对的形式 -
C、
MapReduce将计算过程划分为Map任务和Reduce任务 -
D、
MapReduce的设计理念是“数据向计算靠拢”
正确答案: D
Hadoop MapReduce计算的流程是________。
-
A、
Map任务—Shuffle—Reduce任务 -
B、
Map任务—Reduce任务—Shuffle -
C、
Reduce任务—Map任务—Shuffle -
D、
Shuffle—Map任务—Reduce任务
正确答案: A
编写MapReduce程序时,下列叙述错误的是______。
-
A、
map函数所在的类必须继承Mapper类 -
B、
map函数的输出就是reduce函数的输入 -
C、
reduce函数的输出默认是有序的 -
D、
在main函数中,启动MapReduce的方法是start()。
正确答案: D
下列关于传统并行计算框架(比如MPI)和MapReduce并行计算框架比较正确的是________。
-
A、
前者相比后者学习起来更难 -
B、
前者是共享式(共享内存/共享存储),容错性差,后者是非共享式的,容错性好 -
C、
前者适用于实时、细粒度计算、计算密集型,后者适用于批处理、非实时、数据密集型 -
D、
前者所需硬件价格贵,可扩展性差,后者硬件便宜,扩展性好
正确答案: ABCD
MapReduce体系结构主要由哪几个部分组成________。
-
A、
TaskTracker -
B、
Task -
C、
JobTracker -
D、
Client
正确答案: ABCD
对MapReduce的体系结构,以下说法正确的是________。
-
A、
分布式编程架构 -
B、
以数据为中心,更看重吞吐率 -
C、
分而治之的思想 -
D、
将一个任务分解成多个子任务
正确答案: ABCD
MapReduce为了保证任务的正常执行,采用________等多种容错机制。
-
A、
重复执行 -
B、
重新开始整个任务 -
C、
推测执行 -
D、
直接丢弃执行效率低的作业
正确答案: AC
关于MapReduce的shuffle过程,叙述正确的是________。
-
A、
Shuffle分为Map任务端的Shuffle和Reduce任务段的Shuffle -
B、
Map任务的输出结果不是立即写入磁盘,而是首先写入缓存 -
C、
并非所有场合都可以使用合并操作 -
D、
每个Reduce任务真正开始之前,大部分时间都在从Map端领取所需的数据
正确答案: ABCD
MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销。
正确答案:
√
两个键值对<“a”,1>和<“a”,1>,如果对其进行归并(merge),会得到<“a”,2>,如果对其进行合并(combine),会得到<“a”,<1,1>>。
正确答案:
×
MapReduce的Shuffle操作仅在Map任务中执行。
正确答案:
×
HDFS是分布式文件系统,其命名空间包括块、目录和文件。
正确答案:
√
Map的主要工作是将多个任务的计算结果进行汇总。
正确答案:
×
在Hadoop中每个应用程序被表示成一个作业,每个作业又被分成多个任务,JobTracker的负责作业的分解、状态监控以及资源管理。
正确答案:
√
练习
查看HDFS系统版本的Shell命令,以下正确的是:
- A. hadoop -ver
- B. hdfs -ver
- C. hdfs version
- D. dfsadmin version
正确答案:
C
下列关于Map和Reduce函数的描述,哪个是错误的:
- A. Map将小数据集进一步解析成一批<key,value>对,输入Map函数中进行处理
- B. Map每一个输入的<k 1 ,v 1 >会输出一批<k 2 ,v 2 >。<k 2 ,v 2 >是计算的中间结果
- C. Reduce输入的中间结果<k 2 ,List(v 2 )>中的List(v 2 )表示是一批属于不同一个k 2 的value
- D. Reduce输入的中间结果<k 2 ,List(v 2 )>中的List(v 2 )表示是一批属于同一个k 2 的value
正确答案:
C
Hadoop中,负责资源管理和调度的是:
- A. YARN
- B. HA
- C. Hive
- D. HDFS
正确答案:
A
启动Hadoop和关闭Hadoop的命令分别是:
- A. start-hdfs.sh,stop-hdfs.sh
- B. start-dfs.sh,stop-dfs.sh
- C. start-dfs.sh,stop-hdfs.sh
- D. start-hdfs.sh,stop-dfs.sh
正确答案:
B
HDFS体系结构的设计目标包含:
- A. 自动检测处理硬件错误
- B. 流式访问数据
- C. 转移计算,不移动数据位置
- D. 简单数据一致性模型
正确答案:
ABCD
在电商网站根据用户评价信息进行判断时最主要的困难有哪些:
- A. 评论数量太多,看不过来
- B. 个人喜好不同,萝卜白菜各有所爱
- C. 恶意评论,诋毁中伤
- D. 好评如潮,混淆是非
正确答案:
CD
关于数据可视化的说法正确的是:
- A. 核心在于有效传递信息
- B. 一种浪漫的艺术表述
- C. 发挥人类视觉感知的能力
- D. 多学科交叉
正确答案:
ACD
Hadoop是一个能够对大量数据进行分布式处理的软件框架,能够处理 PB 级数据。
- A. 对
- B. 错
正确答案:
对
在Hadoop中每个应用程序被表示成一个作业,将作业的名称设置为zhangyu,用JAVA代码编写,以下正确的是:
- A. Job.SetJarName(‘zhangyu’);
- B. Job.SetMapName(‘zhangyu’);
- C. Job.SetJobName(‘zhangyu’);
- D. Job.SetInputName(‘zhangyu’);
正确答案:
C
在一个基本的Hadoop集群中,SecondaryNameNode主要负责什么?
- A. 负责协调集群中的数据存储
- B. 负责执行由JobTracker指派的任务
- C. 协调数据计算任务
- D. 帮助NameNode收集文件系统运行的状态信息
正确答案:
D
下面哪一项不属于计算机集群中的节点?
- A. 主节点(Master Node)
- B. 源节点(SourceNode)
- C. 名称结点(NameNode)
- D. 从节点(Slave Node)
正确答案:
B
下列关于MapReduce模型的描述,错误的是哪一项?
- A. MapReduce采用“分而治之”策略
- B. MapReduce设计的一个理念就是“ 计算向数据靠拢”
- C. MapReduce框架采用了Master/Slave架构
- D. 不同Map任务之间可以互相通信
正确答案:
D
HDFS的节点分为两类,存储具体数据和存储元数据的节点分别是:
- A. 名称节点,数据节点
- B. 从节点,主节点
- C. 数据节点,名称节点
- D. 名称节点,主节点
正确答案:
C
下列哪个不属于YARN体系结构中ResourceManager的功能:
- A. 处理客户端请求
- B. 监控NodeManager
- C. 资源分配与调度
- D. 处理来自ApplicationMaster的命令
正确答案:
D
云计算平台层IaaS指的是什么?
- A. 操作系统和围绕特定应用的必需的服务
- B. 将基础设施(计算资源和存储)作为服务出租
- C. 从一个集中的系统部署软件,使之在一台本地计算机上(或从云中远程地)运行的一个模型
- D. 提供硬件、软件、网络等基础设施以及提供咨询、规划和系统集成服务
正确答案:
B
下列关于MapReduce工作流程,哪个描述是正确的:
- A. 所有的数据交换都是通过MapReduce框架自身去实现的
- B. 不同的Map任务之间会进行通信
- C. 不同的Reduce任务之间可以发生信息交换
- D. 用户可以显式地从一台机器向另一台机器发送消息
我的答案:
正确答案:
A
以下关于雷达图和平行坐标说法正确的是:
- A. 平行坐标的优势在于可以展示更大的数据量
- B. 在极坐标系中,雷达图等价于平行坐标
- C. 雷达图的优势在于可以展示更高的维度
- D. 在笛卡尔坐标系中,雷达图等价于平行坐标
我的答案:
正确答案:
C
下面对FsImage的描述,哪个是错误的?
- A. FsImage文件没有记录文件包含哪些块以及每个块存储在哪个数据节点
- B. FsImage文件包含文件系统中所有目录和文件inode的序列化形式
- C. FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
- D. FsImage文件记录了所有针对文件的创建、删除、重命名等操作
我的答案:
正确答案:
D
下列哪个不属于Hadoop的特性?
- A. 成本高
- B. 高可靠性
- C. 高容错性
- D. 运行在Linux平台上
我的答案:
正确答案:
A
在一个基本的Hadoop集群中,DataNode主要负责什么?
- A. 协调数据计算任务
- B. 存储被拆分的数据块
- C. 负责协调集群中的数据存储
- D. 负责执行由JobTracker指派的任务
我的答案:
正确答案:
B
MapReduce的体系结构在,JobTracker是主要任务是什么:
- A. 负责资源监控和作业调度,监控所有TaskTracker与Job的健康状况
- B. 使用“slot”等量划分本节点上的资源量(CPU、内存等)
- C. 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给TaskTracker
- D. 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务(Task)
我的答案:
正确答案:
A
HDFS体系结构的设计目标包含:
- A. 自动检测处理硬件错误
- B. 流式访问数据
- C. 转移计算,不移动数据位置
- D. 简单数据一致性模型
我的答案:
正确答案:
ABCD
在HDFS中,名称节点(NameNode)主要保存了哪些核心的数据结构:
- A. FsImage
- B. EditLog
- C. Block
- D. DN8
我的答案:
正确答案:
AB
下列关于Map 端的Shuffle的描述,哪些是正确的:
- A. MapReduce默认1000MB缓存
- B. 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- C. 当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
- D. 每个Map任务分配多个缓存,使得任务运行更有效率
我的答案:
正确答案:
ABC
以下哪些工具属于Hadoop生态系统的开源工具:
- A. Hive
- B. HBase
- C. Mysql
- D. Zookerper
我的答案:
正确答案:
ABD
三种云计算的典型服务模式是:
- A. 网络即服务
- B. 软件即服务
- C. 平台即服务
- D. 基础设施即服务
我的答案:
正确答案:
BCD
MapReduce的作业主要包括什么:
- A. 从磁盘或从网络读取数据,即IO密集工作
- B. 计算数据,即CPU密集工作
- C. 针对不同的工作节点选择合适硬件类型
- D. 负责协调集群中的数据存储
我的答案:
正确答案:
AB
Hadoop主要提供哪些技术服务:
- A. 开发工具
- B. 开源软件
- C. 商业化工具
- D. 数据采集
我的答案:
正确答案:
ABC
在YARN体系结构中,ApplicationMaster主要功能包括哪些:
- A. 当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源
- B. 把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”
- C. 定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息
- D. 向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
我的答案:
正确答案:
ABC
HDFS只设置唯一一个名称节点带来了哪些明显的局限性:
- A. 命名空间的限制
- B. 性能的瓶颈
- C. 隔离问题
- D. 集群的可用性
我的答案:
正确答案:
ABCD
大数据对社会发展的影响有哪些:
- A. 大数据成为一种新的决策方式
- B. 大数据应用促进信息技术与各行业的深度融合
- C. 大数据开发推动新技术和新应用的不断涌现
- D. 大数据使得数据科学家成为热门职业
我的答案:
正确答案:
ABC
以下HDFS相关的shell命令不正确的是:
- A. hadoop fs -ls <path>:显示<path>指定的文件的详细信息
- B. hadoop dfs mkdir <path>:创建<path>指定的文件夹
- C. hdfs dfs -rm <path>:删除路径<path>指定的文件
- D. hadoop fs -copyFromLocal <path1> <path2>:将路径<path2>指定的文件或文件夹复制到路径<path1>指定的文件夹中
我的答案:
正确答案:
BD
MapReduce体系结构主要由以下那几部分构成:
- A. Client
- B. JobTracker
- C. TaskTracker
- D. Task
我的答案:
正确答案:
ABCD
关于数据可视化的说法正确的是:
- A. 核心在于有效传递信息
- B. 一种浪漫的艺术表述
- C. 发挥人类视觉感知的能力
- D. 多学科交叉
我的答案:
正确答案:
ACD
HDFS Federation 相对于HDFS1.0 的优势主要体现在哪里:
- A. 能够解决单点故障问题
- B. HDFS 集群扩展性
- C. 性能更高效
- D. 良好的隔离性
我的答案:
正确答案:
BCD
Hadoop集群的整体性能主要受到什么因素影响:
- A. CPU性能
- B. 内存
- C. 网络
- D. 存储容量
我的答案:
正确答案:
ABCD
在大数据时代,可视化技术可以支持实现哪些目标:
- A. 观测、跟踪数据
- B. 分析数据
- C. 辅助理解数据
- D. 增强数据吸引力
我的答案:
正确答案:
ABCD
DFS特殊的设计使得自身具有一些应用局限性,主要包括以下哪几个方面:
- A. 不适合低延迟数据访问
- B. 无法高效存储大量小文件
- C. 不支持多用户写入及任意修改文件
- D. 较差的跨平台兼容性
我的答案:
正确答案:
ABC
以下哪些属于Hadoop生态系统的开源组件:
- A. Hbase
- B. Spark
- C. GFS
- D. MapReduce
我的答案:
正确答案:
ABD
关于HDFS的适用性,以下说法正确的是:
- A. 不适合交互式应用,低延迟数据访问
- B. 无法高效存储大量小文件
- C. 不支持多用户写入及任意修改文件
- D. 适合数据批量读写、吞吐量高
我的答案:
正确答案:
ABCD
大数据对思维方式的影响主要包括全样而非抽样、效率而非精确、相关而非因果。
- A. 对
- B. 错
我的答案:
正确答案:
对
HDFS系统采用NameNode定期向DataNode发送心跳消息,用于检测系统是否正常运行。
- A. 对
- B. 错
我的答案:
正确答案:
错
Hadoop存储系统HDFS的文件是分块存储,每个文件块默认大小为32MB。
- A. 对
- B. 错
我的答案:
正确答案:
错
利用大数据分析技术可以为客户定制个性化的消费体验。
- A. 对
- B. 错
我的答案:
正确答案:
对
数据主要是其它生产活动的一种副产品,自身难以直接产生商业效益。
- A. 对
- B. 错
我的答案:
正确答案:
错
HDFS系统为了容错保证数据块完整性,每一块数据都采用两份副本。
- A. 对
- B. 错
我的答案:
正确答案:
错
下列现象不属于大数据的典型特征的是________。
- A. 数据量大
- B. 数据应用广泛
- C. 数据类型多
- D. 产生速率高
我的答案:
正确答案:
B
监控设备时刻记录着视频信息,但只有当发生盗窃事件时,才会查看其中一小段视频,这体现了大数据的________特性。
我的答案:
正确答案:
D
- A. 数据类型繁多
- B. 数据量大
- C. 处理速度快
- D. 价值密度低
-
正确答案:
D -
在下列选项中,哪种方式产生的数据量最大:
- A. 网络
- B. 机构
- C. 个人
- D. 机器
以下哪项不是大数据时代的典型特征
A. 数据的产生过程变得相对廉价
B. 存储和分析海量数据的能力
我的答案:
正确答案:
C
- C. 在宏观上对目标群体进行分析
- D. 可以深入了解每一位客户的消费习惯
-
我的答案:
正确答案:
C -
在思维方式方面,不是大数据显著影响的是________。
- A. 全样而非抽样
- B. 效率而非精确
- C. 存储而非计算
- D. 相关而非因果
需要在HDFS文件系统中创建一个文件/learn.txt,下列语句_______实现了该功能。
A. hdfs fs -touchz /learn.txt B. hadoop fs -touch /learn
我的答案:
正确答案:
D
我的答案:
正确答案:
A
-
- C. hadoop dfs -touchz /learn
- D. hdfs dfs -touchz /learn.txt
-
分布式文件系统HDFS采用了主从结构模型,由计算机集群中的多个节点构成的,这些节点分为两类,一类存储元数据叫________,另一类存储具体数据叫 ________。
- A. 名称节点,数据节点
- B. 从节点,主节点
- C. 数据节点,名称节点
- D. 名称节点,主节点
采用多副本冗余存储的优势不包含________。
A. 保证数据可靠性 B. 节约存储空间
我的答案:
正确答案:
B
我的答案:
正确答案:
A
-
- C. 加快数据传输速度
- D. 容易检查数据错误
-
以下关于平行坐标(Parallel Coordinates)说法正确的是:
- A. 可以用来展示数据在空间中的分布情况
- B. 每一个数据点由一根直线表示
- C. 每一个数据点由一根射线表示
- D. 每一维的属性值由相应线段的宽度表示
以下哪家公司在日常运作过程中会产生大量的数据?
A. 顺丰快递 B. 嘀嘀打车
我的答案:
正确答案:
D
我的答案:
正确答案:
D
-
- C. 摩拜单车
- D. 以上都是
-
下列技术中属于批处理计算模式的是________。
- A. Storm
- B. Hive
- C. Sqoop
- D. MapReduce
-
HDFS集群采用主从结构,节点主要包括________和数据节点。
- A. 从节点
- B. 文件节点
- C. 名称节点
- D. 元数据节点
-
我的答案:
正确答案:
C -
云计算平台层(PaaS)指的是什么?
- A. 操作系统和围绕特定应用的必需的服务
- B. 将基础设施(计算资源和存储)作为服务出租
-
我的答案:
正确答案:
A - C. 从一个集中的系统部署软件,使之在一台本地计算机上(或从云中远程地)运行的一个模型
- D. 提供硬件、软件、网络等基础设施以及提供咨询、规划和系统集成服务
-
以下哪个不是hadoop的特性________。
- A. 成本高
- B. 高可靠性
- C. 支持多种编程语言
- D. 高容错性
-
我的答案:
正确答案:
A -
以下名词解释不正确的是________。
- A. HDFS:分布式文件系统,是Hadoop项目的两大核心之一,是谷歌GFS的开源实现
- B. Hive:一个基于Hadoop的数据仓库工具,用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储
- C. HBase:提供高可靠性、高性能、分布式的行式数据库,是谷歌BigTable的开源实现
- D. Zookeeper:针对谷歌Chubby的一个开源实现,是高效可靠的协同工作系统
-
我的答案:正确
每种大数据产品都有特定的应用场景,以下哪个产品是用于批处理的:
- A. Dremel
- B. Storm
-
我的答案:
正确答案:
D - C. Pregel
- D. MapReduce
- A. 从模型驱动到数据驱动
- B. 通过采样的手段获取目标群体的统计特性
-
我的答案:
正确答案:
B - C. 数据就是生产资料
- D. 全样本分析
下列选项中哪一门技术属于大数据平台________。
- A. Tomcat
- B. Hadoop
- C. ASP.NET
- D. Apache
我的答案:
正确答案:
B
下列哪一项是温度传感芯片的工作原理的最准确表达:
- A. 电阻阻值随温度变化
- B. 硅器件的特征量随温度变化
- C. 电容容值随温度变化
- D. 三极管结电压随温度变化
我的答案:
正确答案:
B
下列属于结构化数据的是________。
- A. 朋友圈中的信息
- B. MySQL数据表中的数据
- C. 微博
- D. 抖音视频
我的答案:
正确答案:
B
Hadoop运行在________操作系统之上。
- A. Windows
- B. Linux
- C. Unix
- D. IOS
我的答案:
正确答案:
B
对HDFS通信协议的理解错误的是________。
- A. 名称节点和数据节点之间则使用数据节点协议进行交互
- B. 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互
- C. HDFS通信协议都是构建在IoT协议基础之上的
- D. 客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的
我的答案:
正确答案:
C
采用HDFS Java API进行程序设计时,创建FileSystem对象的语句是________。
- A. FileSystem fs = new FileSystem( );
- B. FileSystem fs = FileSystem.Create( );
- C. FileSystem fs = FileSystem.getInstance();
- D. FileSystem fs = FileSystem.get(uri, conf);
我的答案:
正确答案:
D
下列哪项说法是准确的:
- A. ASIC通过编程来实现需要的功能
- B. FPGA一旦设计好,其功能就无法修改
- C. 设计一颗ASIC芯片的费用通常很高
- D. 几千万门的FPGA单价只需要几美金
我的答案:
正确答案:
C
HDFS中使用Shell命令对Hadoop进行操作时,________实现了创建文件的功能。
- A. hdfs dfs -mkdir /file.txt
- B. hadoop fs -ls /file.txt
- C. hadoop fs -touchz /file.txt
- D. hadoop dfs -cat /file.txt
我的答案:
正确答案:
C
以下哪项不属于大数据思维的涵盖内容
- A. 从模型驱动到数据驱动
- B. 通过采样的手段获取目标群体的统计特性
- C. 数据就是生产资料
- D. 全样本分析
我的答案:
正确答案:
B
第三次信息化浪潮的标志是________。
- A. 计算机、互联网技术
- B. 数据仓库技术
- C. 物联网、云计算、大数据技术
- D. 人工智能、智能计算技术
我的答案:
正确答案:
C
以下哪个选项与分类技术相关
- A. 物以类聚,人以群分
- B. 判决平面
- C. 购物篮分析
- D. 协同过滤
我的答案:
正确答案:
B
就数据的量级而言,1PB=________ GB。
-
A.
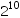
- B. 1000
- C. 1000000
-
D.
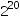
我的答案:
正确答案:
D
下列哪项说法是准确的
- A. NFC网络可包含七个活动设备
- B. LoRa采用授权频谱
- C. NB-IoT采用非授权频谱
- D. SigFox采用非授权频谱
我的答案:
正确答案:
D
关于数据和信息的描述,以下哪项是不恰当的
- A. 数据是一种对事物的描述与记录
- B. 根据类型的不同,数据可分为连续型、离散型、符号型及文本型等
- C. 相对于原始的数据,信息是一种更高层次的抽象
- D. 数据往往依托于信息,是对信息的抽象和概括
我的答案:
正确答案:
D
下列选项中,哪种温度传感器的体积最小:
- A. 热电偶
- B. 热敏电阻
- C. 温度传感芯片
我的答案:
正确答案:
C
下面关于分布式文件系统HDFS的描述正确的是________。
- A. 分布式文件系统HDFS是Google Bigtable的一种开源实现
- B. 分布式文件系统HDFS比较适合存储大量零碎的小文件
- C. 分布式文件系统HDFS是一种关系型数据库
- D. 分布式文件系统HDFS是谷歌分布式文件系统GFS(Google File System)的一种开源实现
我的答案:
正确答案:
D
以下对Hadoop的说法错误的是________。
- A. Hadoop MapReduce是针对谷歌MapReduce的开源实现,通常用于大规模数据集的并行计算
- B. Hadoop2.0增加了NameNode HA和Wire-compatibility两个重大特性
- C. Hadoop是基于Java语言开发的,只支持Java语言编程
- D. Hadoop的核心是HDFS和MapReduce
我的答案:
正确答案:
C
人类社会的数据产生方式大致经历了三个阶段,不包括________。
- A. 运营式系统阶段
- B. 用户原创内容阶段
- C. 互联网应用阶段
- D. 感知式系统阶段
我的答案:
正确答案:
C
Hadoop是________公司旗下的分布式计算平台。
- A. Oracle
- B. Google
- C. Apache
- D. Amazon
我的答案:
正确答案:
C
环境的常见类型包括:
- A. 数据云
- B. 私有云
- C. 公有云
- D. 混合云
我的答案:
正确答案:
BCD
数据科学的核心研究问题包括
- A. 聚类分析
- B. 分类算法
- C. 关联分析
- D. 推荐系统
我的答案:
正确答案:
ABCD
以下________工具属于Hadoop生态系统的开源工具。
- A. Hive
- B. HBase
- C. Mysql
- D. Zookeeper
我的答案:
正确答案:
ABD
以下对名称节点理解正确的是________。
- A. 名称节点的数据保存在内存中
- B. 名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问
- C. 名称节点通常用来保存元数据
- D. 名称节点用来负责具体用户数据的存储
我的答案:
正确答案:
ABC
下列哪些选项属于能量管理电路的功能:
- A. 为不同电路提供不同电压
- B. 扩展电池容量
- C. 进行升压转换
- D. 空闲时关闭电源
我的答案:
正确答案:
ACD
在下列选项中,哪些是设计传感器节点时需要考虑的:
- A. 硬件价格
- B. 实物大小
- C. 使用寿命
- D. 节点性能
我的答案:
正确答案:
ABCD
下列哪些选项属于蜂窝技术的特点:
- A. 需要授权
- B. 通信距离远
- C. 不需要付费
- D. 功耗较大
我的答案:
正确答案:
ABD
Hadoop的核心组件包括________。
- A. GFS
- B. HDFS
- C. Spark
- D. MapReduce
我的答案:
正确答案:
BD
以下关于眼球说法正确的有:
- A. 盲点是由于视网膜的病变所致
- B. 黄斑区是视觉最敏锐的区域
- C. 视杆细胞主要负责对颜色进行感知
- D. 瞳孔的作用类似于照相机的光圈
我的答案:
正确答案:
BD
云计算的典型服务模式包括________。
- A. 平台即服务
- B. 终端即服务
- C. 基础设施即服务
- D. 软件即服务
我的答案:
正确答案:
ACD
下列哪些说法是准确的:
- A. GPU是专门进行图形处理的微处理器
- B. TMS320是一款常用的MCU型号
- C. 通常来说,DSP的处理能力比MCU更强
- D. MCU不具备可编程扩展功能
我的答案:
正确答案:
AC
下列哪些方式可以用来实现无线充电技术:
- A. 磁场
- B. 电场
- C. 可见光
- D. 超声波
我的答案:
正确答案:
ABCD
一个典型的能量收集系统通常包含哪些单元:
- A. 效率控制电路
- B. 电压转换电路
- C. 电能存储器
- D. 能量转换器
我的答案:
正确答案:
ABCD
一个典型的用于数据采集的硬件产品通常包含哪些重要模块:
- A. 电源管理模块
- B. 传感器模块
- C. 信号处理模块
- D. 无线通信模块
我的答案:
正确答案:
ABCD
什么类型的数据必须先进行数值化才能被计算机所处理?
- A. 连续型
- B. 离散型
- C. 符号型
- D. 文本型
我的答案:
正确答案:
CD
以下哪些不属于数据类型的多样化对数据分析算法带来的新挑战
- A. 传统算法通常针对单一数据源进行分析且数据类型也极为有限
- B. 在大数据场景中,数据既包含传统意义上的结构化数据,又包含大量非结构化的数据
- C. 大多数传统机器学习算法无法直接扩展到大规模并行及分布式的系统之上
- D. 算法需要及时处理新产生的数据
我的答案:
正确答案:
CD
在进行压缩或编码等处理之前,大部分传感器的输出信号还需要进行哪些转换:
- A. 信号放大
- B. 信号滤波
- C. 模拟数字转换
- D. 接口转换
我的答案:
正确答案:
ABCD
关于数据可视化的说法正确的有:
- A. 核心在于有效传递信息
- B. 一种浪漫的艺术
- C. 发挥人类视觉感知的能力
- D. 多学科交叉
我的答案:
正确答案:
ACD
能量收集技术目前可以实现哪些能量的收集:
- A. 太阳能
- B. 风能
- C. 电磁波
- D. 热能
我的答案:
正确答案:
ABCD
关于色盲正确的说法有:
- A. 与视锥细胞有关
- B. 与视杆细胞有关
- C. 与打游戏过多有关
- D. 与遗传因素有关
我的答案:
正确答案:
AD
以下属于非结构化数据的有______。
- A. 微信朋友圈中的内容
- B. 微博
- C. 视频
- D. MySql数据库表中的数据
我的答案:
正确答案:
ABC
以下关于雷达图说法正确的是:
- A. 每一个顶点代表一个特定的属性
- B. 改变顶点的顺序不会改变两个对象所对应的面积的相对大小
- C. 顶点的顺序有严格的定义
- D. 改变顶点的顺序可能会改变一个对象所对应的面积
我的答案:
正确答案:
AD
一个惯性测量单元通常包含__________、__________和__________。
- A. 加速度计
- B. 陀螺仪
- C. 接近传感器
- D. 磁力计
我的答案:
正确答案:
ABD
图灵奖获得者、著名数据库专家Jim Gray博士认为,人类自古以来在科学研究上先后经历了四种范式,下列哪些属于 ________这四种范式。
- A. 实验科学
- B. 猜想科学
- C. 理论科学
- D. 计算科学
我的答案:
正确答案:
ACD
大数据的特征包含________。
- A. 数据量大
- B. 数据类型繁多
- C. 处理速度快
- D. 价值密度低
我的答案:
正确答案:
ABCD
通常情况下,我们希望信号放大器具备哪些特性:
- A. 低噪声
- B. 宽带宽
- C. 高增益
- D. 数字化
我的答案:
正确答案:
ABC
下列哪些选项是在选择无线通信技术时应该考虑的:
- A. 使用功耗
- B. 基础设备
- C. 传输距离
- D. 传输速率
我的答案:
正确答案:
ABCD
以下HDFS相关的shell命令不正确的是________。
- A. hadoop fs -ls <path>:显示<path>指定的文件的详细信息
- B. hadoop dfs mkdir <path>:创建<path>指定的文件夹
- C. hdfs dfs -rm <path>:删除路径<path>指定的文件
- D. hadoop fs -copyFromLocal <path1> <path2>:将路径<path2>指定的文件或文件夹复制到路径<path1>指定的文件夹中
我的答案:
正确答案:
BD
人类社会的数据产生方式大致经历了三个阶段,不包括________。
- A. 运营式系统阶段
- B. 移动互联网时代
- C. 感知式系统阶段
- D. 互联网应用阶段
我的答案:
正确答案:
BD
关于WiFi和蓝牙,下列哪些说法是准确的:
- A. 蓝牙是短程无线系统
- B. 蓝牙的理论传输范围在几米量级
- C. WiFi和蓝牙都只工作在2.4GHz
- D. WiFi的功耗比蓝牙高
我的答案:
正确答案:
AD
关于BLE和ZigBee,下列哪些说法是准确的:
- A. ZigBee基于IEEE 802.11标准规范
- B. BLE来源于蓝牙技术
- C. ZigBee的响应时间大约为几十毫秒
- D. BLE可以连接约6.5万个设备
我的答案:
正确答案:
BC
以下关于数据科学说法不正确的有哪些
- A. 编程为王
- B. 博大精深
- C. 高深莫测
- D. 扎根数据,面向行业
我的答案:
正确答案:
AC
云计算的典型服务模式包括三种:
- A. 软件即服务
- B. 网络即服务
- C. 平台即服务
- D. 基础设施即服务
我的答案:
正确答案:
ACD
实现模拟滤波器大多需要________。
- A. 电阻
- B. 运算单元
- C. 晶体管
- D. 电容
我的答案:
正确答案:
ACD
Hadoop存储系统HDFS的体系结构的设计目标包含________。
- A. 自动检测处理硬件错误
- B. 流式访问数据
- C. 转移计算,不移动数据位置
- D. 简单数据一致性模型
我的答案:
正确答案:
ABCD
大数据的计算模式包括______。
- A. 批处理计算
- B. 图计算
- C. 流计算
- D. 查询分析计算
我的答案:
正确答案:
ABCD
HDFS的命名空间包括目录、文件和________。
我的答案:
正确答案:
(1) 块
大数据分析与传统数据分析相比,主要优势在于能够从更多的维度对事物进行描述和将不同领域的数据进行关联分析。
- A. 对
- B. 错
我的答案:
正确答案:
对
两个键值对<“hello”,1>和<“hello”,1>,如果对其进行归并(merge),会得到<“hello”,<1,1>>,如果对其进行合并(combine),会得到<“hello”,2>。
- A. 对
- B. 错
我的答案:
正确答案:
对
在硅片上整合前置放大器、模拟数字转换器等相关电路,这是微机电麦克风的核心技术。
- A. 对
- B. 错
我的答案:
正确答案:
错
物联网与云计算、大数据是相辅相成的关系,物联网就是指无线传感器。
- A. 对
- B. 错
我的答案:
正确答案:
错
HBase、Flume、SQL Server和Hive技术都属于Hadoop生态。
- A. 对
- B. 错
我的答案:
正确答案:
错
HDFS集群开始启动时,其处于安全模式,可以进行读操作,不能进行写操作。
- A. 对
- B. 错
我的答案:
正确答案:
对
Map端的shuffle过程,一定会进行分区、排序和合并操作。
- A. 对
- B. 错
我的答案:
正确答案:
错
MapReduce是分布式并行计算框架,其计算模式属于流计算,实时性好。
- A. 对
- B. 错
我的答案:
正确答案:
错
大数据并非单一的数据或技术,而是数据和大数据技术的综合体。
- A. 对
- B. 错
我的答案:
正确答案:
对
对于Hadoop的伪分布和完全分布安装而言,没必要设置SSH免密码登录。
- A. 对
- B. 错
我的答案:
正确答案:
错
Hadoop是IBM公司开发的一款商用大数据软件。
- A. 对
- B. 错
我的答案:
正确答案:
错
名称节点在启动的过程中处于“安全模式”,只能对外提供读操作,无法提供写操作。
- A. 对
- B. 错
我的答案:
正确答案:
对
查找资料,给出大数据的定义。
我的答案:
正确答案:
大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。(答案不唯一)
请列举你所了解的传感器及其用途。
我的答案:
正确答案:
参考答案:
烟雾传感器:测量烟雾颗粒的浓度,CO等物质,消防烟雾报警器。
温度传感器:蔬菜大棚中实时反馈生长环境的温度。
体温枪:通过红外技术测量体温。
大数据应用的行业,以及大数据带来的影响。
我的答案:
正确答案:
答案不唯一。