深度学习自学记录(7)——yolov3的整体流程四大步详细纪录
1、整体流程
YOLO系列是很流行的目标检测模型。现在已经更新到yolov4版本,但最经典的还是yolov3版本,v4可以说是对yolov3的一些列改进手段的最优组合。
yolov3总得来讲可以分为四大模块:
(
1
)
特征提取+yolohead
:获得模型的输出y_pre;
(
2
)
y_pre的解码
:将y_pre转化为预测结果,得到真实图片上的预测框的位置(Xmin,Xmax,Ymin,Ymax)、框的得分以及目标类别;
(
3
)
真实标签的编码
:将标签文件中的真实值转化成与y_pre相同形式的tensor——y_true;
(
4
)
loss值计算
:对比y_pre,y_true计算loss值进行训练。

第一部分的过程很简单,对图片进行特征提取并输出一定shape的tensor,本篇博客主要记录一下
解码得到预测结果
,
编码过程以及loss计算
的部分。
2、解码得到预测结果
yolo输出的结果中包含三个不同尺度的特征层,我们以13×13的特征层介绍解码思路:
首先明确一点:13×13的特征图中一共有13×13个网格点,每一个网格点负责右下角方框区域的预测。
【
1
】
每一个网格点产生3中不同尺度的先验框,一共是13x13x3个先验框
。在输出的(4+1+num_class)中包含每一个每一个先验框的信息:
-
4
:先验框的调整系数,分别是
x_offest,y_offest,w,h
-
1
:先验框内包含目标的置信度,
box_confidence
-
unm_class
:每一个类别的概率,判断属于哪一类,
box_class_probs
【
2
】
我们利用4中的信息来确定预测框的位置
:
通过x_offest,y_offest对网格点进行偏移
,得到框的中心点的坐标,再经过图像尺寸(scale = input_shape/13)的缩放,就可以得到真实图片上预测框的中心点的坐标(x,y)。效果图如图所示
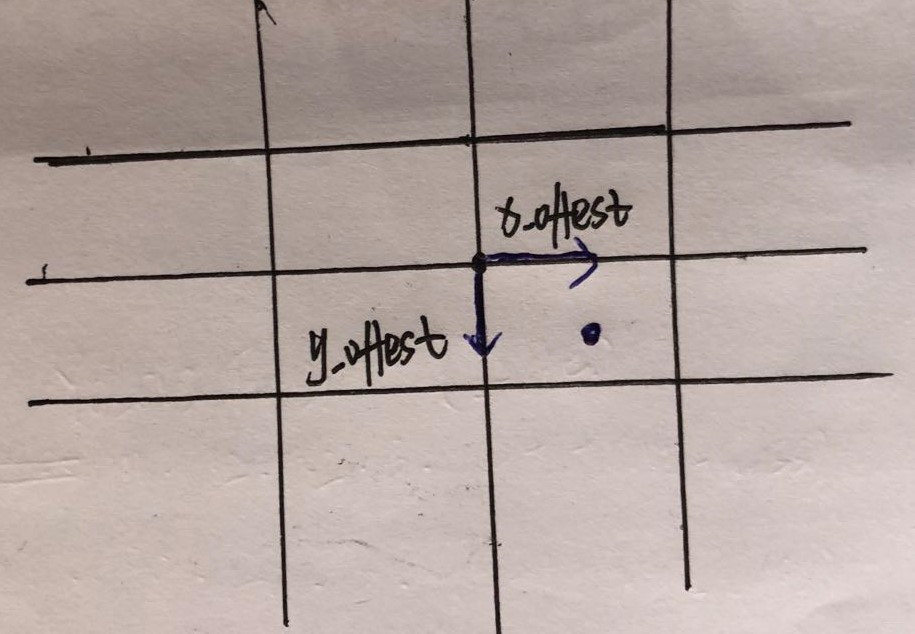
通过w和h对先验框(anchor)进行微调
,得到框的实际宽高,再根据图像尺寸(scale = input_shape/13)的缩放,就可以得到真实图片上预测框的实际宽和高(w,h)。
至此得到了实际预测框的位置信息(x,y,w,h)
。
【
3
】
我们利用1+num_class得到预测框的得分
:box_confidence是预测框含有物体的概率,box_class_probs是每一个类别的概率值,两者存在这一个正相关的关系,所以代码中 box_scores = box_confidence * box_class_probs,
框的得分=框的置信度x类别置信度
。
至此得到了实际预测框的得分box_scores
。
【
4
】
通过上面的方法,我们可以得到三个特征层上所有的预测框
,一共13x13x3+26x26x3+52x52x3个预测框。
最后,对这些框进行两个筛选,得到最终的预测输出值
。
第一次筛选
:根据box_scores 与score_threshold对比,将得分低于阈值的框删除。
第二次筛选
:根据iou_threshold利用NMS在重叠度高于阈值的框中保留得分最高的框。
最终得到最后的输出结果!!!大功告成!!
3、编码过程
所谓编码,就是将真实框转化为yolov3输出的形式(基于网格点和anchor表达真实框的位置),以便计算loss值
。说白了就是
用三个特征图上的网格点和先验框表示真实框的位置,在数据(比如m,13,13,3,4+1+num_class)中存在真实框的点和anchor的位置有值,其他位置为0
。——有些拗口,下面会解释。
编码的过程:
【
1
】从标签中获得真实框的中心以及宽和高,除去input_shape变成比例模式。
【
2
】创建包含三种特征层的
全0
列表,与yolov3的输出tensor的维度一致:(m,13,13,3,4+1+num_class)、(m,26,26,3,4+1+num_class)、(m,52,52,3,4+1+num_class),方便后面的数据写入;
【
3
】计算每一个真实框与先验框(9中不同的尺寸)的IOU,IOU最大的先验框负责那一个真实框的表达,同时根据
先验框的尺寸和真实框中心点坐标
得到
所属特征层以及特征层上网格点的位置
。
至此我们明确了所有真实框用哪一个anchor表达,确定了这个先验框的所属特征层和网格点,得到形如(m,13,13,1)的tensor
。
【
4
】明确表达真实框的先验框(先验框内有目标),下面就是
求出相应的调参系数x_offest,y_offest,w,h,用网格点和anchor表示真实框
。
负责表达真实框的先验框置信度为1(为计算loss时的正样本,先验框内有目标)
,
不负责表达真实框的位置全为0
。并将有目标的先验框内目标类别转化为num_class维度,
得到形如(m,13,13,1,4+1+num_class)的tensor——y_true
;
至此,
我们将全部的真实框转化为了不同特征图上的用先验框和网格点表达的形式。并且有目标的先验框置信度为1,是loss中的正样本,得到了最终的y_true
。
4、loss的计算
loss值得计算就是求得模型的输出y_pre与真实值y_true的差距,训练的过程就是让y_pre靠近y_true的过程。
正样本:目标,存在真实目标而先验框框
负样本:背景,不存在真实目标的先验框,即正样本之外所有的先验框。
负样本要远远多于正样本,造成正负样本不平衡的问题
下面以13×13的特征层为例,介绍loss的计算过程:
【1】首先从y_true中取出该特征层中真实存在目标的先验框(m,13,13,1)(
即负责表达真实框的先验框,正样本
)和对应目标的种类(m,13,13,num_class),这些先验框真实存在目标,其置信度为1。
【2】一共包括三个部分的loss值计算:
-
x_offest,y_offest,w,h的位置损失
:
计算的是正样本(真实存在目标的先验框)
,利用y_pre和y_true的对比结果求得。 -
class_loss分类损失
:
计算的是正样本(真实存在目标的先验框)
,利用y_pre和y_true的对比结果求得。 -
置信度损失
:
计算针对正样本(真实存在目标的先验框)和负样本(除正样本之外的所有anchor,也即是背景,不真实真实目标)
(1)——–对于正样本,y_pre的置信度与1对比求得loss;(2)——–对于负样本,首先舍弃一定数目的负样本,目的是为了正负样本的平衡(
这也是为什么focalloss对yolov3的提升不大的原因
),将IOU>0.5但不用来表达真实框的先验框舍去,不参与loss的计算;将剩下的负样本的模型输出y_pre与0对比求loss。
将三个特征层上的所有loss加在一起就得到了yolov3的loss值。至此loss计算完毕!!!需要注意的是
(1)正样本是真实存在目标的先验框,由y_true(置信度为1)决定
(2)正样本参与了所有loss值得计算
(3)部分负样本参与置信度损失的计算:为平衡正负样本,将真实框和先验框IOU<0.5的负样本保留,将y_pre与0对比计算置信度损失。
5、yolov3整体思路整理完毕
如有错误请指正