目录
1. awk命令
awk: gawk – pattern scanning and processing language
1.1 awk工作原理
与sed一样,均是一行一行的读取,处理
sed作用于一整行的处理,而awk将一行分成数个字段来处理
字段:一段字符串 –》一段很多字符组成了一个字符串

#############################################
1.2 awk语法
1.2.1 awk完整语法
awk ‘
BEGIN
{commands}
pattern
{commands}
END
{commands}’ file1
BEGIN
:处理数据前执行的命令
END
:处理数据后执行的命令
pattern
:模式,每一行都执行的命令
BEGIN和END里的命令只是执行一次
pattern里的命令会匹配每一行去处理
示例:
[root@localhost lianxi]# cat /etc/passwd|awk -F ":" 'BEGIN{print "###start###"} $3>500&&$3<2000 {print $1,$3}END{print "###end###"}'
###start###
polkitd 999
chrony 998
xiaowang 1000
chenhang 1001
zhnagjian 1002
zhangjian 1003
wangshenghu 1004
yalin 1005
nginx 997
lilanqing 1006
califeng 1007
cali123 1008
shimengmeng 1010
zhouyiwei 1011
zhaojunjie 1013
kimi 1014
kimi2 996
linhucong 1015
kimi3 1016
feng2 1018
feng3 1019
feng4 1020
feng5 1021
liudehua 1022
liming 1023
libai 1024
xiaoxiao 1025
xiyangyang 1026
meiyangyang 1027
lanyangyang 1028
zhangwuji 1029
liang 1030
###end###
awk -F “:” ‘{print $1,$2,$5}’ /etc/passwd | head -5
[root@localhost 7.4]# awk -F ":" '{print $1,$2,$5}' /etc/passwd | head -5
root x root
bin x bin
daemon x daemon
adm x adm
lp x lp
-F “:”
: awk选项,指定输入分割符为:,
‘{print}’
: 固定语法
$1,$2,$5
:输出第一个,第二个,第五个字段
,
: 是输出分隔符,如果不加默认是没有分隔符的。
[root@localhost 7.4]# awk -F ":" '{print $1$2$5}' /etc/passwd | head -5
rootxroot
binxbin
daemonxdaemon
admxadm
lpxlp
#############################################
1.2.1 awk工作流程
执行BEGIN{commands}语句块中的语句
从文件或stdin中读取第一行,看有无模式匹配,若无则执行{}中的语句
若有则检查该整行与pattern是否匹配,若匹配,则
执行
{}中的语句若不匹配则
不执行
{}中的语句,接着读取下一行重复这个过程,知道所有行被读取完毕
执行END{commands语句块中的语句}
BEGIN 和 END 部分只是执行一次
中间部分每一行都执行一次


#############################################
1.3 指定分隔符
1.3.1 -F 指定分隔符
awk默认分隔符为空白:
示例:
[root@localhost 7.1]# cat grade.txt | awk '{print $2,$3,$4}'
name chinese english
cali 80 80
tom 90 90
jarry 70 100
分隔符不是空白时候可以使用
-F选项
来指定分隔符
[root@localhost 7.1]# cat /etc/passwd | tail | awk -F ":" '{print $1,$3,$4}'
sanle 9931 9932
test 9932 9935
wang 9933 9933
zhao 9934 9934
bobo 9935 9936
hang 9936 9937
mysql 27 27
bailongma 9937 9938
baigujing 9938 9939
yutujing 9939 9940
#############################################
1.3.2 指定输出分隔符
使用OFS定义输出分隔符
OFS=”@@” 指定输出分隔符为@@
[root@localhost 7.6]# awk -F ":" 'OFS="@@"{print $1,$7}' passwd
mysql@@/sbin/nologin
bailongma@@/bin/bash
baigujing@@/bin/bash
yutujing@@/bin/bash
rrrge@@/bin/bash
#############################################
2. free命令
free查看内存使用的命令
[root@localhost 7.5]# free -m
total used free shared buff/cache available
Mem: 972 212 418 7 341 607
Swap: 2047 0 2047
#############################################
2.1 free命令各项含义
Mem
:memory 内存
total
: 是总的物理内存(内存条的大小)
used
:使用了多2.11少内存
shared
:共享内存消耗的空间 —》进程和进程之间的通信方式
buff/cache
—》buffer cache 缓存buffer :data from memory to disk
cache: data from disk to memory
available
: 可用的内存空间一个新的进程他可以使用的内存空间 = free + buff和cache里的可用空间
swap(交换分区)
:从磁盘里划分出来的一块空间,用来当做内存使用,速度比较慢将不活跃的进程临时存放到交换分区,当物理内存不足时就会采用交换分区
#############################################
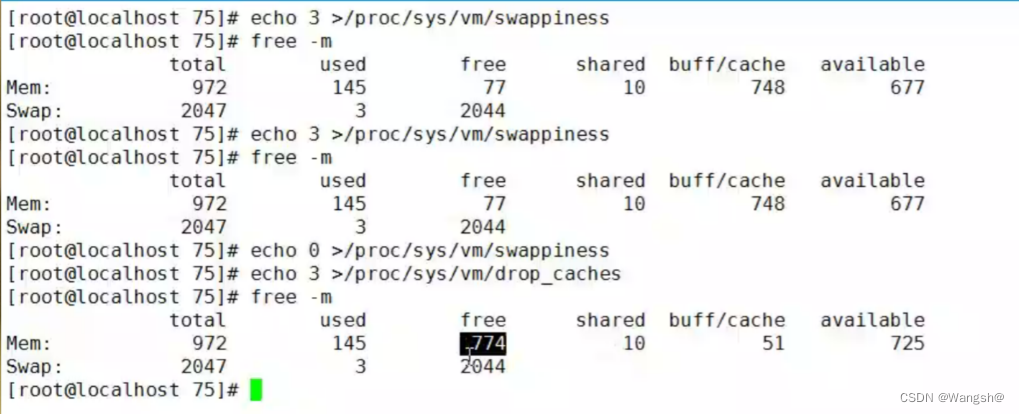
2.1.1 什么时候会使用交换分区?
内存消耗了70%时就会使用交换分区
依据:在/proc/sys/vm/swappiness 文件里面规定了这一指标
如下:意思为当物理内存还有30%时采用交换分区
[root@localhost 7.5]# cat /proc/sys/vm/swappiness
30
#############################################
2.1.2 内核参数优化
内核参数优化,提升进程使用的效率,告诉系统尽可能多使用物理内存,物理内存速度快
[root@localhost 7.5]# cat /proc/sys/vm/swappiness
30
[root@localhost 7.5]# echo 0 >/proc/sys/vm/swappiness
[root@localhost 7.5]# cat /proc/sys/vm/swappiness
0
可以看到,当我们使用交换分区以后,可用内存增加了。
2.2 常用选项
-m 以M为单位显示内存的使用情况
-h 以人类能读懂的格式显示

############################################
3.0 awk各种组合运用

#############################################
3.1 awk进行计算
例1:统计uid>1000并且使用shell是bash的用户的数量
[root@localhost 7.6]# awk -F ":" '$3>1000&&$7 ~ /bash/{print $1,$3,$7; i++}END{print "uid大于1000并且shell是bash的人数有:"i"人"}' passwd
chenhang 1001 /bin/bash
zhnagjian 1002 /bin/bash
zhangjian 1003 /bin/bash
wangshenghu 1004 /bin/bash
yalin 1005 /bin/bash
lilanqing 1006 /bin/bash
califeng 1007 /bin/bash
cali123 1008 /bin/bash
shimengmeng 1010 /bin/bash
zhouyiwei 1011 /bin/bash
zhaojunjie 1013 /bin/bash
kimi 1014 /bin/bash
linhucong 1015 /bin/bash
kimi3 1016 /bin/bash
feng2 1018 /bin/bash
feng3 1019 /bin/bash
feng4 1020 /bin/bash
feng5 1021 /bin/bash
liudehua 1022 /bin/bash
liming 1023 /bin/bash
xiaoxiao 1025 /bin/bash
xiyangyang 1026 /bin/bash
meiyangyang 1027 /bin/bash
lanyangyang 1028 /bin/bash
zhangwuji 1029 /bin/bash
liang 1030 /bin/bash
user01 9901 /bin/bash
user02 9902 /bin/bash
user03 9903 /bin/bash
user04 9904 /bin/bash
user05 9905 /bin/bash
user06 9906 /bin/bash
user07 9907 /bin/bash
user08 9908 /bin/bash
user09 9909 /bin/bash
zhangheng 9921 /bin/bash
zhaomin 9922 /bin/bash
wuji 9923 /bin/bash
liangluyao 9924 /bin/bash
pingguo 9925 /bin/bash
jingshi 9926 /bin/bash
yueyang 9927 /bin/bash
tangpj 9928 /bin/bash
tangpz1 9929 /bin/bash
sc1 9930 /bin/bash
test 9932 /bin/bash
wang 9933 /bin/bash
zhao 9934 /bin/bash
bobo 9935 /bin/bash
hang 9936 /bin/bash
bailongma 9937 /bin/bash
baigujing 9938 /bin/bash
yutujing 9939 /bin/bash
rrrge 9940 /bin/bash
uid大于1000并且shell是bash的人数有:54人
例2:显示第5行到第10行/etc/passed文件里的第3和第5字段的内容
[root@localhost 7.6]# awk -F ":" 'NR>=5 && NR<=10{print NR,$3,$5}' passwd
5 4 lp
6 5 sync
7 6 shutdown
8 7 halt
9 8 mail
10 11 operator
#############################################
3.2 awk命令的引用shell变量

在awk里面使用已经定义好的变量要用双引号括起来,并且条件匹配注意转义。

字段求和

#############################################
3.3 awk内置函数
length()函数
统计没有设置密码的用户的数量以及用户名
bobo
hang
mysql
bailongma
baigujing
yutujing
rrrge
mengmeng1
mengmeng2
mengmeng3
没有设置密码的用户有87个
substr()函数
类似于python的切片处理
例:输出使用shell是bash的用户的第7个字段的前4个字符,并输出用户名

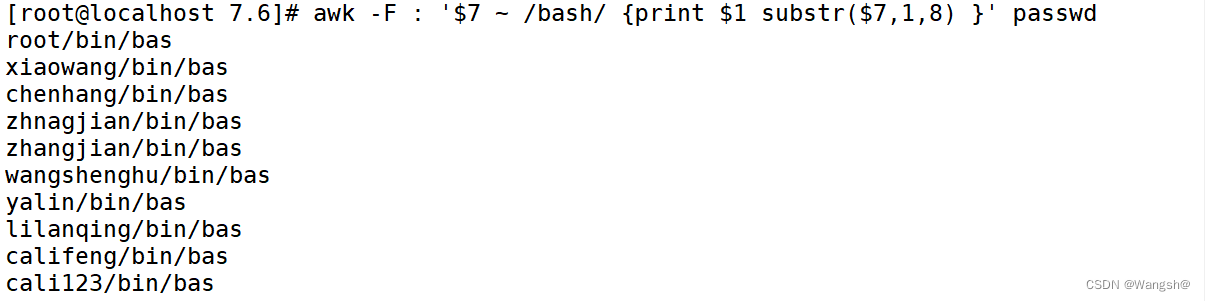
例:输出密码字段长度小于2并且输出用户名字段的前2个字符,统计个数输出出来。
[root@localhost 7.6]# awk -F : 'length($2)<=2 {print substr($1,1,2);num++}END{print num}' passwd
ro
bi
da
ad
lp
ha
my
ba
ba
yu
rr
me
me
me
87
#############################################
3.4 awk的if和for循环
if语句后面执行多个命令的时候,使用{}括起来,最后的命令接;结尾,外面的else if 和 else前面就不用再接;了

示例:使用awk命令来输出passwd文件里哪些是超级用户,系统用户,普通用户。

[root@localhost 7.5]# awk -F ":" '{if($3 ==0 ) print $1"是超级用户";else if($3>1&&$3<=999) print $1"是系统用户"; else print $1"是普通用户"}' passwd
root是超级用户
bin是普通用户
daemon是系统用户
adm是系统用户
lp是系统用户
sync是系统用户
shutdown是系统用户
halt是系统用户
mail是系统用户
operator是系统用户
games是系统用户
ftp是系统用户
nobody是系统用户
systemd-network是系统用户
dbus是系统用户
polkitd是系统用户
sshd是系统用户
postfix是系统用户
mysql是系统用户
bailongma是普通用户
baigujing是普通用户
yutujing是普通用户
例:使用awk命令来输出passwd文件里哪些是超级用户,系统用户,普通用户。并输出各用户的个数。
[root@localhost 7.6]# awk -F : '{if($3 == 0){print $1"是超级用户";num1++;}else if($3>1 && $3 <1000){print $1"是系统用户";num2++;}else{print $1 "是普通用户";num3++;}}END{print"超级用户有:"num1"系统用户有:"num2"普通用户有:"num3}' passwd
root是超级用户
bin是普通用户
daemon是系统用户
adm是系统用户
lp是系统用户
sync是系统用户
shutdown是系统用户
halt是系统用户
mail是系统用户
operator是系统用户
games是系统用户
tcpdump是系统用户
sanle是普通用户
test是普通用户
wang是普通用户
zhao是普通用户
bobo是普通用户
hang是普通用户
mysql是系统用户
bailongma是普通用户
baigujing是普通用户
yutujing是普通用户
rrrge是普通用户
mengmeng1是普通用户
mengmeng2是普通用户
mengmeng3是普通用户
超级用户有:1系统用户有:23普通用户有:63
#############################################
3.5 awk里的数组
例:统计每个省份一共得到了多少票
[root@localhost 7.6]# awk '{vote[$1]+=$3}END{for (i in vote) print i,vote[i]}' lianxi.txt | sort -n -k 2
河南 6
江西 9
山东 12
湖南 43
练习题:
对nginx的日志文件access.log进行分析,分析出单个ip地址累计下载获取的文件大小的总数(对每次访问数据的大小进行求和),显示下载总数最大的前100个ip地址和下载文件大小,按照下载文件大小的降序排列,显示格式如下:
175.8.134.239 3456
172.105.77.209 78956
…
61.147.15.67 112345678
答案示例:
[root@localhost 7.6]# awk '{access[$1]+=$10}END{for (i in access) print i,access[i]}' access.log |sort -k 2 -nr|head -100
以下是一段nginx服务的日志:
[root@localhost 7.6]# cat nginx.log
2019-04-25T09:51:58+08:00|a.google.com|47.52.197.27|GET /v2/depth?symbol=aaa HTTP/1.1|200|24|-|apple
2019-04-25T09:52:58+08:00|b.google.com|47.75.159.123|GET /v2/depth?symbol=bbb HTTP/1.1|200|407|-|python-requests/2.20.0
2019-04-25T09:53:58+08:00|c.google.com|13.125.219.4|GET /v2/ticker?timestamp=1556157118&symbol=ccc HTTP/1.1|200|162|-|chrome
2019-04-25T09:54:58+08:00|d.shuzibi.co|-||HEAD /justfor.txt HTTP/1.0|200|0|-|-
2019-04-25T09:55:58+08:00|e.google.com|13.251.98.2|GET /v2/order_detail?apiKey=ddd HTTP/1.1|200|231|-|python-requests/2.18.4
2019-04-25T09:56:58+08:00|f.google.com|210.3.168.106|GET /v2/trade_detail?apiKey=eee HTTP/1.1|200|24|-|-
2019-04-25T09:57:58+08:00|g.google.com|47.75.115.217|GET /v2/depth?symbol=fff HTTP/1.1|200|397|-|python-requests/2.18.4
2019-04-25T09:58:58+08:00|h.google.com|47.75.58.56|GET /v2/depth?symbol=ggg HTTP/1.1|200|404|-|safari
2019-04-25T09:59:58+08:00|i.google.com|188.40.137.175|GET /v2/trade_detail?symbol=hhh HTTP/1.1|200|6644|-|-
2019-04-25T10:01:58+08:00|j.google.com|2600:3c01:0:0:f03c:91ff:fe60:49b8|GET /v2/myposition?apiKey=jjj HTTP/1.1|200|110|-|scan
1.计算每分钟的带宽
方法1:
[root@localhost 7.6]# awk -F "|" '{print substr($1,1,16),$6}' nginx.log
2019-04-25T09:51 24
2019-04-25T09:52 407
2019-04-25T09:53 162
2019-04-25T09:54 200
2019-04-25T09:55 231
2019-04-25T09:56 24
2019-04-25T09:57 397
2019-04-25T09:58 404
2019-04-25T09:59 6644
2019-04-25T10:01 110
方法2:
[root@localhost 7.6]# awk -F "|" '{bandwidth[(substr($1,1,16))]+=$6}END{for (i in bandwidth) print i,bandwidth[i]}' nginx.log
2019-04-25T10:01 110
2019-04-25T09:56 24
2019-04-25T09:57 397
2019-04-25T09:58 404
2019-04-25T09:59 6644
2019-04-25T09:51 24
2019-04-25T09:52 407
2019-04-25T09:53 162
2019-04-25T09:54 200
2019-04-25T09:55 231