前言
Google搜索,早已成为我每天必用的工具,无数次惊叹它搜索结果的准确性。同时,我也在做Google的SEO,推广自己的博客。经过几个月尝试,我的博客PR到2了,外链也有几万个了。总结下来,还是感叹PageRank的神奇!
改变世界的算法,PageRank!
目录
- PageRank算法介绍
- PageRank算法原理
- PageRank算法的R语言实现
1. PageRank算法介绍
PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。它由Larry Page 和 Sergey Brin在20世纪90年代后期发明。PageRank实现了将链接价值概念作为排名因素。
PageRank让链接来”投票”
一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(“链入页面”)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
简单一句话概括:从许多优质的网页链接过来的网页,必定还是优质网页。
PageRank的计算基于以下两个基本假设:
- 数量假设:如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要
- 质量假设:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
要提高PageRank有3个要点:
- 反向链接数
- 反向链接是否来自PageRank较高的页面
- 反向链接源页面的链接数
2. PageRank算法原理
在初始阶段:网页通过链接关系构建起有向图,每个页面设置相同的PageRank值,通过若干轮的计算,会得到每个页面所获得的最终PageRank值。随着每一轮的计算进行,网页当前的PageRank值会不断得到更新。
在一轮更新页面PageRank得分的计算中,每个页面将其当前的PageRank值平均分配到本页面包含的出链上,这样每个链接即获得了相应的权值。而每个页面将所有指向本页面的入链所传入的权值求和,即可得到新的PageRank得分。当每个页面都获得了更新后的PageRank值,就完成了一轮PageRank计算。
1). 算法原理
PageRank算法建立在随机冲浪者模型上,其基本思想是:网页的重要性排序是由网页间的链接关系所决定的,算法是依靠网页间的链接结构来评价每个页面的等级和重要性,一个网页的PR值不仅考虑指向它的链接网页数,还有指向’指向它的网页的其他网页本身的重要性。
PageRank具有两大特性:
- PR值的传递性:网页A指向网页B时,A的PR值也部分传递给B
- 重要性的传递性:一个重要网页比一个不重要网页传递的权重要多
2). 计算公式:
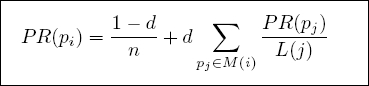
- PR(pi): pi页面的PageRank值
- n: 所有页面的数量
- pi: 不同的网页p1,p2,p3
- M(i): pi链入网页的集合
- L(j): pj链出网页的数量
-
d:阻尼系数, 任意时刻,用户到达某页面后并继续向后浏览的概率。
(1-d=0.15) :表示用户停止点击,随机跳到新URL的概率
取值范围: 0 < d ≤ 1, Google设为0.85
3). 构造实例:以4个页面的数据为例
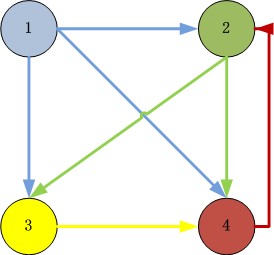
图片说明:
- ID=1的页面链向2,3,4页面,所以一个用户从ID=1的页面跳转到2,3,4的概率各为1/3
- ID=2的页面链向3,4页面,所以一个用户从ID=2的页面跳转到3,4的概率各为1/2
- ID=3的页面链向4页面,所以一个用户从ID=3的页面跳转到4的概率各为1
- ID=4的页面链向2页面,所以一个用户从ID=4的页面跳转到2的概率各为1
构造邻接表:
链接源页面 链接目标页面
1 2,3,4
2 3,4
3 4
4 2
构造邻接矩阵(方阵):
- 列:源页面
- 行:目标页面
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1 0 0 1
[3,] 1 1 0 0
[4,] 1 1 1 0
转换为概率矩阵(转移矩阵)
[,1] [,2] [,3] [,4]
[1,] 0 0 0 0
[2,] 1/3 0 0 1
[3,] 1/3 1/2 0 0
[4,] 1/3 1/2 1 0
通过链接关系,我们就构造出了“转移矩阵”。
PageRank的分步式算法原理,简单来讲,就是通过矩阵计算实现并行化。
1). 把邻接矩阵的列,按数据行存储
邻接矩阵
[,1] [,2] [,3] [,4]
[1,] 0.0375000 0.0375 0.0375 0.0375
[2,] 0.3208333 0.0375 0.0375 0.8875
[3,] 0.3208333 0.4625 0.0375 0.0375
[4,] 0.3208333 0.4625 0.8875 0.0375
按行存储HDFS
1 0.037499994,0.32083333,0.32083333,0.32083333
2 0.037499994,0.037499994,0.4625,0.4625
3 0.037499994,0.037499994,0.037499994,0.88750005
4 0.037499994,0.88750005,0.037499994,0.037499994
2). 迭代:求矩阵特征值
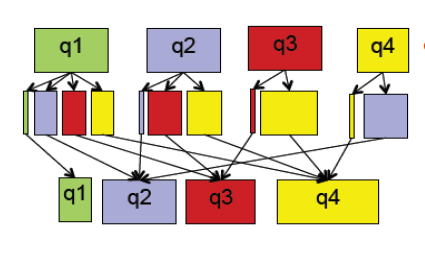
map过程:
- input: 邻接矩阵, pr值
- output: key为pr的行号,value为邻接矩阵和pr值的乘法求和公式
reduce过程:
- input: key为pr的行号,value为邻接矩阵和pr值的乘法求和公式
- output: key为pr的行号, value为计算的结果,即pr值
第1次迭代
0.0375000 0.0375 0.0375 0.0375 1 0.150000
0.3208333 0.0375 0.0375 0.8875 * 1 = 1.283333
0.3208333 0.4625 0.0375 0.0375 1 0.858333
0.3208333 0.4625 0.8875 0.0375 1 1.708333
第2次迭代
0.0375000 0.0375 0.0375 0.0375 0.150000 0.150000
0.3208333 0.0375 0.0375 0.8875 * 1.283333 = 1.6445833
0.3208333 0.4625 0.0375 0.0375 0.858333 0.7379167
0.3208333 0.4625 0.8875 0.0375 1.708333 1.4675000
… 10次迭代
特征值
0.1500000
1.4955721
0.8255034
1.5289245
3). 标准化PR值
0.150000 0.0375000
1.4955721 / (0.15+1.4955721+0.8255034+1.5289245) = 0.3738930
0.8255034 0.2063759
1.5289245 0.3822311
2. MapReduce分步式编程
MapReduce流程分解
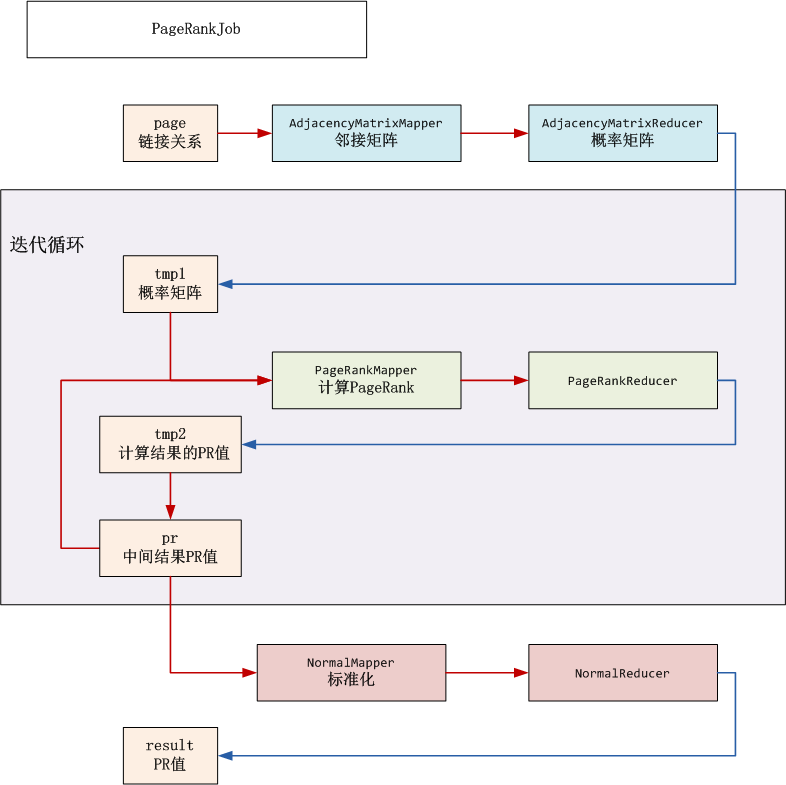
HDFS目录
- input(/user/hdfs/pagerank): HDFS的根目录
- input_pr(/user/hdfs/pagerank/pr): 临时目录,存储中间结果PR值
- tmp1(/user/hdfs/pagerank/tmp1):临时目录,存储邻接矩阵
- tmp2(/user/hdfs/pagerank/tmp2):临时目录,迭代计算PR值,然后保存到input_pr
- result(/user/hdfs/pagerank/result): PR值输出结果
开发步骤:
- 网页链接关系数据: page.csv
- 出始的PR数据:pr.csv
- 邻接矩阵: AdjacencyMatrix.java
- PageRank计算: PageRank.java
- PR标准化: Normal.java
- 启动程序: PageRankJob.java
1). 网页链接关系数据: page.csv
新建文件:page.csv
1,2
1,3
1,4
2,3
2,4
3,4
4,2
2). 出始的PR数据:pr.csv
设置网页的初始值都是1
新建文件:pr.csv
1,1
2,1
3,1
4,1
3). 邻接矩阵: AdjacencyMatrix.java

矩阵解释:
- 阻尼系数为0.85
- 页面数为4
- reduce以行输出矩阵的列,输出列主要用于分步式存储,下一步需要转成行
新建程序:AdjacencyMatrix.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.Arrays;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class AdjacencyMatrix {
private static int nums = 4;// 页面数
private static float d = 0.85f;// 阻尼系数
public static class AdjacencyMatrixMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
String[] tokens = PageRankJob.DELIMITER.split(values.toString());
Text k = new Text(tokens[0]);
Text v = new Text(tokens[1]);
context.write(k, v);
}
}
public static class AdjacencyMatrixReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
float[] G = new float[nums];// 概率矩阵列
Arrays.fill(G, (float) (1 - d) / G.length);
float[] A = new float[nums];// 近邻矩阵列
int sum = 0;// 链出数量
for (Text val : values) {
int idx = Integer.parseInt(val.toString());
A[idx - 1] = 1;
sum++;
}
if (sum == 0) {// 分母不能为0
sum = 1;
}
StringBuilder sb = new StringBuilder();
for (int i = 0; i < A.length; i++) {
sb.append("," + (float) (G[i] + d * A[i] / sum));
}
Text v = new Text(sb.toString().substring(1));
System.out.println(key + ":" + v.toString());
context.write(key, v);
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("input");
String input_pr = path.get("input_pr");
String output = path.get("tmp1");
String page = path.get("page");
String pr = path.get("pr");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(input);
hdfs.mkdirs(input);
hdfs.mkdirs(input_pr);
hdfs.copyFile(page, input);
hdfs.copyFile(pr, input_pr);
Job job = new Job(conf);
job.setJarByClass(AdjacencyMatrix.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(AdjacencyMatrixMapper.class);
job.setReducerClass(AdjacencyMatrixReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(page));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
4). PageRank计算: PageRank.java
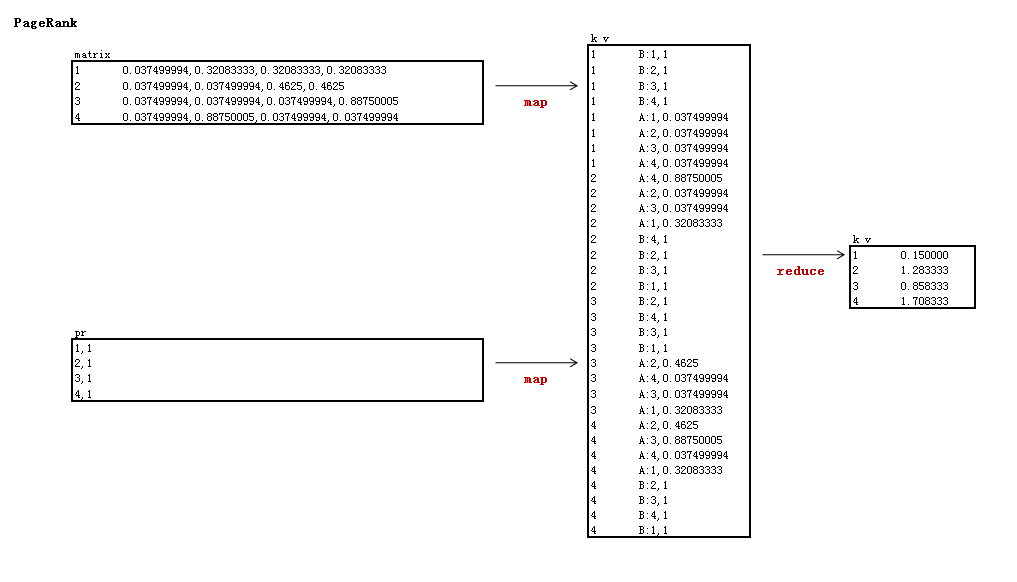
矩阵解释:
- 实现邻接与PR矩阵的乘法
- map以邻接矩阵的行号为key,由于上一步是输出的是列,所以这里需要转成行
- reduce计算得到未标准化的特征值
新建文件: PageRank.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class PageRank {
public static class PageRankMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag;// tmp1 or result
private static int nums = 4;// 页面数
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// 判断读的数据集
}
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
String[] tokens = PageRankJob.DELIMITER.split(values.toString());
if (flag.equals("tmp1")) {
String row = values.toString().substring(0,1);
String[] vals = PageRankJob.DELIMITER.split(values.toString().substring(2));// 矩阵转置
for (int i = 0; i < vals.length; i++) {
Text k = new Text(String.valueOf(i + 1));
Text v = new Text(String.valueOf("A:" + (row) + "," + vals[i]));
context.write(k, v);
}
} else if (flag.equals("pr")) {
for (int i = 1; i <= nums; i++) {
Text k = new Text(String.valueOf(i));
Text v = new Text("B:" + tokens[0] + "," + tokens[1]);
context.write(k, v);
}
}
}
}
public static class PageRankReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
Map<Integer, Float> mapA = new HashMap<Integer, Float>();
Map<Integer, Float> mapB = new HashMap<Integer, Float>();
float pr = 0f;
for (Text line : values) {
System.out.println(line);
String vals = line.toString();
if (vals.startsWith("A:")) {
String[] tokenA = PageRankJob.DELIMITER.split(vals.substring(2));
mapA.put(Integer.parseInt(tokenA[0]), Float.parseFloat(tokenA[1]));
}
if (vals.startsWith("B:")) {
String[] tokenB = PageRankJob.DELIMITER.split(vals.substring(2));
mapB.put(Integer.parseInt(tokenB[0]), Float.parseFloat(tokenB[1]));
}
}
Iterator iterA = mapA.keySet().iterator();
while(iterA.hasNext()){
int idx = iterA.next();
float A = mapA.get(idx);
float B = mapB.get(idx);
pr += A * B;
}
context.write(key, new Text(PageRankJob.scaleFloat(pr)));
// System.out.println(key + ":" + PageRankJob.scaleFloat(pr));
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("tmp1");
String output = path.get("tmp2");
String pr = path.get("input_pr");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(PageRank.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input), new Path(pr));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
hdfs.rmr(pr);
hdfs.rename(output, pr);
}
}
5). PR标准化: Normal.java

矩阵解释:
- 对PR的计算结果标准化,让所以PR值落在(0,1)区间
新建文件:Normal.java
package org.conan.myhadoop.pagerank;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Normal {
public static class NormalMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text("1");
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
System.out.println(values.toString());
context.write(k, values);
}
}
public static class NormalReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
List vList = new ArrayList();
float sum = 0f;
for (Text line : values) {
vList.add(line.toString());
String[] vals = PageRankJob.DELIMITER.split(line.toString());
float f = Float.parseFloat(vals[1]);
sum += f;
}
for (String line : vList) {
String[] vals = PageRankJob.DELIMITER.split(line.toString());
Text k = new Text(vals[0]);
float f = Float.parseFloat(vals[1]);
Text v = new Text(PageRankJob.scaleFloat((float) (f / sum)));
context.write(k, v);
System.out.println(k + ":" + v);
}
}
}
public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = PageRankJob.config();
String input = path.get("input_pr");
String output = path.get("result");
HdfsDAO hdfs = new HdfsDAO(PageRankJob.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(Normal.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(NormalMapper.class);
job.setReducerClass(NormalReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
6). 启动程序: PageRankJob.java
新建文件:PageRankJob.java
package org.conan.myhadoop.pagerank;
import java.text.DecimalFormat;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class PageRankJob {
public static final String HDFS = "hdfs://192.168.1.210:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
Map<String, String> path = new HashMap<String, String>();
path.put("page", "logfile/pagerank/page.csv");// 本地的数据文件
path.put("pr", "logfile/pagerank/pr.csv");// 本地的数据文件
path.put("input", HDFS + "/user/hdfs/pagerank");// HDFS的目录
path.put("input_pr", HDFS + "/user/hdfs/pagerank/pr");// pr存储目
path.put("tmp1", HDFS + "/user/hdfs/pagerank/tmp1");// 临时目录,存放邻接矩阵
path.put("tmp2", HDFS + "/user/hdfs/pagerank/tmp2");// 临时目录,计算到得PR,覆盖input_pr
path.put("result", HDFS + "/user/hdfs/pagerank/result");// 计算结果的PR
try {
AdjacencyMatrix.run(path);
int iter = 3;
for (int i = 0; i < iter; i++) {// 迭代执行
PageRank.run(path);
}
Normal.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
public static JobConf config() {// Hadoop集群的远程配置信息
JobConf conf = new JobConf(PageRankJob.class);
conf.setJobName("PageRank");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
public static String scaleFloat(float f) {// 保留6位小数
DecimalFormat df = new DecimalFormat("##0.000000");
return df.format(f);
}
}转载自:http://blog.fens.me/algorithm-pagerank-mapreduce/