TDengine database 作为国内的一款开源的时序数据库,虽然在 GitHub、DB-Ranking、墨天轮等技术网站都有很好的数据表现,在短短的几年中也斩获了无数用户的好评,但也不敢说什么是最好的数据库。TDengine 的创始人陶建辉老师总说,每个应用场景都有自己最合适的数据库,而我们要做的就是在最合适的领域做到行业的标准。所以与其说“最好用”,不如说“最适合”。
时序数据库有它典型的数据特征,开发人员普遍关心的读写性能、扩展能力等,也需要有独特的处理办法才能大幅度的提高效率,做到真正的降本增效。对比于市场上主流的软件,我们也做了一系列的性能对比,感兴趣的各位可以移步去看看
TDengine与InfluxDB对比测试 – TDengine Database | 涛思数据
TDengine与Cassandra对比测试 – TDengine Database | 涛思数据
TDengine与OpenTSDB对比测试 – TDengine Database | 涛思数据
我们官网上还有一个更多的数据库性能测试对比报告。
对于好坏,每人都有自己的标准,这里就不过多的赘述了。下面,我们针对 TDengine 的一些特性和用户案例,简单地讲讲什么是“最适合”的时序数据库。
使用场景
时序数据库是针对有时间戳的数据进行的优化处理的数据库,这就意味着特定的使用场景才会产生具有明显时间戳的数据。我们接触到的例如智能电表的数据、汽车行驶记录的数据、机床设备监控的数据等,很明显在诸如此类的使用场景下,产生的数据处理量也是万亿级的。那在这样的首要前提下,时序数据库才能发挥它的作用。这也是我为什么要做一款专门针对于物联网、车联网、工业互联网等场景设计和优化的大数据平台的原因所在。
TDengine 从产品发布到现在,持续累积了许多不同场景下的企业用户案例,如果你还是不理解什么是典型使用场景,可以参考下一些大厂的技术选型方案,希望能给你一些启发。
存储空间降为 MySQL 的十分之一,TDengine 在货拉拉数据库监控场景的应用 – TDengine Database | 涛思数据
TDengine 助力京东云 IoT 数据统计改造 – TDengine Database | 涛思数据
TDengine在理想汽车物联网业务场景的落地实践 – TDengine Database | 涛思数据
涛思数据官网以及 TDengine 公众号上还有近 60 个案例,都可以查看。
大幅提升数据插入和查询性能
物联网的数据是结构化的,因此 TDengine 采取的是结构化存储,而不是流行的 KV 存储。物联网场景里,每个数据采集点的数据源是唯一的,数据是时序的,而且用户关心的往往是一个时间段的数据,而不是某个特殊时间点。基于这些特点,TDengine 要求对每个采集设备单独建表。如果有1000万个设备,就需要建1000万张表。
基于这样的设计,任何一台设备采集的数据在存储介质里可以是一块一块连续的存放的,而且按照时间排序。因此查询单个设备一个时间段的数据,查询性能就有数量级的提升。另外一方面,虽然不同设备由于网络的原因,到达服务器的时间无法控制,是完全乱序的,但对于同一个设备而言,数据点的时序是保证的。一个设备一张表,就保证了一张表插入的数据是有时序保证的,这样数据插入操作就变成了一个简单的追加操作,插入性也能大幅度提高。
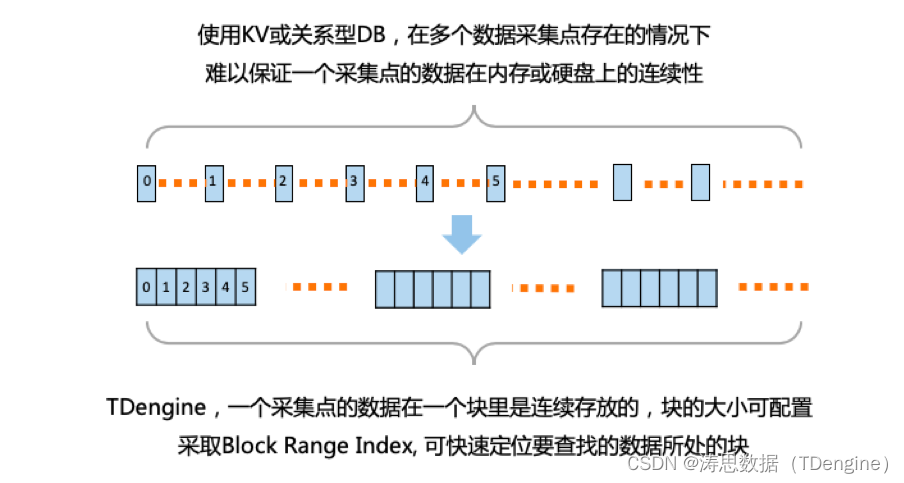
KV 存储的好处是不用定义数据库表结构,每条记录都可以变换格式。但在物联网、车联网这些场景里,一般数据格式是固定的,改动的频次很低,而且 TDengine 实现了一种高效的修改表结构的方法,因此 TDengine 采取格式化存储不会带来太大的不便。
大幅降低硬件或云服务成本
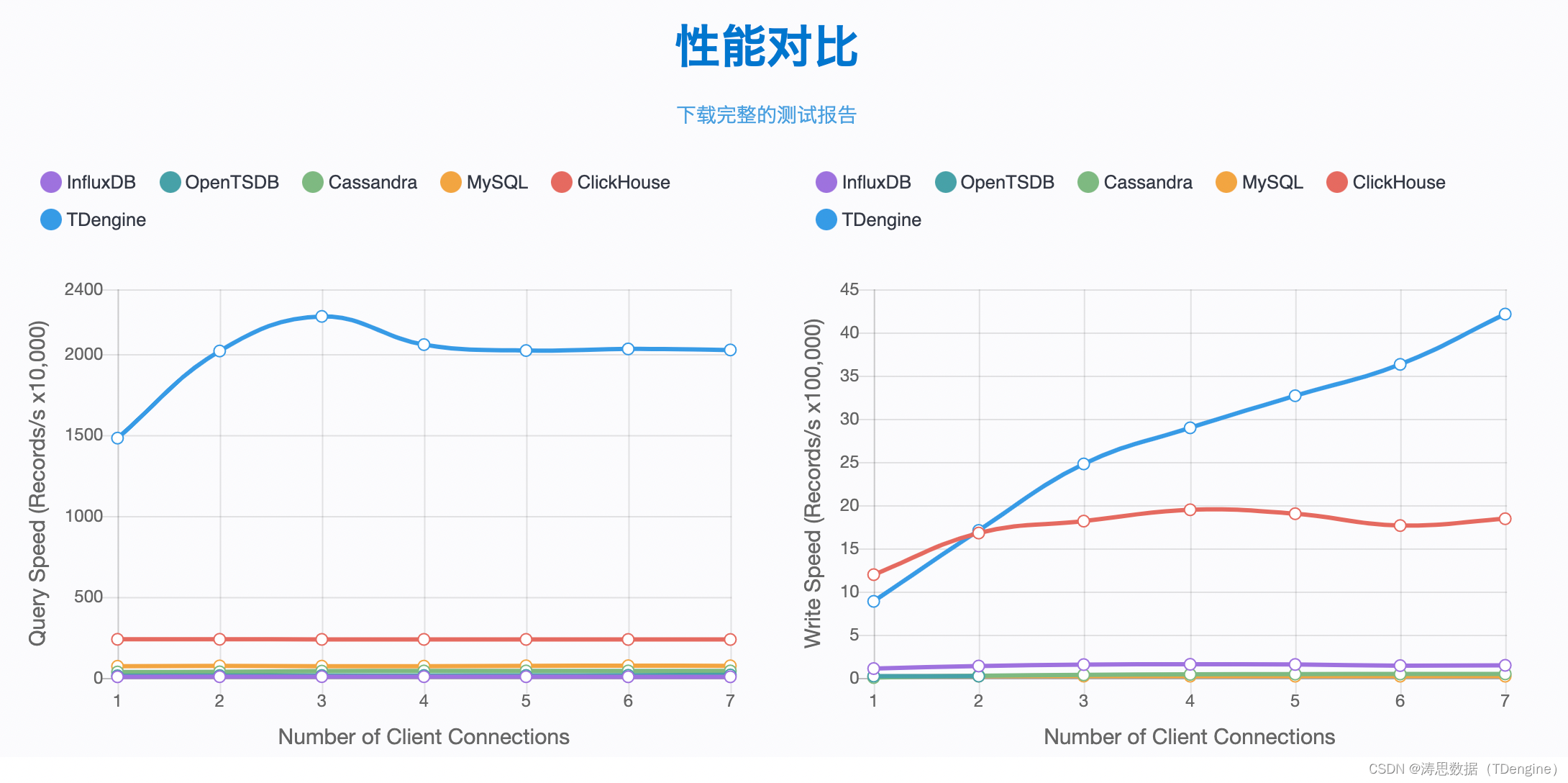
由于数据插入查询性能大幅度提升,系统所需要的计算资源就大幅减少。另外一方面,物联网采集的物理量的值是随时间改变的,但正常情况下,是渐变的,因此TDengine采取列式存储,将同一个物理量在多个时间点采集的值连续存放,这样能成倍的提高压缩效率。而且TDengine针对不同的数据类型采取不同的压缩方法,比如delta-delta 编码、simple 8B方法、zig-zag等等,这样更进一步的提高压缩率。与通用数据库相比,在已经测试过的物联网场景中,TDengine存储空间不到1/5,大幅节省存储资源。在TDengine公布的对比测试报告里,有如下的结果:
大幅简化大数据系统架构
与互联网应用不一样的是,物联网场景中,只要指定联网设备数量,数据采集频次,系统所需要的流量就可以较为准确地估算出来,不像双11,电商的流量可以几十倍的变化,而物联网的流量则较为平稳。同时,物联网设备都有一定的数据缓存能力,以防止网络连接失败,因此物联网平台对消息队列的需求没有那么强烈。TDengine内部实现了一简单的消息队列,同时提供订阅功能,这样就不需要使用Kafka等类似的消息队列软件了。
TDengine对数据库分配了固定的内存区域,新插入的数据,会先写入内存。内存按照先进先出的原则进行管理,内存不足时,老的数据会被持久化存储,而内存里的老数据会被最新的覆盖掉。TDengine还保证了任何一台设备最后一条记录一定在内存中,如果应用要获取每个设备的最新数据或状态,都将从内存里直接获取,这样的设计让系统可以不再需要Redis这类软件。
物联网数据是一个流数据,基于滑动窗口,TDengine后台定时的拉起查询计算,提供了一简化的流式计算,可以做各种实时的统计聚合操作,这样对于一般的物联网场景,不再需要使用Spark等类型的流式计算软件。
因此TDengine提供了大数据处理所需要的数据库、缓存、消息队列、流式计算等系列功能。使用TDengine,在物联网大数据平台中完全可以抛弃掉Kafka、HDFS、HBase、Spark和Redis等软件,大幅简化大数据平台的设计,降低研发成本大,而且系统将更加健壮,数据的一致性更有保证。
强大的历史数据分析能力
TDengine设计上让用户对历史数据和实时数据的处理完全透明,不区分历史数据和实时数据。用户只需要在SQL语句里指定时间段,TDengine自动决定是否从内存、从本地硬盘,还是从网络存储上获取数据,这样应用的实现变的简单。
每个设备的数据按块存储,而且每个数据块都已经做了预聚合(比如和、最大、最小值等),这样执行一个设备一个时间段的各种统计操作,有可能不用扫描原始数据,就能计算出来,性能大幅提升。即使有的计算需要扫描原始数据,但由于数据是一块一块连续存储的,读取速度远超通用数据库,计算分析速度也是大幅提升。而且由于结构化存储,解压后,不用做任何解析,读进内存就可以直接计算,相对于NoSQL数据库,计算分析速度也是大幅提升。
TDengine定义了一新的概念——超级表,用以描述同一类型的设备。给每个设备或表打上静态标签后,就可以用标签值筛出一部分满足过滤条件的设备,然后对这一部分设备的数据进行聚合。TDengine还设计了一特殊的机制,对于多个设备数据聚合,仅仅需要扫描一次数据文件,这样大幅减少IO操作次数,提高聚合计算速度。为提高易用性,用户可以通过TDengine自带的shell,或者Python、R、Matlab等工具直接进行各种Ad-Hoc的查询或分析。TDengine用来做物联网、车联网、工业互联网的数据仓库,会是一个理想的选择。
零运维管理,零学习成本
TDengine安装包很小,下载、安装几秒钟搞定。对于企业版,把一台机器加入集群一条命令就能完成,而且数据库是实时自动备份,不用手动分库分表,运维极其简单。系统使用标准的SQL,支持C/C++、Java、Python和Go等各种语言开发接口,支持JDBC,支持RESTful接口。使用起来就像是在使用MySQL,几乎不需要学习成本。
与第三方工具无缝集成
目前TDengine在数据采集侧,已经支持Telegraf、Kafka,后续还将支持MQTT、OPC等。在应用侧,已经支持Grafana可视化工具,支持Matlab,R以及一些BI工具。因为TDengine支持JDBC接口,很容易实现与第三方工具的接口,可以预见,更多的工具将会被无缝集成。
对于运维监测场景,不用写任何代码,只要将开源的Telegraf、Grafana与TDengine配置好,就可以迅速搭建一个高效的运维监测平台。
开源
TDengine由北京涛思数据技术有限公司自主开发,没有依赖任何第三方软件。研发时间已经超过5年,而且已经有一批付费商业客户,涉及电力、数控机床、智慧城市、车辆网等多个领域,客户的使用反馈都很不错。可喜的是,涛思数据将TDengine的核心存储、计算引擎完全开源。TDengine的社区版完全能满足一定规模的物联网、车联网、工业互联网的应用需求。因为涛思数据核心团队就在北京,相比其他开源软件,应该能够给中国的软件工程师提供更好的本地服务。
结语
简单做个总结,一款“合适”的时序数据库,需要因地制宜,因需制宜,因人制宜。盲目的评价一款软件的好坏是一种不负责任的做法,并不是涛思数据主张的价值观。同时作为一家开源软件的公司,我们也欢迎和鼓励大家给我们提出问题,在Github上(
https://github.com/taosdata/TDengine
)和我们的开发者多互动多交流。