推荐系统中常常需要在亿级别的候选集中找到上百个相关的item,俗称DCG问题(Deep candidate generation)。通常处理这类问题采用的类似语言建模的方法。然而显存的推荐系统都存在着曝光偏差,在候选集多的时候这个偏差更加的严重,导致模型只学习了曝光多的样本,因此这篇论文《Contrastive Learning for Debiased Candidate Generation in Large-Scale Recommender Systems》使用了对比学习去解决曝光偏差问题,该方法已经成功部署在淘宝,并且效果有显著提升。
DCG问题中的对比学习
首先我们可以拿到这样的数据集和,D={(xu,t,yu,t): u=1,2,…,N, t=1,2,…Tu},xu,t= {yu,1:(t-1)},即我们在预估t时刻用户要点啥时,用到的是该用户t时刻前点击的所有items。在DCG问题中,我们需要学习用户的encoder和item的encoder把用户和item映射到一个空间中,并通过cos相似度找到top k的item,典型的学习方式如下,使用最大似然估计(MLE)去拟合上述数据集合:
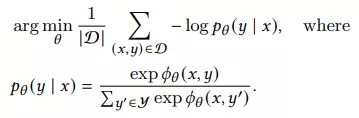
然而使用观测到的点击数据训练模型会有严重的曝光偏差问题,对有潜力但没机会曝光的item是毁灭性打击。很多高质量的item但是在训练数据集中点击较少,在MLE这种学习方式就很难再曝光。
如何理解对比学习能解决曝光偏差呢?
论文中使用的对比loss类似Sampled Softmax,先看看Sampled Softmax:
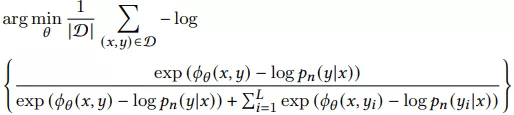
L表示负采样的个数,pn(y|x)是预先定义好的负采样分布,减去logpn(y|x)是为了让该loss收敛到和MLE相似的结果。在实践中pn(y|x)往往就使用pn(y),pn(y)就等同于流行度,使用该流行度加速收敛,在实践中L取值上千。当候选集巨大时,sampled softmax效果要优于NCE和negative sampling。
接下来我们讨论对比学习中的contrastive loss,在负采样概率分布为pn(y|x),loss如下:
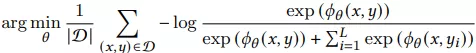
但是我们发现上式中不再减去logpn(y|x),因此该公式不再与MLE一致了,所以对比学习主要是优化pn(y|x)这个分布,使得模型收敛到合适的地方。
对比学习为什么能缓解曝光偏差?
让我们先看下IPW(inverse propensity weighted) loss:
q(y|x)就是调节loss的权重了,它可以是曝光的分布。实现IPW有两步,第一步用一个独立的模型(该模型作用就是得到q(y|x))并通过曝光产生的数据集拟合MLE loss,第二步拟合IPW loss,然而这种方式效率比较低下。
我们可以证明contrastive loss和IPW可以达到同样的效果,这两种方法都是最小化KL散度,证明过程可以参考论文附录。
CLRec
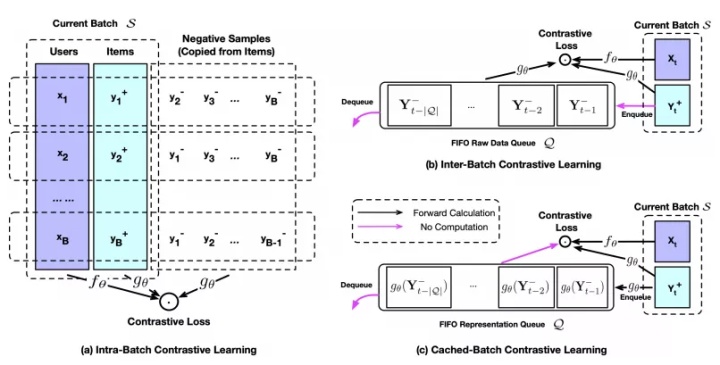
从上图中,我们可以清晰的看到负采样的方式,都近似pn(y|x)=pdata(y) (a)就是batch内负采样,(b)创建了一个固定大小的FIFO队列存取之前见到过的正例,然后用在当前batch内作为负样本。(c)和(b)不同在于队列直接缓存了encoder的结果。
如果是用IPW,很难估计到准确的q(y|x),CLRec就用q(y)代替q(y|x),q(y)和pdata(y)有高度相关性,很容易理解,系统曝光的item是因为这些item点击率较高,所以q(y)就可以近似pdata(y)。但是简单的使用pdata(y)进行负采样虽然可以缓解偏差,但是计算成本很高也不能保证每个item在一个epoch内被采样到,因此设计了(b)和(c)这种队列采样方法。(b)和(c)两种方法中,如果队列大小就是batch_size,那就等同于(a)方法。为了使得泛化效果更好,我们需要上千负样本,因此选择一个比较大的队列大小,但是较小的batch size去节约内存。e.g. batch size = 256 queue size = 2560。(b)和(c)本质区别时(c)需要更多steps才能收敛,因为梯度回传不到负样本,但是由于训练速度提升了,整体训练时间(c)是优于(b)的。论文中还提到了Multi-CLRec,缓解多意图偏差,感兴趣的可以看原文。
实验
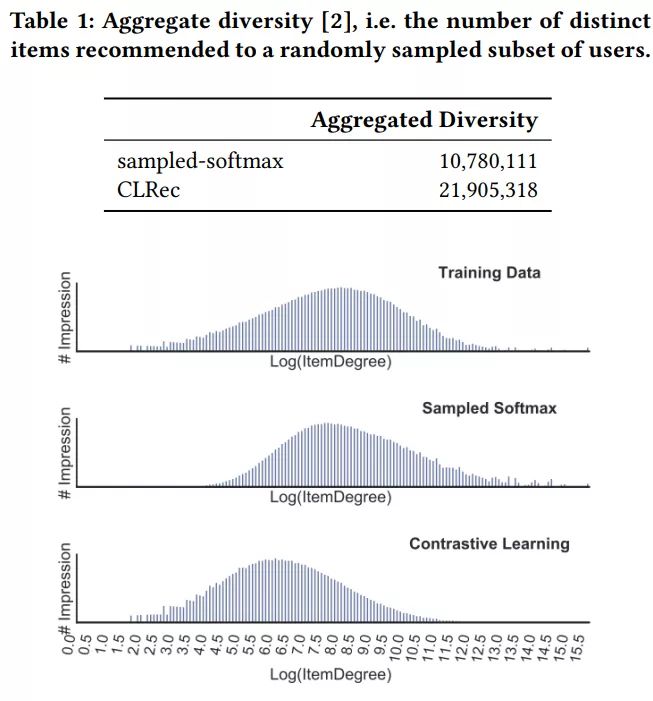
论文中的实验持续了至少4个月,离线评估纠偏时,比较了sampled softmax和CLRec,在不同loss下我们可以看到CLRec显著提高了多样性(提升了1倍),并且从曝光分布我们可以看到sampled softmax更拟合训练集的分布而CLRec学到了一个相对不同的分布从而缓解了曝光偏差:
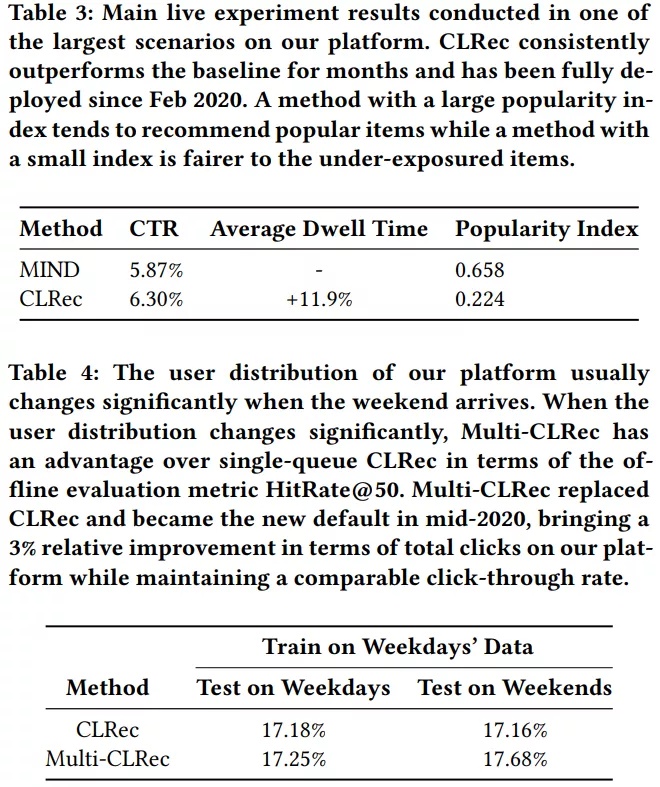
如果改变分布就是好的,那随机出岂不是更好?所以还必须对比点击率和recall才能真正说明CLRec是有效的,从下图我们可以看到CLRec提升了点击率和Recall:
参考文献
1、Contrastive Learning for Debiased Candidate Generation in Large-Scale Recommender Systems
https://
arxiv.org/pdf/2005.1296
4.pdf