我自己配置Hadoop的过程挺艰难的,东拼西凑找遍教程,可算把这配好了。特此写一个记录,以防日后所需,同时也希望能帮到大家。
目录
事先准备
| 软件 | 下载地址 |
|---|---|
| CentOS 7.4 |
https://www.centos.org/download/ |
| VirtualBox 6.0 |
https://www.virtualbox.org/wiki/Downloads |
| JDK 1.8 |
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html |
| Hadoop 2.6 |
https://hadoop.apache.org/releases.html |
| XShell 6 |
https://www.netsarang.com/zh/xshell/ |
| XFtp 6 |
https://www.netsarang.com/zh/xftp/ |
VirtualBox
安装CentOS
-
新建虚拟机
类型:
Linux
;版本:
Red Hat
32/64依自身情况

-
挂载镜像文件

-
启动并安装
;安装时选择
最小安装
即可

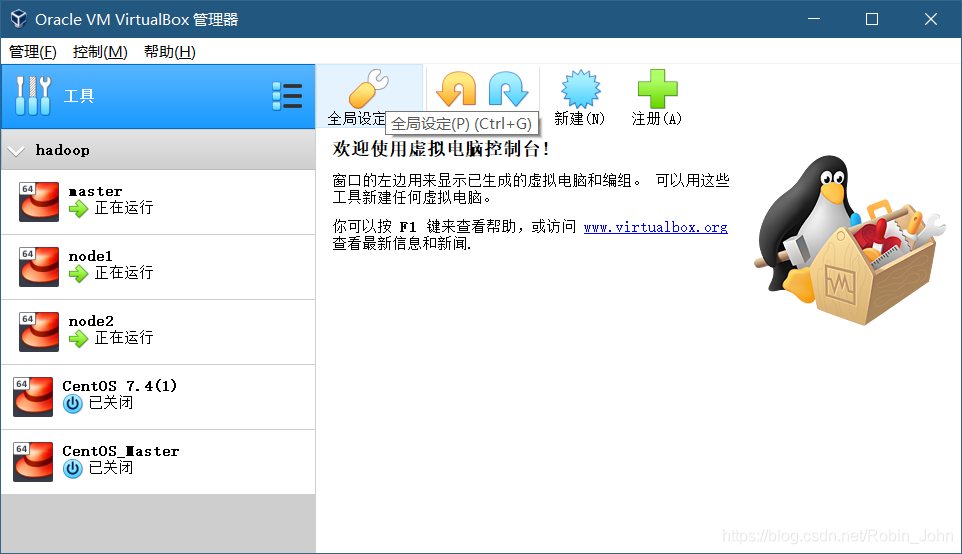
配置网络环境
-
网卡1

-
网卡2(这里使用的是WIFI,如果是有线网络 见3)

-
网卡2(有线网络)

-
CentOS中的网络设置:
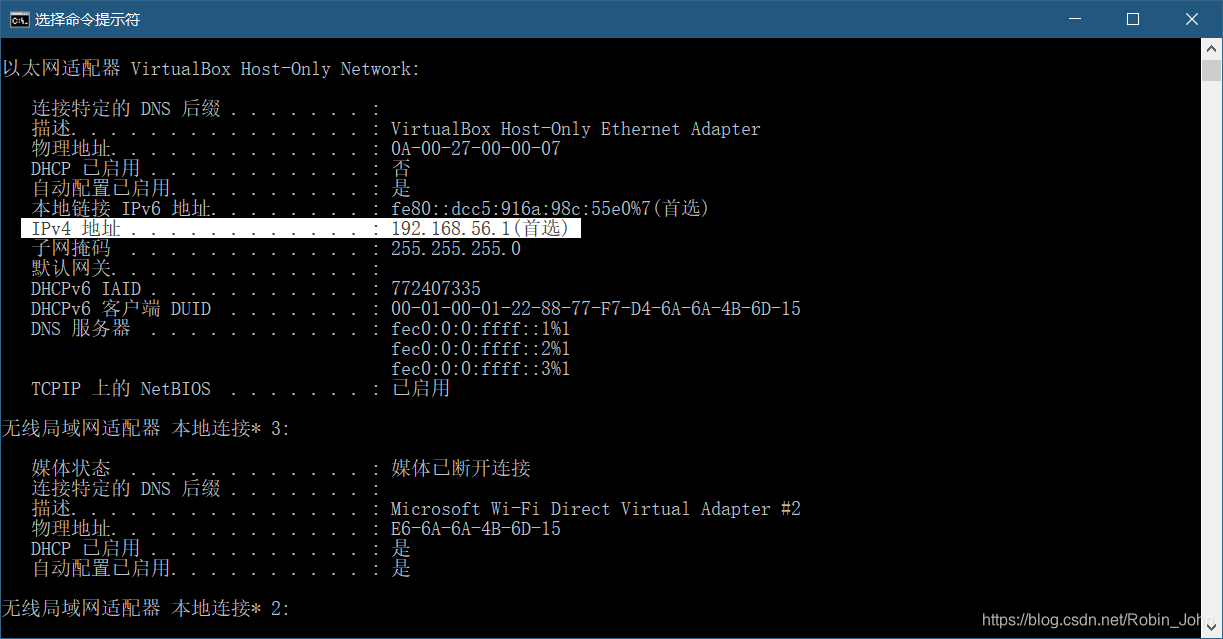
首先在windows中输入
ipconfig /all
查看网络配置。如图,我的虚拟机软件所分配到的ipv4为
192.168.56.1
;那么我们实际在虚拟机中的ipv4地址的范围应该是
192.168.56.2
~
192.168.56.255
。
接下来在CentOS中操作:
输入
ip add
查看网络配置1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 08:00:27:e7:0e:5b brd ff:ff:ff:ff:ff:ff inet 192.168.56.2/24 brd 192.168.56.255 scope global enp0s3 valid_lft forever preferred_lft forever inet6 fe80::9f23:fc55:29a7:6e2c/64 scope link valid_lft forever preferred_lft forever 3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 08:00:27:6d:1e:ed brd ff:ff:ff:ff:ff:ff inet6 2408:84ef:22:eab6:3cd8:95a0:8ce9:4ad9/64 scope global noprefixroute dynamic valid_lft 3363sec preferred_lft 3363sec inet6 fe80::22ed:6b14:3db9:426f/64 scope link valid_lft forever preferred_lft forever输入
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
编辑enp0s3网卡
修改其中的
ONBOOT
;
IPADDR
;
NETMASK
;
GATEWAY
TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=enp0s3 UUID=8b84fb8e-0a8c-4ed8-9d81-b33f2043980c DEVICE=enp0s3 ONBOOT=yes IPADDR=192.168.56.2 NETMASK=255.255.255.0 GATEWAY=192.168.1.1 PREFIX=24 DNS1=114.114.114.114设置完成后输入
service network restart
来重启网络
方便起见,这里可以先把防火墙关了,输入
systemctl stop firewalld.service
输入
systemctl status firewalld.service
确认防火墙已被关闭

如图: 防火墙已被关闭Active: inactive (dead)测试与实体机的连接
ping 192.168.43.1
,
Ctrl/Command
+
Z
停止ping
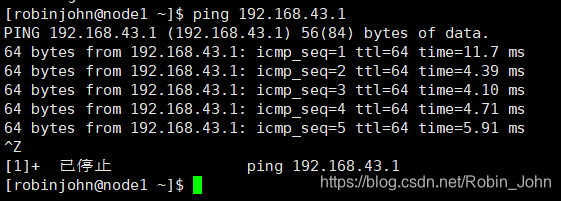
测试与外网的连接
ping www.baidu.com
回到实体机,打开cmd,输入
ping 192.168.56.2
测试与虚拟机的连接
Linux常用命令
管理员权限:
sudo
(下文配置时的指令操作如果出现错误,就在指令前加
sudo
)
防火墙状态:
systemctl status firewalld.service
关闭防火墙:
systemctl stop firewalld.service
编辑enp0s3网卡:
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
重启network:
service network restart
更改DNS
查看当前启动的连接:
nmcli connection show
更改DNS:
nmcli con mod enp0s3 ipv4.dns 114.114.114.114
配置生效:
nmcli con up enp0s3
配置hadoop文件:
cd /usr/local/hadoop-2.6.0/etc/hadoop
取消当前指令:
Ctrl/Command
+
Z
保存文件并退出:先按
Esc
;然后
Shift
+
;
(即输入“:”)最后输入
wq
XFtp 连接 CentOS
左上角新建连接

连接成功后,左边为本机文件,右边为虚拟机文件;可以通过右键本机文件将其上传至虚拟机

XShell 连接 CentOS
左上角新建连接

点击用户身份验证,输入用户名和密码

安装JDK
下载JDK 1.8:
链接
;

利用XFtp将文件发送到CentOS中。
输入
tar -zxvf jdk-8u202-linux-x64.tar.gz
解压文件
输入
mv jdk1.8.0_202 /usr/local/
将解压好的文件夹移动到usr/local文件夹下(个人习惯问题,可不移)

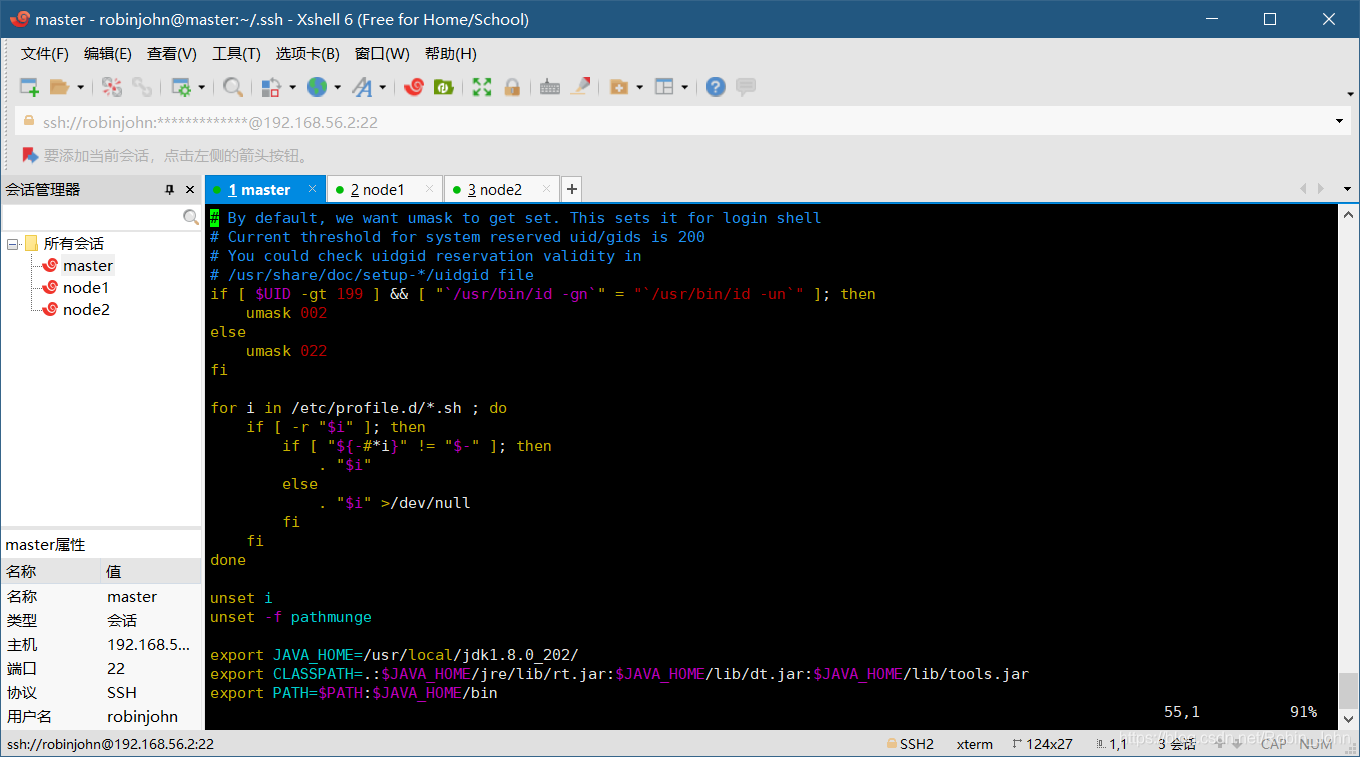
输入
vim /etc/profile
配置JDK环境;在文件最下面输入:
export JAVA_HOME=/usr/local/jdk1.8.0_202/
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
如图
输入
source /etc/profile
使方才的修改生效
输入
java -version
测试是否生效,如图:

Hadoop配置前期准备(Hadoop安装&SSH免密登录)
-
下载Hadoop 2.6
链接

利用XFtp将文件发送到CentOS中。
输入
tar -zxvf hadoop-2.6.0.tar.gz
解压文件
输入
mv hadoop-2.6.0 /usr/local/
将解压好的文件夹移动到usr/local文件夹下(个人习惯问题,可不移)
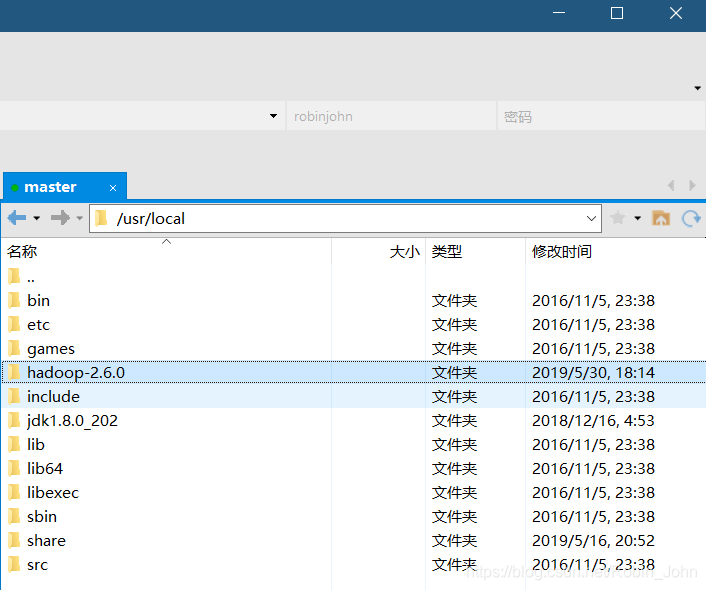
输入
vim /etc/profile
配置Hadoop环境;在文件最下面输入:export HADOOP_HOME=/usr/local/hadoop-2.6.0/ export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH如图:

输入
source /etc/profile
使方才的修改生效
输入
hadoop version
测试是否生效,如图:

-
首先为了方便我们访问,先分别为三台虚拟机设置主机名
hostnamectl set-hostname master
hostnamectl set-hostname node1
hostnamectl set-hostname node2
设置好后输入
vim /etc/hosts
配置hosts文件;在文件最下面输入192.168.56.2 master 192.168.56.3 node1 192.168.56.4 node2如图:

可使用
ping node1
测试是否连通 -
SSH配置
输入
rpm –qa | grep ssh
查看是否已经安装了SSH
如果未安装,输入
yum install ssh -y
安装SSH
输入
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
生成密钥(过程中无需输入参数,直接回车即可)
如图:这边已经生成过一次了,所以输入
y
覆盖
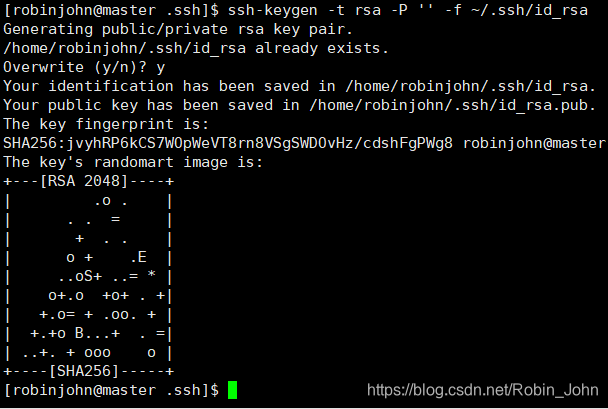
注意图中的:Your public key has been saved in /home/robinjohn/.ssh/id_rsa.pub.得知,我们的密钥被保存在了/home/robinjohn/.ssh/路径下
输入
cd /home/robinjohn/.ssh/
切换到该路径下
输入
ls
显示该目录下的文件,如图:

可以看到我们已经生成了id_rsa和id_rsa.pub文件
在该目录下,输入
cat id_rsa.pub >> authorized_keys
生成公钥
输入
ls
显示该目录下的文件,如图:

可以看到我们已经生成了authorized_keys文件
由于authorized_keys文件权限必须是600,所以我们输入
chmod 600 authorized_keys
修改其权限
修改完成后输入
systemctl restart sshd.service
重启服务使其生效
输入
ssh localhost
或
ssh master
使用SSH登录当前master主机,如图:
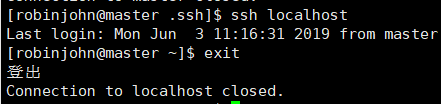
可以看到我们已经不需要密码了,测试完后别忘了使用
exit
登出。
输入
scp ~/.ssh/authorized_keys node1:~/.ssh
将我们的密钥发给node1结点;同理,输入
scp ~/.ssh/authorized_keys node2:~/.ssh
将密钥发给node2结点;如图:

输入
ssh node1
和
ssh node2
分别测试两个结点的免密登录,如图:
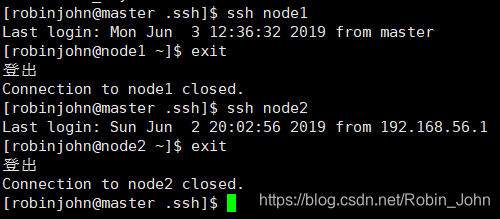
可以看到我们已经不需要密码了,测试完后别忘了使用
exit
登出。
此时,我们已经实现了master->node的免密登录,即:接下来,我们在node1和node2上分别执行
cat id_rsa.pub >> ~/.ssh/authorized_keys
保存公钥
cd ~/.ssh/
切换到保存公钥的路径
并输入
chmod 600 authorized_keys
修改其权限
修改完后别忘了输入
systemctl restart sshd.service
重启下服务
输入
scp ~/.ssh/authorized_keys master:~/.ssh
将公钥发送给master
好啦,我们来测试下能不能免密连上master,输入
ssh master
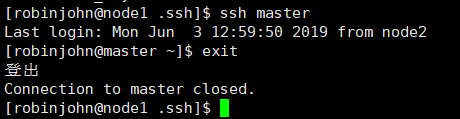
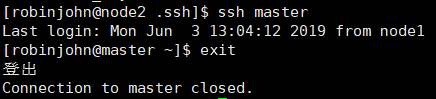
成功!~ 测试完别忘了
exit
退出登录。现在,我们实现了node->master的免密登录(双向),即:
Hadoop配置
1. 修改配置文件
由于我先前用
mv hadoop-2.6.0 /usr/local/
将解压好的文件夹移动到了usr/local文件夹下,那么我的配置文件目录则为/usr/local/hadoop-2.6.0/etc/hadoop/
如图:

输入
cd /usr/local/hadoop-2.6.0/etc/hadoop
切换到该目录下,并输入
ls
查看文件

我们一共需要修改7个文件:
hadoop-env.sh
yarn-env.sh
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
首先我们输入
vim hadoop-env.sh
打开hadoop-env.sh文件
由于hadoop在配置文件中需要JDK的绝对路径,所以。
在
export JAVA_HOME=${JAVA_HOME}
前加
#
对其注释
另起一行,写入
export JAVA_HOME=/usr/local/jdk1.8.0_202
,即:
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/local/jdk1.8.0_202
如图:
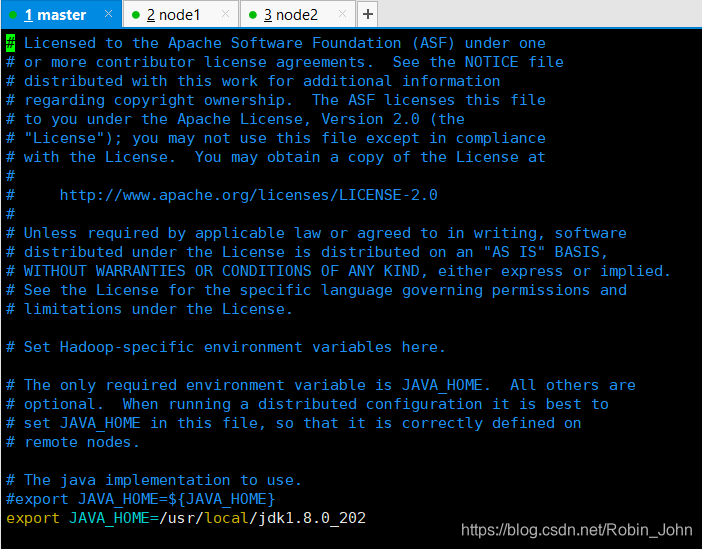
输入
vim yarn-env.sh
打开yarn-env.sh文件
在文件末尾加上
export JAVA_HOME=/usr/local/jdk1.8.0_202
,如图:

输入
vim slaves
修改slaves文件;slaves直译过来有奴隶的意思,我们把这个文件原来的内容全部删除,并往这个文件中添加
node1
node2
如图:
输入
vim core-site.xml
打开core-site.xml文件,做如下修改:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.6.0/tmp</value>
</property>
</configuration>
输入
vim hdfs-site.xml
打开hdfs-site.xml文件,做如下修改:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop-2.6.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.6.0/hdfs/data</value>
</property>
</configuration>
输入
vim mapred-site.xml
打开mapred-site.xml文件,做如下修改:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
输入
vim yarn-site.xml
打开yarn-site.xml文件,做如下修改:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
到这,master的hadoop已配置完成;剩下node1和node2结点按照上面的步骤一样配置。
很麻烦?不用怕;
输入
scp -r /usr/local/hadoop-2.6.0 node1:/usr/local/hadoop-2.6.0
将我们所有配置好的hadoop文件发送到node1结点上;
同理输入
scp -r /usr/local/hadoop-2.6.0 node2:/usr/local/hadoop-2.6.0
发送给node2。

2. 初始化并开启Hadoop
接下来的操作只需要在master中执行即可
首先输入
cd /usr/local/hadoop-2.6.0/bin
来到hadoop下的bin文件夹中
输入
./hadoop namenode -format
为第一次的开启执行初始化
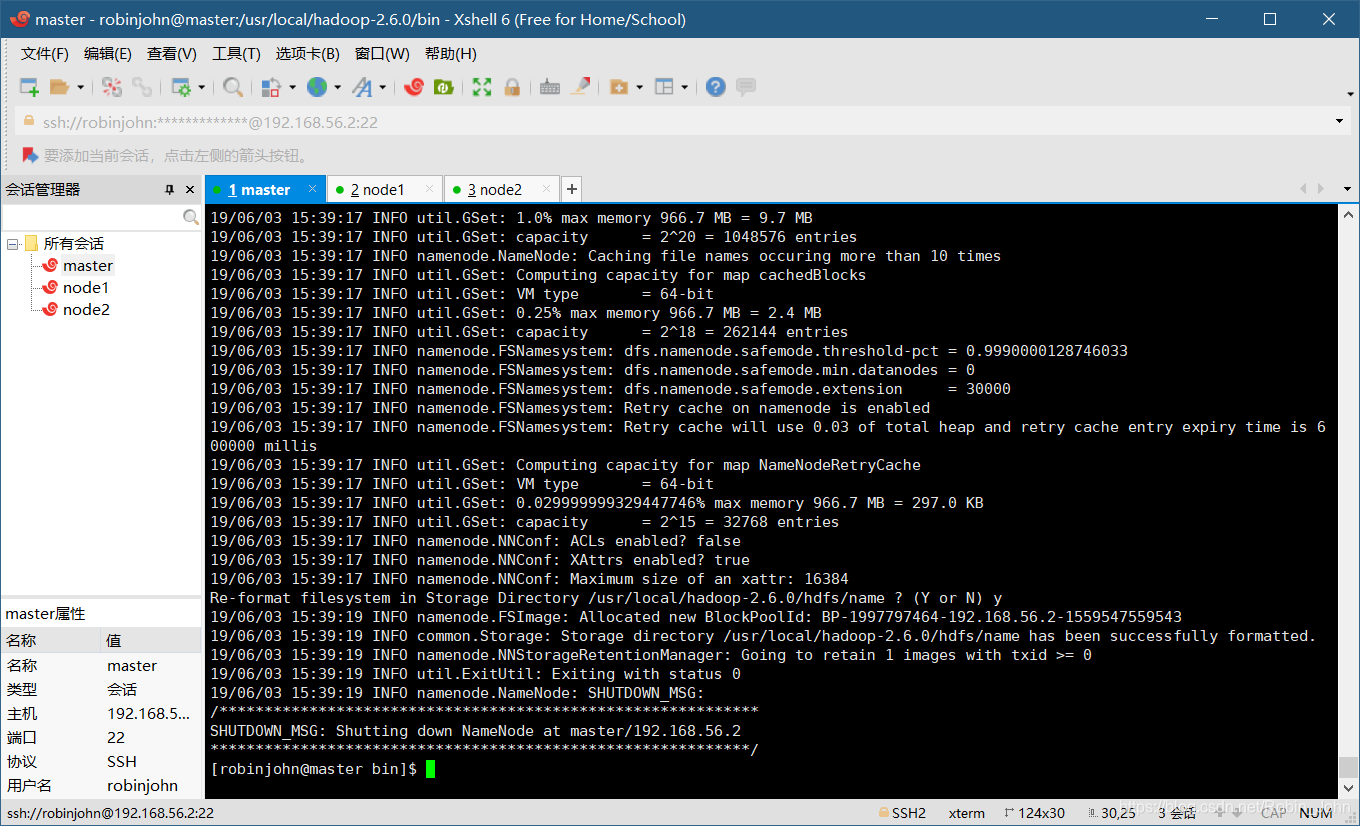
注意图中的
19/06/03 15:39:19 INFO util.ExitUtil: Exiting with status 0
如果最后的数字不是0,意味着在执行的时候出了某些错误;有可能是权限不足,在命令前加
sudo
再执行一次试试;
输入
cd /usr/local/hadoop-2.6.0/sbin
来到sbin文件夹中
输入
./start-all.sh
启动Hadoop
打开Hadoop的管理页面
http://192.168.56.2:50070
;如图:
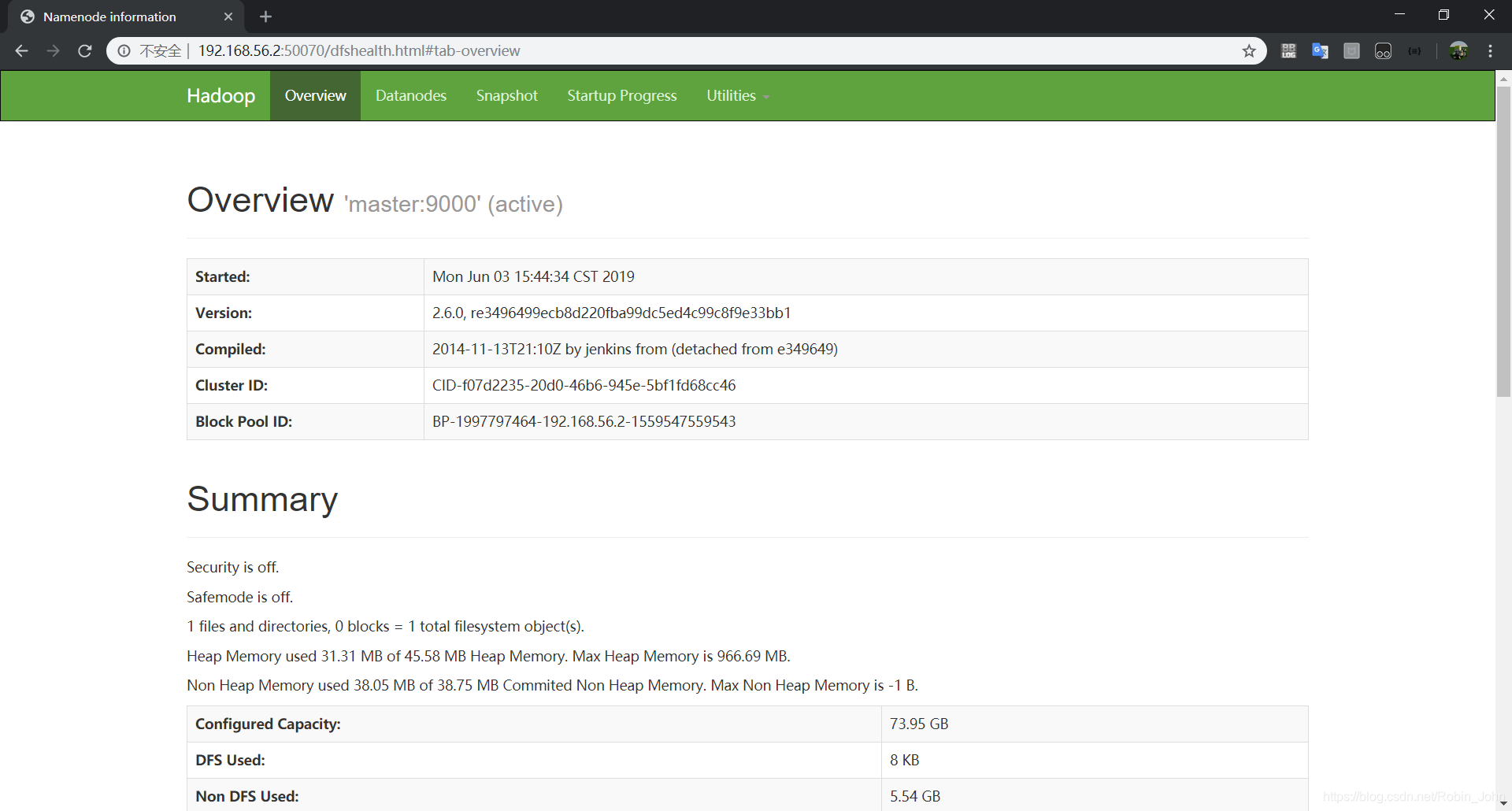
至此,Hadoop就成功配置完成了!
使用完后别忘了关闭,输入
./stop-all.sh
3. 一些常用的管理页面地址
master结点ip + :端口号
如
http://192.168.56.2:50070
50070
8088
19888
3306