1. 引言
现在有一个需求是从一个单词表中每次随机选取三个单词。
这个表的建表语句和如下所示:
mysql> Create table 'words'(
'id' int(11) not null auto_increment;
'word' varchar(64) default null;
primary key ('id')
) ENGINE=InnoDB;
然后我们向其中插入10000行数据。接下来我们看看如何从中随机选择3个单词。
2. 内存临时表
首先,我们通常会想到用order by rand()来实现这个逻辑:
mysql> select word from words order by rand() limit 3;
虽然这句话很简单,但是执行流程则比较复杂。我们使用explain来看看语句的执行情况:

Extra字段中Using temporary表示需要使用临时表,Using filesort表示需要进行排序。也就是需要进行排序操作。
对于InnoDB表来说
,执行全字段排序能够减少对于磁盘的访问,所以会被优先选择。
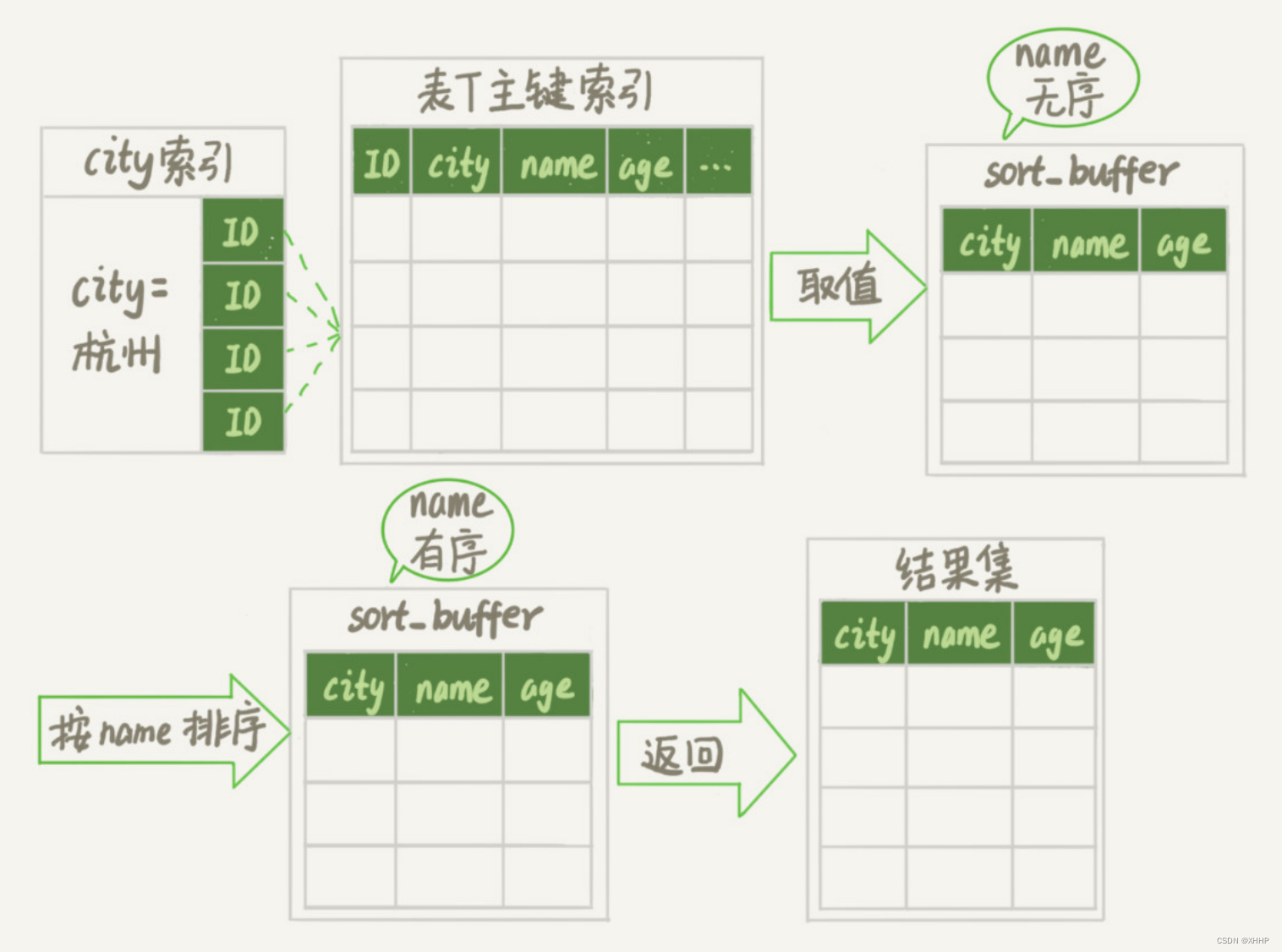
而对于内存表来说,回表过程只是简单地根据数据行的位置,直接访问内存得到数据,根本不会导致多访问磁盘
。所以这时MySQL会优选选择rowid排序。
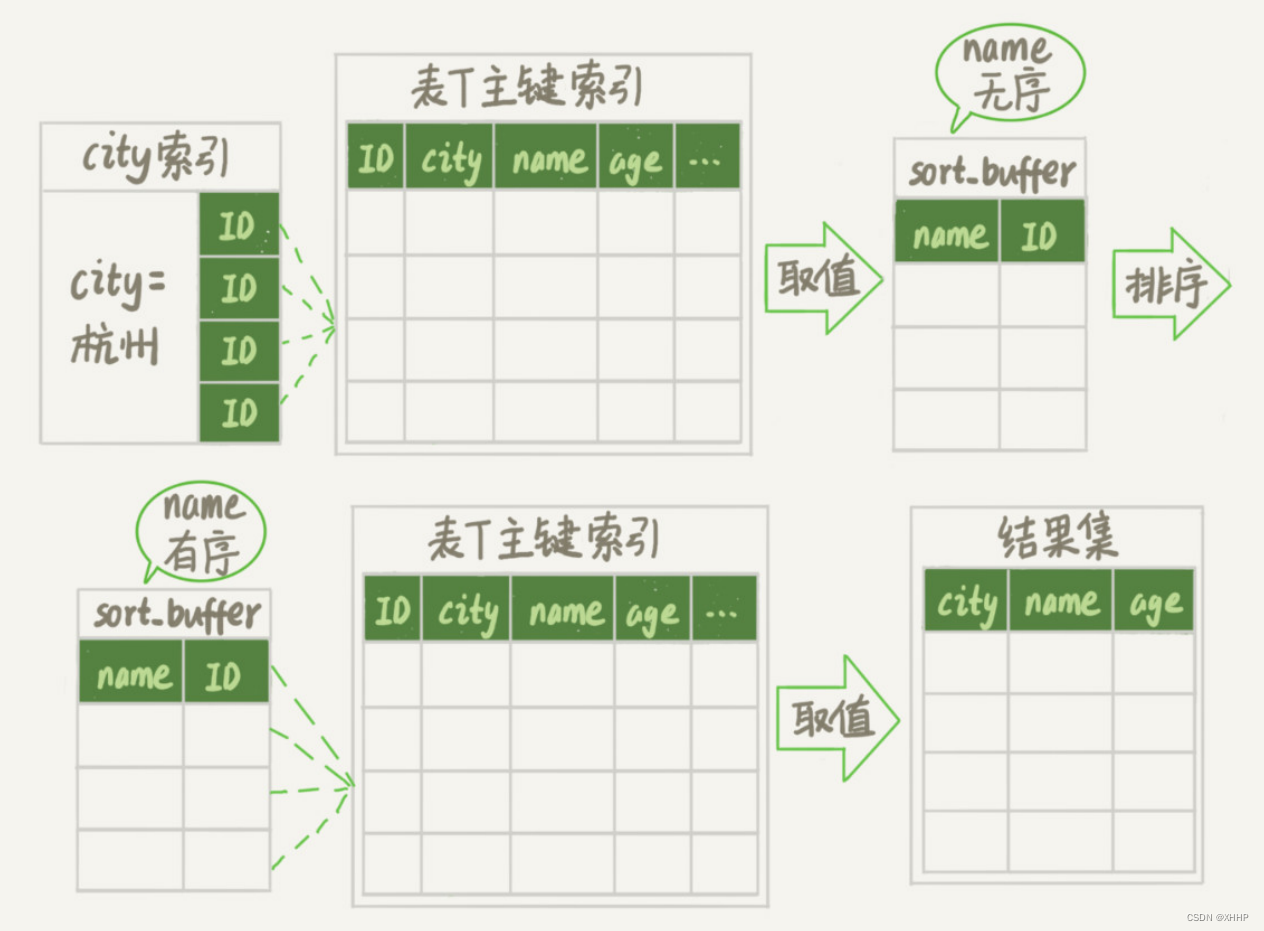
我们接下来再来梳理下这条语句的执行流程:
-
创建一个临时表,这个表使用memory引擎
,表里有两个字段,第一个字段是double类型,记为R,第二个字段是varchar(64)类型,记为W。并且这个表没有索引。 - 从words表中,按主键顺序取出所有的word。对于每个word,调用rand()函数随机生成一个大于0小于1的随机小数,并把这个随机小数和word分别存入临时表的R和W字段中。
- 接下来就是按照字段R进行排序
- 初始化sort_buffer。sort_buffer有两个字段,一个是double类型,另一个是整型。
-
从内存临时表中一行行取出R值和
位置信息
,分别存入sort_buffer的两个字段里。 - sort_buffer按照R值进行排序
- 排序完成后,取出前三个结果的位置信息,到内存临时表中取出相应的word,返回给客户端。
流程示意图如下所示:
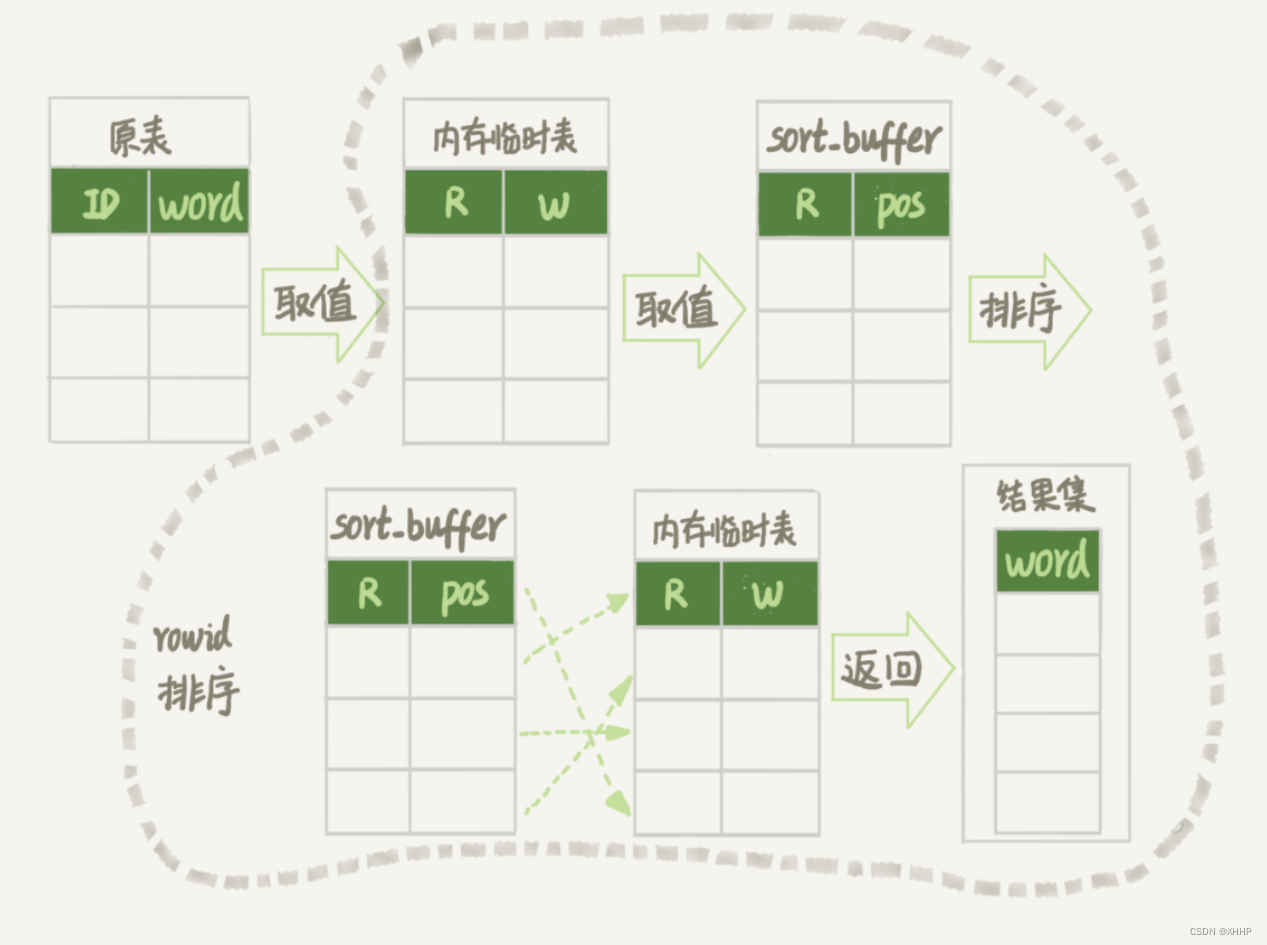
上面讲的位置信息,其实就是行所在的位置,也就是我们之前说的rowid。
对于InnoDB引擎来说,对于有没有主键表来说有两种处理方式:
-
对于
有主键的InnoDB表
来说,这个rowid就是主键id -
对于
没有主键的InnoDB表
来说,这个rowid是由系统生成的,用来标识不同行。
因此,
order by randn()使用了内存临时表,内存临时表的排序方法用的是rowid排序方法
。
3. 磁盘临时表
不是所有的临时表都是内存临时表
。tmp_table_size这个配置限制了内存临时表的大小,如果超过了这个大小,就会使用磁盘临时表。
InnoDB引擎就是默认使用磁盘临时表
。
4. 优先队列排序算法
在MySQL5.6之后,引入了
优先队列排序算法,这种算法是不需要使用临时文件的
。而原本的归并排序算法则是需要使用临时文件。
因为当你使用归并算法的时候,其实你只需要得到前3,但是你是用完归并排序,那已经整体有序了,造成了资源的浪费。
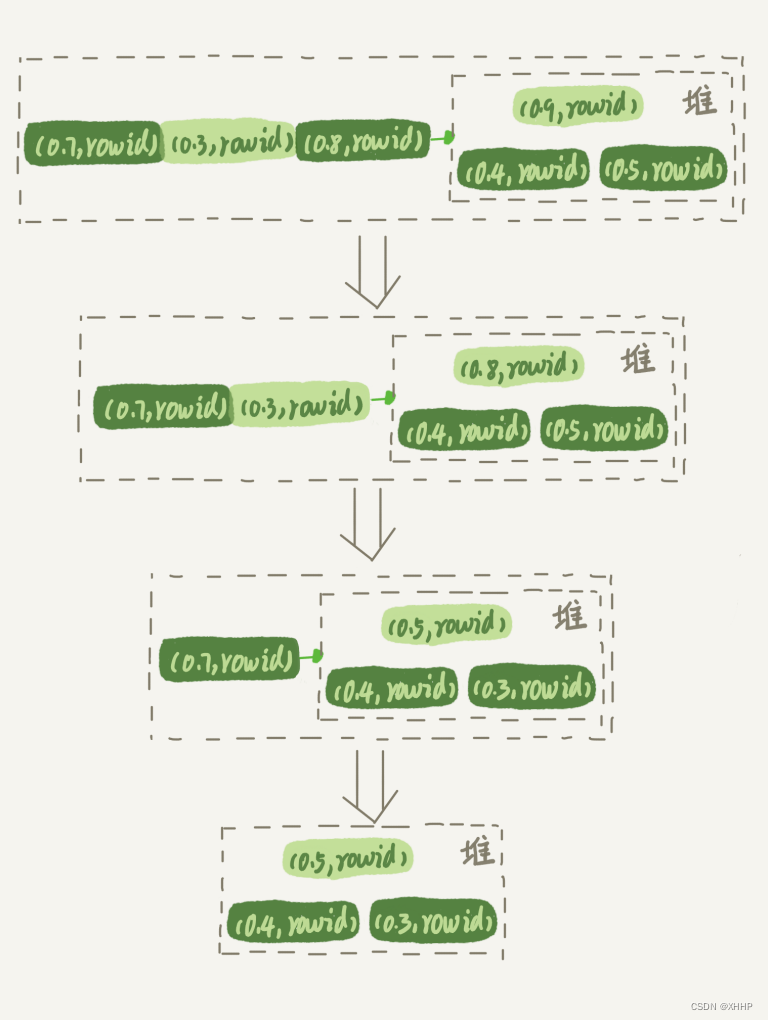
而优先队列排序算法则可以只取到前三,执行流程如下:
- 对于这10000个准备排序的(R,rowid),先取前三行,构造成一个堆,并且将最大的值放在堆顶;
- 取下一行(R’,rowid’),跟当前堆里面最大的R比较,如果R’小于R,则把(R,rowid)从堆中去掉,换成(R’,rowid’)。
- 不断重复上面的过程。
流程如下图所示:
但是当limit的数比较大时,维护堆比较困难,所以又会使用归并排序算法。
来源:自己整理的
MySQL实战45讲
笔记