TorchCRF使用笔记
1. 安装torchcrf,模型使用
安装
:pip install TorchCRF
CRF的使用
:在
官网
里有简单的使用说明
注意输入的格式。在其他地方下载的torchcrf有多个版本,有些版本有batch_first参数,有些没有,要看清楚有没有这个参数,默认batch_size是第一维度。
这个代码是我用来熟悉使用crf模型和损失函数用的,模拟多分类任务输入为随机数据和随机标签,所以最后的结果预测不能很好的跟标签对应。
import torch
import torch.nn as nn
import numpy as np
import random
from TorchCRF import CRF
from torch.optim import Adam
seed = 100
def seed_everything(seed=seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
num_tags = 5
model = CRF(num_tags, batch_first=True) # 这里根据情况而定
seq_len = 3
batch_size = 50
seed_everything()
trainset = torch.randn(batch_size, seq_len, num_tags) # features
traintags = (torch.rand([batch_size, seq_len])*4).floor().long() # (batch_size, seq_len)
testset = torch.randn(5, seq_len, num_tags) # features
testtags = (torch.rand([5, seq_len])*4).floor().long() # (batch_size, seq_len)
# 训练阶段
for e in range(50):
optimizer = Adam(model.parameters(), lr=0.05)
model.train()
optimizer.zero_grad()
loss = -model(trainset, traintags)
print('epoch{}: loss score is {}'.format(e, loss))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(),5)
optimizer.step()
#测试阶段
model.eval()
loss = model(testset, testtags)
model.decode(testset)
1.1模型参数,自定义掩码mask注意事项
def forward(self, emissions, labels: LongTensor, mask: BoolTensor)
分别为发射矩阵(各标签的预测值),标签,掩码(注意这里的mask类型为BoolTensor)
注意:此处自定义mask掩码时,
使用LongTensor类型的[1,1,1,1,0,0]会报错,需要转换成ByteTensor
,下面是一个简单的获取mask的函数,输入为标签数据:
def get_crfmask(self, labels):
crfmask = []
for batch in labels:
res = [0 if d == -1 else 1 for d in batch]
crfmask.append(res)
return torch.ByteTensor(crfmask)
2. CRF的损失函数是什么?
损失函数由
真实转移路径值
和
所有可能情况路径转移值
两部分组成,损失函数的公式为
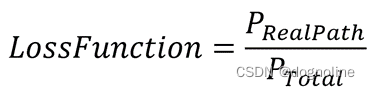
分子为真实转移路径值,分母为所有路径总分数,上图公式在crf原始代码中为:
def forward(
self, h: FloatTensor, labels: LongTensor, mask: BoolTensor) -> FloatTensor:
log_numerator = self._compute_numerator_log_likelihood(h, labels, mask)
log_denominator = self._compute_denominator_log_likelihood(h, mask)
return log_numerator - log_denominator
CRF损失函数值为
负对数似然函数(NLL)
,所以如果原来的模型损失函数使用的是交叉熵损失函数,两个损失函数相加时要
对CRF返回的损失取负。
loss = -model(trainset, traintags)
3. 如何联合CRF的损失函数和自己的网络模型的交叉熵损失函数进行训练?
我想在自己的模型上添加CRF,就需要联合原本的交叉熵损失函数和CRF的损失函数,因为CRF输出的时NLL,所以在模型在我仅对该损失函数取负之后和原先函数相加。
loss2 = -crf_layer(log_prob, label, mask=crfmask)
loss1 = loss_function(log_prob.permute(0, 2, 1), label)
loss = loss1 + loss2
loss.backward()
缺陷:
效果不佳,可以尝试对loss2添加权重。此处贴一段包含两个损失函数的自适应权重训练的函数。
3.1.自适应损失函数权重
由于CRF返回的损失与原来的损失数值不在一个量级,所以产生了
自适应权重调整两个权重的大小
来达到优化的目的。自适应权重原本属于多任务学习部分,未深入了解,代码源自某篇复现论文的博客。
class AutomaticWeightedLoss(nn.Module):
def __init__(self, num=2):
super(AutomaticWeightedLoss, self).__init__()
params = torch.ones(num, requires_grad=True)
self.params = torch.nn.Parameter(params)
def forward(self, *x):
loss_sum = 0
for i, loss in enumerate(x):
loss_sum += 0.5 / (self.params[i] ** 2) * loss + torch.log(1 + self.params[i] ** 2)
return loss_sum
结果:
就单任务而言,该自适应损失函数对模型性能有细微的差别,但相差不大。