目录
1.论文资料
作者:曾涵清博士,南加州大学
论文:在 ICLR 2020 上发表了
GraphSAINT: Graph Sampling Based Inductive Learning Method
代码:
https://github.com/GraphSAINT/GraphSAINT
2.传统GNN挑战:邻居爆炸(Neighbor Explosion)
邻居爆炸:
GNN会不断地聚合图中相邻节点的信息,则L-层的GNN中每个目标节点都需要聚合原图中L-hop以内的所有节点信息。在大图中,邻节点的个数可以随着L指数级增长。
- 邻点爆炸式增长,使得GNN的minibatch训练极具挑战性。
- 受显存的因素限制,GNN在不损失精度的前提下,难以高效地被拓展到大于两层的模型(否则指数爆炸)。
3.现有方法:图采样
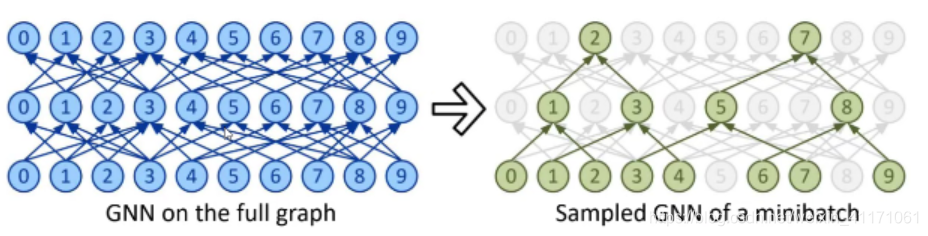
- Layer-wise Sampling:
-
邻居爆炸:在矩阵采样多层时,假设每层采样n个邻居,则会导致
n2
n^2
n
2
级别的节点扩充速度。 - 领接矩阵稀疏:在矩阵采样的过程中,会导致邻接矩阵稀疏化,丢失一些本来存在的边。
- 时间耗费高:每一层卷积都要采样,这就导致计算的时间耗费。
前人工作提出了众多
基于采样邻居节点
的方法,并利用
多类型的聚合函数
提高模型的表达能力。大部分现有工作都在探索如何通过
对GNN每层的节点进行采样
,以降低训练成本。
- Graph-wise Sampling:
- 从原图上采样一个子图下来,在这个子图上做局部的、完全展开的GCN。
- 解决了邻居采样的指数化问题,而且可以对采下来的子图进行直接的并行化,就大大的改进了效率。即,可以在preprocess阶段提前采样图,并且可以进行mini batch的加速。
- 但是这样的采样往往会丢失一些信息。
4.GraphSAINT:截然不同的采样的视角
-
属于
Graph sampling
。 -
从原图中采样子图,在子图上使用GCN学习。
-
基于极其轻量级的
子图采样
算法,同时实现了在准确率和复杂度上的显著提升。 - 提出了适用于大图以及深层网络的,通用的训练框架。
-
在标准的Reddit数据集上,以100倍的训练时间提速,提高了1%以上的准确率。
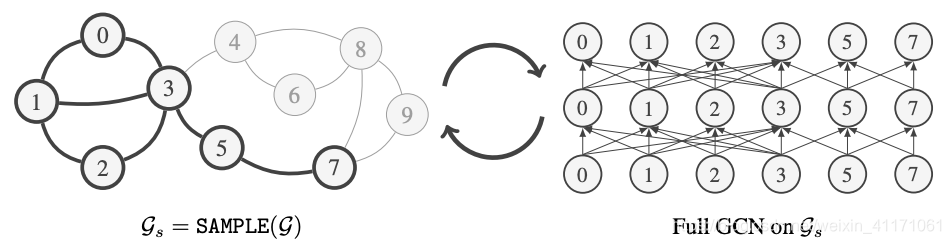
4.1.算法流程
将全图进行多次采样,在得到的sub-graph上进行全GCN,然后将多个sub-graph的信息融合起来。

4.2.子图采样

本文的采样是基于
节点的连通性
:
-
相互影响较大的节点应在同一子图中采样,intra sub-graph的节点是具有强联系的,但这就引入了采样的bias。理想的SAMPLE要求衡量节点连接的联合信息以及属性。但这种算法可能具有很高的复杂度,所以,为简单起见,从图连接性角度定义“影响力”,并设计基于拓扑的采样器。
2.为了消除保留图连通性特征的采样器引入的偏差,作者引入自行设计的归一化技术,以消除偏差,使得估计量无偏。归一化系数通过pre-processing估计出来。 - 每条边的采样概率均不可忽略,使得神经网络能够探索整个特征和标签空间。
- 考虑variance reduction(降低采样方差),旨在得到最小方差的边采样概率。
重点是
估计每个节点、边、子图的采样概率
。
节点采样概率:

边采样概率:
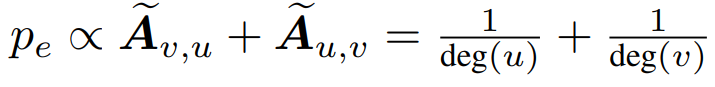
子图采样概率:

这篇文章的采样sub-graph的概念应该是介于AS-GCN的“有条件的采样全图”和ClusterGraph的“将图聚类后采样”之间。
由于采样的存在,FastGCN, AS-GCN等在不同的layer计算的是不同的图结构,而GraphSAINT, ClusterGraph可以看做在不同layer都对同一个graph进行特征提取。
4.3.实验结果:优于GCN, SAGE…
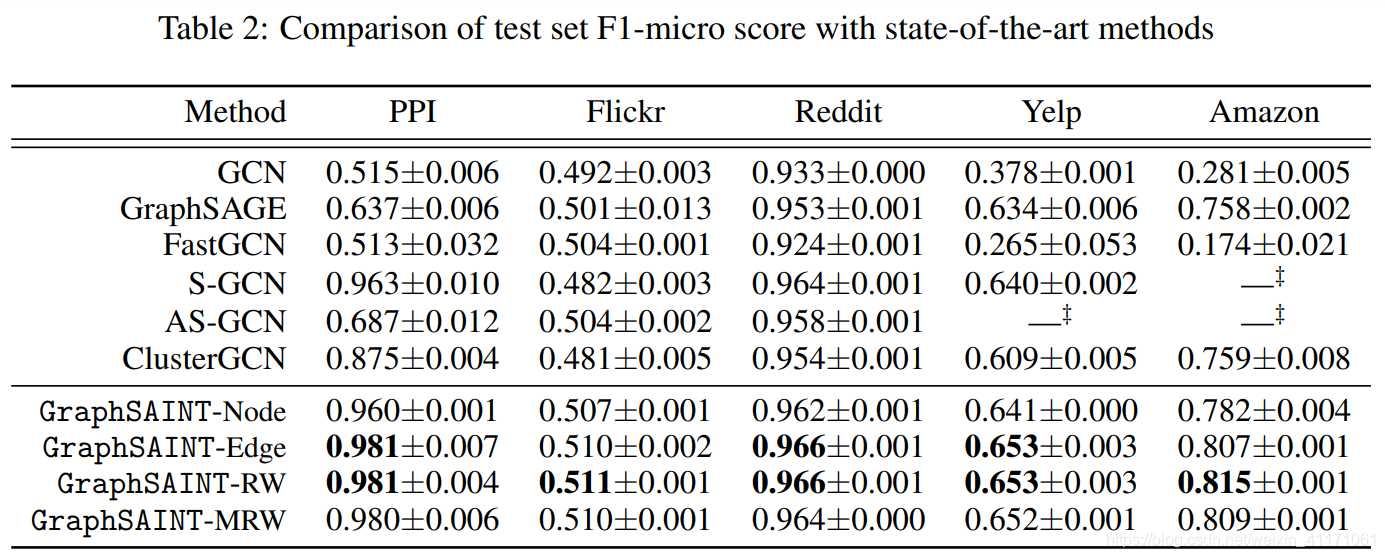
原因分析:
- GCN相当于full gradient descent,没有batch泛化好。
- GraphSAGE采样batch方差大,收敛性不好。
5.源码解读
5.1.安装依赖包
-
python >= 3.6.8 -
tensorflow >=1.12.0 / pytorch >= 1.1.0 -
cython >=0.29.2 -
numpy >= 1.14.3 -
scipy >= 1.1.0 -
scikit-learn >= 0.19.1 -
pyyaml >= 3.12 -
g++ >= 5.4.0 -
openmp >= 4.0 -
查看g++版本:
g++ -v
-
查看openmp版本:从GCC 4.2开始,编译器实现了OpenMP标准的2.5版本,从4.4开始,它实现了OpenMP标准的3.0版本。自GCC 4.7以来支持OpenMP 3.1。
-
$ echo |cpp -fopenmp -dM |grep -i open #define _OPENMP 200805 # _OPENMP宏名称被定义为具有小数值yyyymm,其中yyyy和mm是实现支持的OpenMP API版本的年和月指定 # 2008年5月 - 然后到http://www.openmp.org/specifications/,发现所提供日期与实际OpenMP版本号之间的映射。
5.2.数据准备
值得注意的是,要手动按照需要的格式来进行数据预处理
可参考源码/GraphSAINT/data/open_graph_benchmark/ogbn_converter.py
5.2.1.adj_full/train/test.npz
adj_full.npz:
a sparse matrix in CSR format, stored as a scipy.sparse.csr_matrix. The shape is N by N. Non-zeros in the matrix correspond to all the edges in the full graph. It doesn’t matter if the two nodes connected by an edge are training, validation or test nodes. For unweighted graph, the non-zeros are all 1.
adj_train.npz:
a sparse matrix in CSR format, stored as a scipy.sparse.csr_matrix. The shape is also N by N. However, non-zeros in the matrix only correspond to edges connecting two training nodes. The graph sampler only picks nodes/edges from this adj_train, not adj_full. Therefore, neither the attribute information nor the structural information are revealed during training. Also, note that only aN rows and cols of adj_train contains non-zeros. See also issue #11. For unweighted graph, the non-zeros are all 1.
adj_test.npz:
adj_train.npz格式一样就行啦。
all_nodes = list(node_data['vroleid']) # 节点名称:user_id
entity2id = dict(zip(all_nodes, range(0, len(all_nodes)))) # 对每个节点赋予一个index,存为dict
def read_triplets(edge_data, entity2id): #得到src和dst的成对数组
edge_data = np.array(edge_data[['vroleid', 'friend_roleid']])
triplets = []
for line in edge_data:
triplets.append((entity2id[line[0]], entity2id[line[-1]])) # src和dst的idx
return np.array(triplets) # np.array([[src1,dst1],...,[src10,dst10]]), shape = (None,2)
def obtain_adj_csr(triplets = all_triplets, node_num = len(entity2id)):
row_idx = np.append(triplets[:, 0], triplets[:, 1])
col_idx = np.append(triplets[:, 1], triplets[:, 0])
row_col_idx = np.vstack([row_idx, col_idx]).T # [vroleid, friend_roleid]和[friend_roleid, vroleid]在邻接矩阵里都需要是1,保证对称性
temp = set() #创建空集合
for item in tqdm(row_col_idx):
temp.add(tuple(item)) # 将数组转为元祖tuple,保证不被修改;再把元祖加入到集合中,完成去重
row_col_idx = np.array(list(temp)) # 将集合转换为列表,最后转为二维数组
csr_data = np.array([1] * row_col_idx.shape[0])
adj_csr = ss.csr_matrix((csr_data, (row_col_idx[:,0], row_col_idx[:,1])),
shape =(node_num, node_num))
return adj_csr
all_triplets = read_triplets(edge_data, entity2id)
train_triplets = read_triplets(train_edge_data, entity2id)
test_triplets = read_triplets(test_edge_data, entity2id)
adj_full = obtain_adj_csr(triplets = all_triplets, node_num = len(entity2id))
adj_train = obtain_adj_csr(triplets = train_triplets, node_num = len(entity2id))
adj_test = obtain_adj_csr(triplets = test_triplets, node_num = len(entity2id))
scipy.sparse.save_npz('./graphSAINT/GraphSAINT/data/gamelost/adj_full.npz', adj_full)
scipy.sparse.save_npz('./graphSAINT/GraphSAINT/data/gamelost/adj_train.npz', adj_train)
scipy.sparse.save_npz('./graphSAINT/GraphSAINT/data/gamelost/adj_test.npz', adj_test)
# 用numpy.savez_compressed是不行的!
5.2.2.feats.npy, class_map.json
class_map.json:
a dictionary of length N. Each key is a node index, and each value is either a length C binary list (for multi-class classification) or an integer scalar (0 to C-1, for single-class classification).
feats.npy:
a numpy array of shape N by F. Row i corresponds to the attribute vector of node i.
一定要注意feature的顺序!还有去掉非特征列/标准化/对NAN补0等。
# 保证feature的行顺序和adj_*.npz的一致。
user_order = all_nodes
feature['vroleid'].cat.reorder_categories(user_order, inplace = True)
feature.sort_values('vroleid', inplace = True)
feature.set_index('vroleid', inplace = True)
labels = np.array(feature['not_lost'].astype(np.int))
import json
class NpEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(NpEncoder, self).default(obj)
class_map = dict(zip(range(len(user_order)), labels))
class_map = json.dumps(class_map, cls=NpEncoder) # 直接用json.dumps(class_map)会报错。主要是版本问题。因此手动定义了NpEncoder类,
with open('./graphSAINT/GraphSAINT/data/class_map.json', 'w') as json_file:
json_file.write(class_map)
np.save('./graphSAINT/GraphSAINT/data/gamelost/feats.npy', feature)
5.2.3.role.json
a dictionary of three keys. Key ‘tr’ corresponds to the list of all training node indices. Key va corresponds to the list of all validation node indices. Key te corresponds to the list of all test node indices. Note that in the raw data, nodes may have string-type ID. You would need to re-assign numerical ID (0 to N-1) to the nodes, so that you can index into the matrices of adj, features and class labels.
role = dict()
role['tr'] = train_idx.tolist()
role['va'] = test_idx.tolist() # 无validation,直接用test
role['te'] = test_idx.tolist()
with open('./graphSAINT/GraphSAINT/data/gamelost/role.json','w') as f:
json.dump(role, f)
5.2.4.文件全部挪到同一个文件夹下
如./data/gamelost
5.3.修改模型(超)参数
- 详情见./GraphSAINT/train_config/README.md
- 作者详细描述了每个参数的含义和用法
- ./GraphSAINT/train_config/table2里包含了作者提供的对各个数据集的各种参数设置。可以直接copy成新文件修改,省的自己再折腾.yml格式了。
5.4.修改模型评估指标
- 修改./GraphSAINT/graphsaint/metric.py
- 源码是使用的F1-micro和F1-macro
- 我添加了Recall,Accuracy等
- 一定要注意y_pred和y_true的格式
from sklearn.metrics import confusion_matrix
def compute_acc(pred, labels):
y_pred = np.argmax(pred, axis = 1)
labels = np.argmax(labels, axis = 1)
tn, fp, fn, tp = confusion_matrix(labels, y_pred).ravel() # y_true, y_pred
accuracy = (tn+tp)/len(labels)
pos_acc = tp/sum(labels).item()
neg_acc = tn/(len(y_pred)-sum(y_pred).item()) # [y_true=0 & y_pred=0] / y_pred=0
neg_recall = tn / (tn+fp) # [y_true=0 & y_pred=0] / y_true=0
return neg_recall, neg_acc, pos_acc, accuracy
5.5.训练train.py
- ./GraphSAINT/graphsaint/pytorch_version/train.py
- 修改该文件下关于metrics的代码就可以了。
-
在linux下输入如下命令
python -m graphsaint.pytorch_version.train --data_prefix ./data/gamelost --train_config ./train_config/table2/gamelost_rw.yml --gpu 0
参考文献
https://zhuanlan.zhihu.com/p/107107009
https://rman.top/2020/05/20/GraphSAINT%E4%B8%80%E7%A7%8D%E6%97%A0%E5%81%8F%E7%9A%84%E5%9B%BE%E9%87%87%E6%A0%B7%E6%96%B9%E6%B3%95/
https://www.readercache.com/q/EP8b9Dpq4ZAw0ENEKGRr1zGKX5MRjeNY