文章目录
| 聚类 | 分类 |
|---|---|
| 无监督模式 | 有监督 |
| 不高度重视训练集 | 高度重视训练集 |
| 目的是找出相似的数据 | 目的是确认数据属于哪个类别 |
| 通常不涉及预测 | 通常需要预测 |
一、简介
聚类分析是无监督学习的一种,只需要数据,不需要标记结果,它可以把大量的观测值依据某种规则规约为若干个类,每个类内的观测值相似,每个类间的差异较大。
二、聚类分析
聚类分析思路很简单,总的来看可以分为2个环节——
距离度量
和
聚类算法
,即选定一种方式来计算数据点之间的距离,然后选用聚类算法进行聚类分析。
1. 距离度量
对于不同的数据类型,可选择的距离度量的方法主要有以下几种:
1.1 数值变量
数值变量是非常常见的一种变量,像人的身高、体重等等。假设
X
=
(
x
1
,
x
2
,
⋯
,
x
p
)
X=(x_1, x_2, \cdots, x_p)
X
=
(
x
1
,
x
2
,
⋯
,
x
p
)
,
Y
=
(
y
1
,
y
2
,
⋯
,
y
p
)
Y=(y_1, y_2, \cdots, y_p)
Y
=
(
y
1
,
y
2
,
⋯
,
y
p
)
是两个数值型的观测值,可以选择以下几种方法度量它们的距离:
-
Minkowski 距离
:
d(
X
,
Y
)
=
q
∣
x
1
−
y
1
∣
q
+
∣
x
2
−
y
2
∣
q
+
⋯
+
∣
x
p
−
y
p
∣
q
d(X, Y) =^q\sqrt{|x_1-y_1|^q+|x_2-y_2|^q+\cdots+|x_p-y_p|^q}
d
(
X
,
Y
)
=
q
∣
x
1
−
y
1
∣
q
+
∣
x
2
−
y
2
∣
q
+
⋯
+
∣
x
p
−
y
p
∣
q
-
Euclidean 距离
:是Minkowski距离
q=
2
q=2
q
=
2
时的特例, 是常见的欧式距离
d(
X
,
Y
)
=
∣
x
1
−
y
1
∣
2
+
∣
x
2
−
y
2
∣
2
+
⋯
+
∣
x
p
−
y
p
∣
2
d(X, Y) =\sqrt{|x_1-y_1|^2+|x_2-y_2|^2+\cdots+|x_p-y_p|^2}
d
(
X
,
Y
)
=
∣
x
1
−
y
1
∣
2
+
∣
x
2
−
y
2
∣
2
+
⋯
+
∣
x
p
−
y
p
∣
2
-
Manhattan 距离
: 是Minkowski距离
q=
1
q=1
q
=
1
时的特例
d(
X
,
Y
)
=
∣
x
1
−
y
1
∣
+
∣
x
2
−
y
2
∣
+
⋯
+
∣
x
p
−
y
p
∣
d(X, Y) =|x_1-y_1|+|x_2-y_2|+\cdots+|x_p-y_p|
d
(
X
,
Y
)
=
∣
x
1
−
y
1
∣
+
∣
x
2
−
y
2
∣
+
⋯
+
∣
x
p
−
y
p
∣
-
Mahalanobis 距离
:常用于Gaussian Mixture Model(GMM)
单个
数
据
点
:
D
M
(
x
)
=
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
单个数据点:D_M(x) = \sqrt{(x-\mu)^T\Sigma^{-1}(x-\mu)}
单
个
数
据
点
:
D
M
(
x
)
=
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
两个
数
据
点
:
D
M
(
x
,
y
)
=
(
x
−
y
)
T
Σ
−
1
(
x
−
y
)
两个数据点:D_M(x, y) = \sqrt{(x-y)^T\Sigma^{-1}(x-y)}
两
个
数
据
点
:
D
M
(
x
,
y
)
=
(
x
−
y
)
T
Σ
−
1
(
x
−
y
)
当数据的不同变量很多时候标度是不一样的,比如
x
1
x_1
x
1
是(2000,3000)之间的变量,
x
2
x_2
x
2
是(10, 20)之间的变量,我们要对数据进行标准化,一般情况下我们都是对数据进行Z-score标准化:
Z
f
=
X
f
−
m
e
a
n
f
S
f
Z_f = \frac{X_f-mean_f}{S_f}
Z
f
=
S
f
X
f
−
m
e
a
n
f
1.2 类别变量
类别变量又可分为无序类别变量和有序类别变量。
-
无序类别变量
:比如性别、国家、城市等,可利用
d(
X
,
Y
)
=
p
−
m
p
d(X, Y) = \frac{p-m}{p}
d
(
X
,
Y
)
=
p
p
−
m
,其中,
pp
p
为类别的个数,
mm
m
为
X,
Y
X, Y
X
,
Y
配对的个数。 -
有序类别变量
:比如low, medium, high,此时可先用每个值对应的排名
[1
,
2
,
⋯
,
n
]
[1, 2, \cdots, n]
[
1
,
2
,
⋯
,
n
]
来代替这个类别,再计算z-scores来标准化排名,此时排名化成了数值型变量,从而可利用那几种距离来衡量。
除了上述的距离度量方式,还可以用相关系数来度量数据点之间的距离。
2. 聚类算法
总的来说,聚类算法可分为两类,
层次聚类
(hierarchical agglomerative clustering)和
划分聚类
(partitionng clustering)。在层次聚类中,每一个观测值自成一类,这些类每次两两合并,直到所有的类被聚成一类,再根据问题的需求进行分析;在划分聚类中,需要先制定类的个数
k
k
k
,然后将数据随机分成
k
k
k
类,再重新形成聚合的类。
2.1 层次聚类
层次聚类的步骤
:
- 定义每个观测值为一类
- 计算每类和其他各类的距离
- 把距离最短的两类合并为一类,这样类的个数就少一个
- 重复步骤2和步骤3,直到包含所有观测值的类合并成单个的类为止
层次聚类算法
:
在层次聚类算法中,主要的区别是步骤2,即度量类与类之间的距离方式
| 聚类方法 | 两类之间的距离定义 | 备注 |
|---|---|---|
| 单联动 | 一个类中的点与另一个类中的点的最小距离 | 适合于细长的类 |
| 全联动 | 一个类中的点与另一个类中的点的最大距离 | 适合于相似半径的紧凑类,对异常值敏感 |
| 平均联动 | 一个类中的点与另一个类中的点的平均距离 | 适合于聚合方差小的类。 |
| 质心 | 两类中质心(变量均值向量)的距离。对单个观测值来说,质心就是变量的值 | 对异常值不敏感,但表现可能稍弱。 |
| Ward法 | 两个类之间所有变量的方差分析的平方和 | 适合于仅聚合少量值、类别数接近数据点数目的情况。 |
当需要嵌套聚类和有意义的层次结构时,层次聚类或许特别有用。 在生物科学中这种情况很常见。在某意义上分层算法是贪婪的, 一旦个观测值被分配给类,它就不能在后面的过程中重新分配。
层次聚类难以应用到有数百甚至千观测值的大样本中。
2.2 划分聚类
2.2.1 K-menas均值划分聚类的步骤
-
随机选择
kk
k
个初始中心点,
kk
k
是自己指定的 - 把每个数据点分配给离它最近的中心点
- 重新计算每个类新的中心点(平均值)
- 分配每个数据到它最近的中心点
- 重复步骤3和步骤4直到所有的观测点不被分配或达到最大的迭代次数
K-menas均值聚类能处理比层次聚类更大的数据集,这个方法很有可能被异常值影响,它对团状的数据点集区分度好,对非凸聚类(例如U型、带状(环绕)等)情况下也会变得很差。
K-menas均值聚类对异常值和K的选取都很敏感,而且一般要对数据进行标准化或中心化处理。
2.2.2 Mini Batch K-menas聚类
当数据量过大时,K-menas聚类会比较慢,此时可考虑使用Mini Batch K-menas聚类,即每次训练算法时随机抽取的数据子集,采用这些随机选取的数据进行训练,大大的减少了计算的时间,减少的KMeans算法的收敛时间,但要比标准算法略差一点。
为了避免随机抽取的子集分布不均匀,可以重复多次采样,再对计算到的类簇坐标计算均值,直到簇中心趋于稳定为止;或者可以人工设置迭代次数,直到满足迭代次数要求时停止。
2.2.3 K-menas++聚类
K-menas++聚类是对K-menas聚类的一种改进,原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。在选取第一个聚类中心(n=1)时同样通过随机的方法。可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。这个改进虽然直观简单,但是却非常得有效。

轮盘法
:在得到每个样本的概率后,计算累计概率,然后从(0, 1)中随机生成一个随机数,这个数落在哪个区间内,就选哪个点。
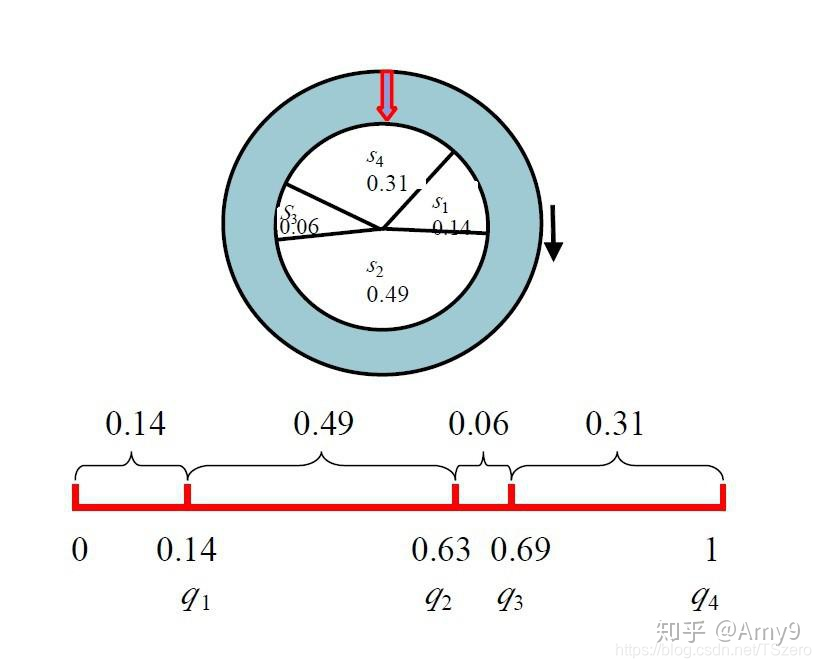
2.2.4 bi-kmeans算法
一种度量聚类效果的指标是SSE(Sum of Squared Error),他表示聚类后的簇离该簇的聚类中心的平方和,SSE越小,表示聚类效果越好。 bi-kmeans是针对kmeans算法会陷入局部最优的缺陷进行的改进算法。该算法基于SSE最小化的原理,首先将所有的数据点视为一个簇,然后将该簇一分为二,之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否能最大程度的降低SSE的值。
步骤
:

2.2.5 kernel K-means
基于欧式距离的 K-means 假设了了各个数据簇的数据具有一样的的先验概率并呈现球形分布,但这种分布在实际生活中并不常见。面对非凸的数据分布形状时我们可以引入核函数来优化,这时算法又称为核 K-means 算法,是核聚类方法的一种。核聚类方法的主要思想是通过一个非线性映射,将输入空间中的数据点映射到高位的特征空间中,并在新的特征空间中进行聚类。非线性映射增加了数据点线性可分的概率,从而在经典的聚类算法失效的情况下,通过引入核函数可以达到更为准确的聚类结果。
2.2.6 中心划分(PAM)划分聚类的步骤:
-
随机选择
kk
k
个初始中心点 - 计算观测值到各个中心的距离/相异性
- 把每个观测值分配到最近的中心点
- 计算每个中心点到每个观测值的距离的总和(总成本)
- 选择一个该类中不是中心的点,并和中心点互换
- 重新把每个点分配到距它最近的中心点
- 再次计算总成本
- 如果总成本比步骤(4)计算的总成本少,把新的点作为中心点
- 重复步骤5~8直到中心点不再改变
中心划分(PAM)划分聚类相比与K-menas均值聚类,更加稳健,可以使用任意的距离来计算。
三、DBSCAN聚类分法
这里
是DBSCN的可视化,可以更好的理解该算法
四、聚类指标
4.1 外部评价标准
外部评价标准需要给定 truth label 才能对 cluster label 进行评价,但是均不要求后者的类标与前者一致。
常见的外部评价标准有纯度(Purity),归一化互信息(NMI),兰德指数(Rand index, RI),调整兰德指数(Adjusted Rand index, ARI)等。具体可参考
聚类评价指标
除了上述几种指标,还有Jaccard系数。
J
I
=
a
a
+
b
+
c
JI = \frac{a}{a+b+c}
J
I
=
a
+
b
+
c
a
, 其中,
a
a
a
表示两个数据对象在划分的类
C
C
C
中同一族,且在已知的类
P
P
P
中同一族;
b
b
b
表示两个点在
C
C
C
中同一族,但在
P
P
P
中不同组;
c
c
c
表示两个点不属于
C
C
C
中同一族,而在
P
P
P
中属于同一族;
d
d
d
表示两个点不属于
C
C
C
中同一族,且在
P
P
P
中也不属于同一族。指标的评价值越大,说明聚类结果与真实划分结果越相近,聚类效果越好。
4.2 内部评价标准
当没有给定 truth label时,可采用内部评价标准。常见的内部评价标准有邓恩(Dunn)指标、轮廓系数、CH指标、XB指标等。详见下图:




除了上述几种指标,还有组内误差平方和(SSE):
S
S
E
=
∑
i
=
1
r
∑
j
=
1
n
i
(
X
i
j
−
X
ˉ
i
)
2
,
X
ˉ
i
=
1
n
i
∑
j
=
1
n
i
X
i
j
,
i
=
1
,
2
,
⋯
,
r
SSE=\sum_{i=1}^{r}\sum_{j=1}^{n_i}(X_{ij}-\bar X_i)^2, \bar X_i=\frac{1}{n_i}\sum_{j=1}^{n_i}X_{ij}, i=1, 2, \cdots, r
S
S
E
=
i
=
1
∑
r
j
=
1
∑
n
i
(
X
i
j
−
X
ˉ
i
)
2
,
X
ˉ
i
=
n
i
1
j
=
1
∑
n
i
X
i
j
,
i
=
1
,
2
,
⋯
,
r
组间误差平方和(SSA):
S
S
A
=
∑
i
=
1
r
n
i
(
X
ˉ
i
−
X
ˉ
)
2
,
X
ˉ
=
1
n
∑
i
=
1
r
∑
j
=
1
n
i
X
i
j
SSA = \sum_{i=1}^rn_i(\bar X_i-\bar X)^2, \bar X = \frac{1}{n}\sum_{i=1}^r\sum_{j=1}^{n_i}X_{ij}
S
S
A
=
i
=
1
∑
r
n
i
(
X
ˉ
i
−
X
ˉ
)
2
,
X
ˉ
=
n
1
i
=
1
∑
r
j
=
1
∑
n
i
X
i
j