文章目录
一、摘要
本文主要介绍在Spring框架中,Mysql事务的处理方式。涉及到的内容有JAVA语言相关的,JDBC,Mybatis,Spring事务以及和语言无关的Mysql的Innnodb存储引擎的相关原理。如果读者对Mysql相关原理已经很清晰,可以直接跳过。
二、基础知识介绍
2.1 JDBC
2.1.1 简单示例
JDBC(Java DataBase Connectivity,java数据库连接)为JAVA提供了通用的数据访问API,我们可以通过它来建立SQL数据库连接并访问数据库。官方文档:
https://docs.oracle.com/javase/tutorial/jdbc/basics/index.html
简单事务的代码片段:
try {
// 获取数据库连接
conn = DriverManager.getConnection("url","username","userpwd");
//禁止自动提交,开启事务
conn.setAutoCommit(false);
stmt = conn.createStatement();
//数据库更新操作1
stmt.executeUpdate("update table …");
//数据库更新操作2
stmt.executeUpdate("insert into table …");
//事务提交
conn.commit();
}catch(Exception ex) {
// 操作异常,回滚事务
conn.rollback(); //操作不成功则回滚
}
2.1.2 JDBC事务存在的问题:
分层架构中,事务控制应该放在哪一层?事务是以业务逻辑为基础的;一个完整的业务应该对应服务层里的一个方法;如果业务操作失败,则整个事务回滚;所以,事务控制是应该放在service层的。否则,如果把事务放在DAO(Data Access Object)层中,请看下面的例子:
想要将这两个操作放在一个事务中,你可以会这样设计ClassDAO:
public class ClassDAO {
private Connection conn = DBManager.getConnection;
public void delClassAndClassStuReal(String classId) {
try {
conn.setAutoCommit(false);
//班级的删除
//班级学生关系记录的删除
conn.commit(); //事务提交
} catch(SQLException e) {
try {
conn.rollback();
}
}
}
}
但是,DAO层的设计应该遵循一个很重要的原则:DAO层应该保证操作的原子性,就是说DAO里的每个方法都应该是不可以分割的。基于DAO层设计的细粒度原则,classDAO中应该是有这样两个方法:
public class ClassDAO {
public void delClass(String classId) {
//班级的删除
}
public void delClassStuReals(String classId) {
//班级学生关系记录的删除
}
}
那JDBC事务的问题就来了:
jdbc中事务控制是基于Connection的;虽说事务控制应该放在service层,我们也可以在service层实例化connection再将其传递给DAO层。但是Connection是不应该在service层中被实例出来的,service层不应该保存并感知数据库连接的,否则将存在service层与DAO层明显的耦合,底层的DAO层居然依赖了上层的service层。
2.1.2 Spring事务解决该问题的方式
Spring通过采用AOP以及ThreadLocal的方式,来解决这种耦合问题。
2.2 AOP设计思想
2.2.1 代理模式
代理模式的意图是为某一类对象提供一种代理,以控制对这个对象的访问,从而对被代理对象的功能进行扩展或者拦截。
同样增强扩展对象功能的模式还有装饰器模式,它们的区别在于装饰器模式在于给对象动态的添加一些额外的功能,对于这些功能的扩展是可以在对象创建完成后动态的更改的,而代理模式是组合模式和继承模式的一种折衷,代理模式是在获取对象时确定代理对象,它的扩展功能在对象创建后已经确定了,而装饰模式可以理解为装饰器和实际对象可以灵活组合。
代理模式针对的是整个类,装饰器模式可能更加偏向于针对某个对象。
2.2.2 静态代理
静态代理就是实现一个类,它和被代理对象实现同样的接口,来代替原有类,以实现功能的扩展。简单的示例代码如下,我们想为MySqlServiceReal类的getName()方法增加一个日志打印功能,于是我创建了MySqlServiceProxy代理类。
public class StaticProxy {
public static void main(String[] arg){
MySqlServiceReal real = new MySqlServiceReal();
MySqlServiceProxy proxy = new MySqlServiceProxy(real);
proxy.getName();
}
private static class MySqlServiceProxy implements MySqlServiceInterface {
private MySqlServiceInterface target;
MySqlServiceProxy(MySqlServiceInterface source) {
this.target = source;
}
@Override
public String getName() {
System.out.println("before getName");
String name = target.getName();
System.out.println("after getName");
return name;
}
}
private static class MySqlServiceReal implements MySqlServiceInterface {
@Override
public String getName() {
System.out.println("execute something sql");
return "sql result";
}
}
private interface MySqlServiceInterface {
String getName();
}
}
静态代理存在的问题:
当有一个业务无关的通用功能例如日志打印,数据上报等需要同时给多个类使用,那么如果采用静态代理的方式的话,则需要实现多个代理类,使得代理类过多。
2.2.3 动态代理
动态代理解决了静态代理中同时给多个类新增一个相同的代理功能时,产生过多代理类的问题。动态代理的动态指的是可以根据被代理的类或接口,动态的生成代理类,对于同一种代理功能我们只需要实现一次即可,减少代码的冗余。Spring的AOP就是采用动态代理的方式来达到增强原有代码的目的。
动态代理更像一个代理对象生成器,输入参数为被代理的类或接口加上被代理的对象(可选)来生成一个实现了代理接口的类的对象。
JAVA中常用的动态代理有两种方式,一种是基于反射的JDK动态代理,一种是基于字节码生成操作的CGLIB代理。简单的示例代码如下:
1. JDK动态代理
:
我们为两个不同的类MySqlServiceReal和MySqlServiceReal2同时增加了日志打印功能,我们功能Proxy.newProxyInstance来生成了代理对象,将代理功能的实现编码在ProxyInvokeHandler对象中,来起到拦截方法调用的功能,以控制对象的访问。
JDK动态代理必须要求代理类实现了某一个接口,该代理方式的原理是通过反射动态地实例化一个实现了该接口的对象,然后将该对象的所有方法调用都使用InvocationHandler进行拦截。
public class JdkDynamicProxy {
public static void main(String[] arg) {
MySqlServiceReal real1 = new MySqlServiceReal();
MySqlServiceReal2 real2 = new MySqlServiceReal2();
ProxyInvokeHandler proxyHandler = new ProxyInvokeHandler(real1);
ProxyInvokeHandler proxyHandler2 = new ProxyInvokeHandler(real2);
MySqlServiceInterface proxy1 = (MySqlServiceInterface)Proxy.newProxyInstance(
MySqlService.class.getClassLoader(),
new Class[]{MySqlServiceInterface.class},
proxyHandler);
MySqlServiceInterface proxy2 = (MySqlServiceInterface)Proxy.newProxyInstance(
MySqlService.class.getClassLoader(),
new Class[]{MySqlServiceInterface.class},
proxyHandler2);
proxy1.getName();
proxy2.getName();
}
private static class MySqlServiceReal implements MySqlServiceInterface {
@Override
public String getName() {
System.out.println("execute something sql");
saveName();
return "sql result";
}
@Override
public void saveName() {
System.out.println("save my name");
}
}
private static class MySqlServiceReal2 implements MySqlServiceInterface {
@Override
public String getName() {
saveName();
System.out.println("execute something sql");
return "sql result2";
}
@Override
public void saveName() {
System.out.println("save my name2");
}
}
private static class ProxyInvokeHandler implements InvocationHandler {
private Object target;
public ProxyInvokeHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("before method execute");
Object o = method.invoke(target, args);
System.out.println("after method execute");
return o;
}
}
private interface MySqlServiceInterface {
String getName();
void saveName();
}
}
注意:使用JDK动态代理时,被代理对象内部方法互相调用时,不会触发InvocationHandler
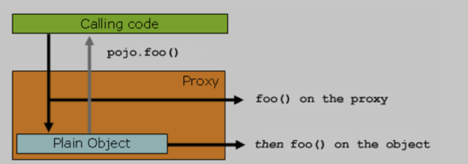
JDK动态代理存在的问题:
- 被代理的对象必须实现一个接口。
- 被代理对象内部方法互相调用不会触发拦截。
- 当我们写AOP的切点时,来拦截实现了某个接口的类时,当我们使用具体的类来进行依赖注入时会报错,只能使用接口类同时指定Bean的名称,因为容器中保留的并不是具体的类的Bean,而是代理对象的Bean。比如我们有接口I, 类A和类B实现了接口,如果使用了JDK动态代理,那么容器中存在的对象是实现了接口I的两个$Proxy0对象,而没有A,B两个类。(这一条存在的问题待详细研究)
2. CGLIB代理
通过设置代理对象的父类,通过继承的方式,对类功能进行扩展和方法调用的拦截。通过MethodInterceptor接口来拦截方法。被代理对象不需要实现特定接口,可以让内部方法互相调用也会触发方法拦截,但是Spring不会使用这种方法,Spring依然不会让内部方法互相调用产生拦截。简单实例代码如下:
public class CglibProxy {
public static void main(String[] arg) {
Enhancer enhancer = new Enhancer();
//设置增强器要继承的类
enhancer.setSuperclass(MySqlServiceReal.class);
// 设置放标调用拦截器
enhancer.setCallback(new MethodInterceptorImpl());
// 生成代理对象
MySqlServiceReal demo = (MySqlServiceReal)enhancer.create();
demo.getName();
}
public static class MySqlServiceReal{
public String getName() {
System.out.println("execute something sql");
saveName();
return "sql result";
}
public void saveName() {
System.out.println("save my name");
}
}
private static class MethodInterceptorImpl implements MethodInterceptor {
@Override
public Object intercept(Object object,
Method method,
Object[] args,
MethodProxy methodProxy) throws Throwable {
System.out.println("before");
Object res = methodProxy.invokeSuper(object, args);
System.out.println("After");
return res;
}
}
}
Spring使用CGLIB代理时,并不是使用
Object res = methodProxy.invokeSuper(object, args)来调用代理对象的父类方法。而是通过获取被代理的原始对象target,调用target的方法。 Object res = methodProxy.invoke(target, args);
下面是Spring中CGLIB拦截器中的部分代码:
// Get as late as possible to minimize the time we "own" the target, in case it comes from a pool...
// 获取被代理的原始对象
target = targetSource.getTarget();
Class<?> targetClass = (target != null ? target.getClass() : null);
// 获取拦截器链
List<Object> chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method, targetClass);
Object retVal;
// Check whether we only have one InvokerInterceptor: that is,
// no real advice, but just reflective invocation of the target.
if (chain.isEmpty() && Modifier.isPublic(method.getModifiers())) {
// We can skip creating a MethodInvocation: just invoke the target directly.
// Note that the final invoker must be an InvokerInterceptor, so we know
// it does nothing but a reflective operation on the target, and no hot
// swapping or fancy proxying.
Object[] argsToUse = AopProxyUtils.adaptArgumentsIfNecessary(method, args);
// 如果没有拦截器则直接调用原始方法
retVal = methodProxy.invoke(target, argsToUse);
}
我们可以写一个demo来模拟这种场景
public class ProxyTestMain {
public static void main(String[] arg) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MySqlServiceReal.class);
MySqlServiceReal target = new MySqlServiceReal();
//
enhancer.setCallback(new MethodInterceptorImpl(target));
//
MySqlServiceReal demo = (MySqlServiceReal)enhancer.create();
System.out.println(demo);
System.out.println(target);
demo.getName();
}
public static class MySqlServiceReal{
public String getName() {
System.out.println("execute something sql");
saveName();
return "sql result";
}
public void saveName() {
System.out.println("save my name");
}
}
private static class MethodInterceptorImpl implements MethodInterceptor {
private MySqlServiceReal target;
// 把被代理的对象传入进来,模拟Spring获取target的场景
public MethodInterceptorImpl(MySqlServiceReal real){
target = real;
}
@Override
public Object intercept(Object object,
Method method,
Object[] args,
MethodProxy methodProxy) throws Throwable {
System.out.println("before");
// Object res = methodProxy.invokeSuper(object, args);
// 调用target的方法
Object res = methodProxy.invoke(target, args);
System.out.println("After");
return res;
}
}
}
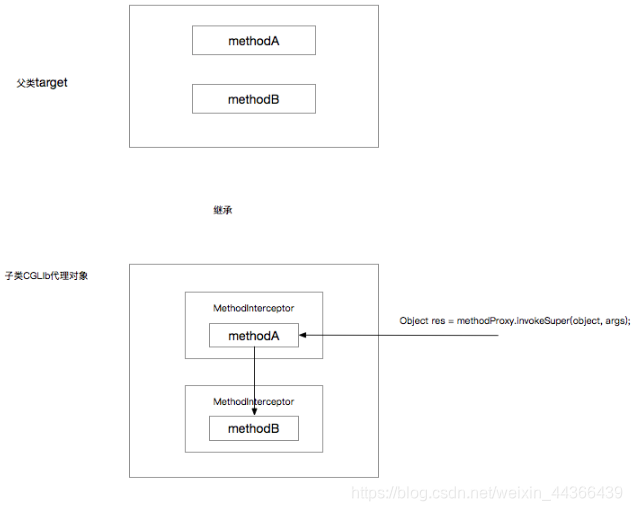
第一种场景将打印:
before
execute something sql
before
save my name
After
After
示意图(触发了MethodB的拦截器):
第二种场景将打印:
before
execute something sql
save my name
After
示意图(没有触发MethodB的拦截器):
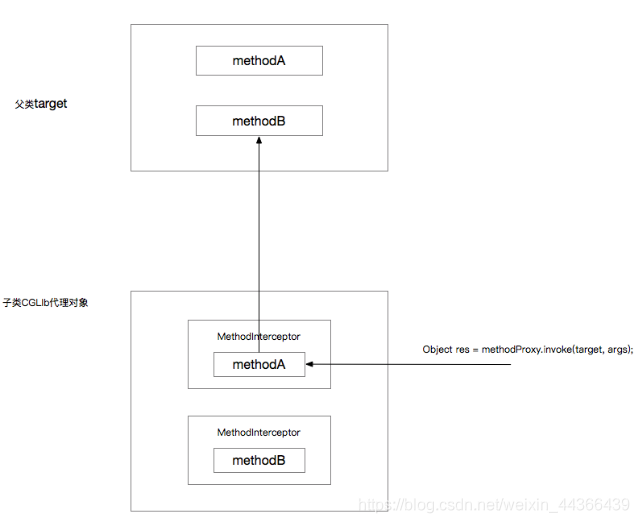
所以在Spring中,对象内部方法互相调用,被调用方法的AOP拦截将是无效的。
2.2.4 为什么使用AOP
所谓面向切面,就是把代码的执行流程认为是一个顺序的流,然后我们的AOP增强功能横向的切入这个流,以实现相应的功能增加,对于这个流本身来说,它可以不感知切面的存在。
如图2.2.1所示,在没有AOP功能的情况下,我们在代码执行的流程中想新增一个日志打印功能,我们可能需要在MethodB调用之前和之后新增一些代码,我们可以直接修改代码,在MethodB之前和之后各新增一行日志打印代码。
这存在的最主要的问题在于我们需要修改原有的代码,假设我们需要加入的新功能不止是打印一行代码这么简单,而且需要新增的地方不止这里,有很多地方,那么在代码中到处修改插入业务不关心的代码,会导致代码臃肿。
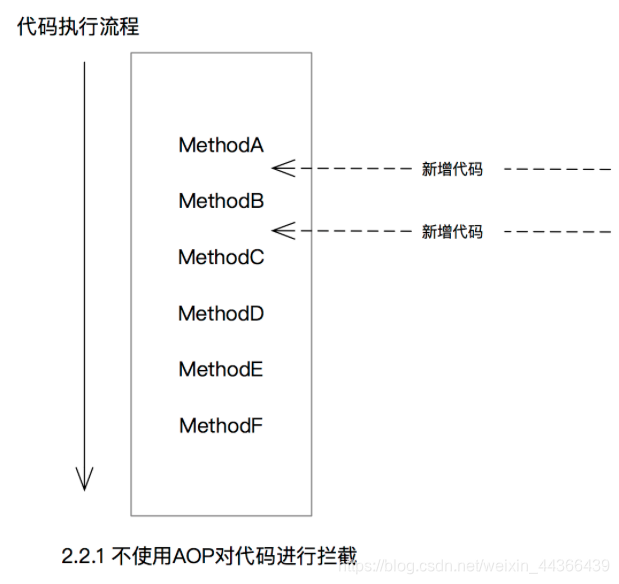
如果使用了AOP拦截,如图2.2.2所示,我们可以通过定义“切点”来设置方法拦截的地点,定义切点的操作使用AOP代码来完成的,业务代码可以完全不修改。之后我们可以在“切面”中实现相关的拦截逻辑。
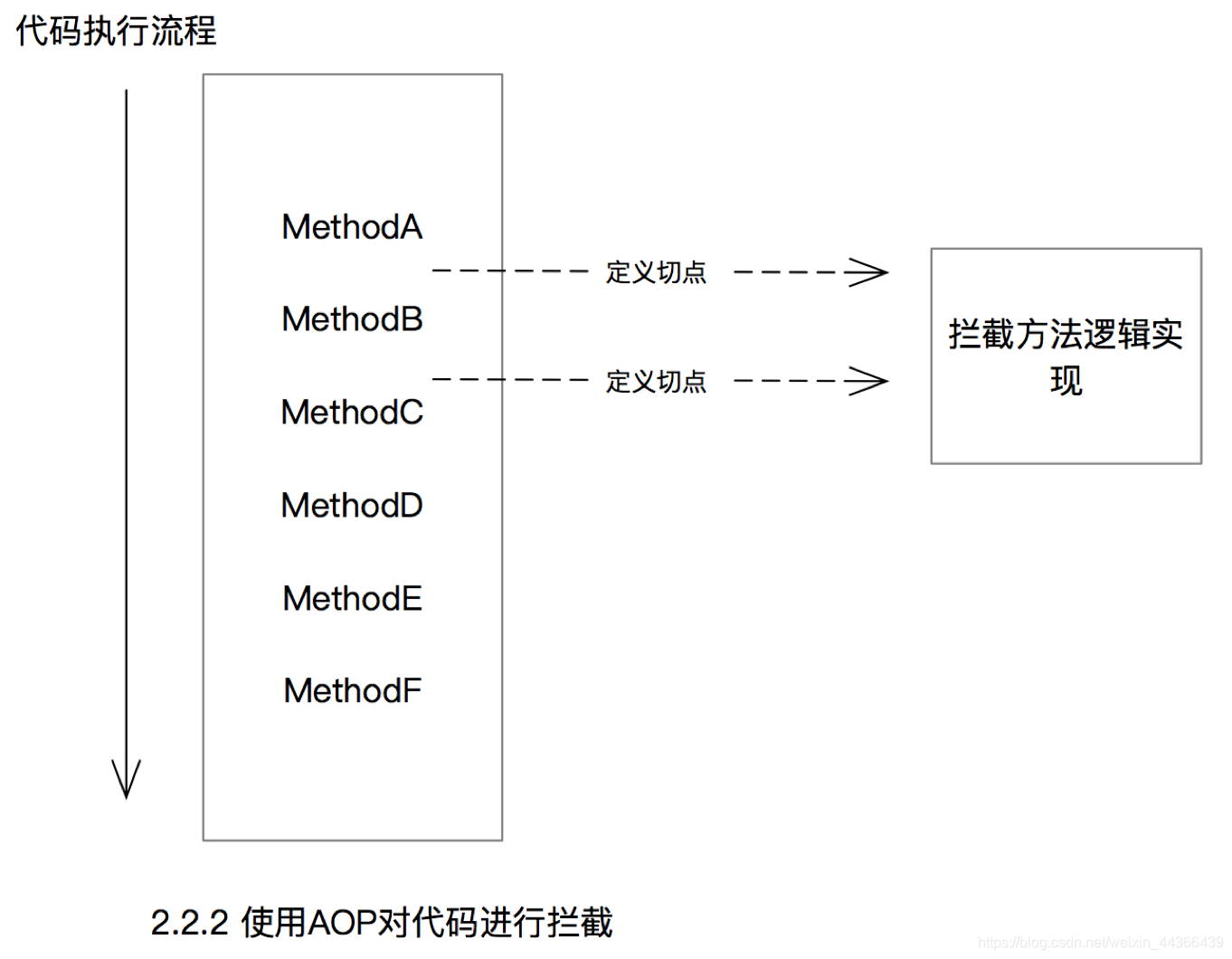
2.2.5 AOP会使用哪种代理
Spring会根据不同的情况来选择是否使用JDK动态代理或者CGLIB代理。具体实现我们可以在DefaultAopProxyFactory类中查看。
首先要了解JDK动态代理是基于接口interface的,只有某个类实现了接口,才可能会使用JDK动态代理。
通过下面代码,我们可以明确看出默认情况下对JDK动态代理和CGLIB代理选择的逻辑,影响因素有:
- config.isOptimize()如果开启了激进优化配置(默认关闭,这个还没深入研究)。
-
config.isProxyTargetClass()如果开启了类代理,表示目标类本身被代理,而不是它实现的接口。
(默认关闭,自动配置类为AopAutoConfiguration可以参考其源码进行配置)。 - hasNoUserSuppliedProxyInterfaces如果类没有实现接口(根据我们实现的代码来决定)。
- targetClass.isInterface()如果被代理的类是一个接口(被代理的类是可以完全没有任何实现的Interface)。
public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
@Override
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
// 1-3.如果配置中开启了激进优化配置或者开启了proxy-target-class强制使用代理类或者没有使用接口
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
// 4. 如果被代理的类是一个接口
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
// 使用JDK动态代理
return new JdkDynamicAopProxy(config);
}
//使用CGLIB代理
return new ObjenesisCglibAopProxy(config);
}
else {
// 使用JDK动态代理
return new JdkDynamicAopProxy(config);
}
}
}
2.2.6 AOP代码编写关键对象及AOP执行流程
我们通过编写一个切面Aspect对象,来抽象一个拦截面。
注解描述:
@Component: Spring启动时会将所有包涵这个注解的类实例化为Bean放入容器中。
@Aspect注解表示这是一个切面,Spring启动时会扫描所有包含这个注解的Bean的定义,扫描这个Bean的所有方法,将其封装抽象成一个个增强Advisor,用来对代理对象进行增强。
@Pointcut注解代表一个”切点”,所谓切点就是抽象了那些增强的方法具体的执行位置。比如下面例子中的annotationPointcut,代表着拦截所有包含了MyTransactional注解的方法。其他还有很多种编写方式,比如拦截某个类的某个方法,或者拦截实现了某个接口的类的所有方法等等。
@Around,@Before这些注解代表切面逻辑执行的时机,所谓Around就是环绕,就是在业务逻辑代码执行前可以做些什么,然后执行后还可以做些什么,而Before就是在业务代码执行前可以做些什么,类似的还有@After,@AfterReturning等等。
@Aspect
@Component
public class MchAspect implements Advice{
@Pointcut("within(com.mch.learn.spring..*)")
public void withinPointcut(){}
/**
* Any join point (method execution only in Spring AOP) where the executing method has an @Transactional annotation:
*/
@Pointcut("@annotation(com.mch.learn.spring.aop.MyTransactional)")
public void annotationPointcut(){}
@Around(value = "annotationPointcut()")
public Integer doAround(ProceedingJoinPoint pjp) throws Throwable {
System.out.println("doAround");
if (pjp.getArgs().length != 0) {
pjp.proceed();
}
return 123;
}
@Before(value = "annotationPointcut()")
public void doBefore(JoinPoint joinPoint) throws Throwable {
// start stopwatch
joinPoint.getArgs();
System.out.println("Before");
}
}
Spring AOP执行的流程:
Spring AOP 是通过BeanPostProcessor来进行处理的。每当实例化一个Bean时,会通过这个处理器来进行增强。增强的流程分为三步。
- 获取所有的增强器Advisor:
- 1.1: 获取所有的beanName,在beanFactory中所有注册的都提取出来。
- 1.2: 遍历找出所有声明了@AspectJ注解的类。
- 1.3: 对AspectJ注解的类进行增强器提取,解析其中的一些注解方法,比如@Around这种方法封装成Advice对象,@Pointcut这些封装成Pointcut对象,Advice对象加上Pointcut对象封装成一个Advisor对象。所以一个Advisor对象就记录了一个增强方法的执行时机地点和执行内容。
- 寻找与当前要创建的bean匹配的增强器,匹配
- 通过增强器创建代理对象。
这里详细的介绍有兴趣的同学可以参考我写的另外一个博客:
https://blog.csdn.net/weixin_44366439/article/details/88429403
2.3 ThreadLocal实现原理
ThreadLocal主要解决了:单例对象中的某属性,同时被多个线程互相隔离访问的问题。相当于为每个线程存储了属于该线程的一份拷贝。简单示例代码如下:
public class SingleObject {
private static volatile SingleObject singleObject;
private ThreadLocal<Integer> threadLocal;
private SingleObject() {
threadLocal = new ThreadLocal<>();
}
public static SingleObject getInstance() {
if (singleObject == null) {
synchronized (SingleObject.class) {
if (singleObject == null) {
singleObject = new SingleObject();
return singleObject;
} else {
return singleObject;
}
}
} else {
return singleObject;
}
}
public void setValue(Integer x){
threadLocal.set(x);
}
public Integer getValue(){
return threadLocal.get();
}
public static void main(String[] args) throws InterruptedException {
SingleObject singleObject = SingleObject.getInstance();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
singleObject.setValue(1);
System.out.println("线程1把值设置为1");
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1中的值为"+singleObject.getValue());
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
singleObject.setValue(1000);
System.out.println("线程2把值设置为1000");
}
});
thread1.start();
Thread.sleep(1000L);
thread2.start();
}
}
入上面代码所示,对于单例对象SingleObject有一个属性threadLocal,它记录了一个整数对象,同时被多个线程访问,其实多个线程访问的是各自线程的拷贝,不会互相干扰。这种情况通常用来获取数据库连接。后面讲Spring事务的时候会用到这一块的知识。
实现原理
:
public T get() {
// 获取当前正在执行的线程
Thread t = Thread.currentThread();
// 获取当前线程对应的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
每个线程对应着一个独立的ThreadLocalMap对象(可以参考Thread类的属性),该Map以ThreadLocal对象为key(上例中为threadlocal对象),以我们要存储的值为value(上例中的Integer对象)。也就是说上例中,线程1中记录了一个ThreadLocalMap对象,线程2中也记录了一个ThreadLocalMap对象,当我们分别在两个线程中执行threadlocal.get()时,相当于我们使用相同的key分别在两个map中执行了执行了get操作,key相同,容器不同,从而实现了数据的隔离。
https://blog.csdn.net/weixin_44366439/article/details/85637253
2.4 Mysql存储引擎Innodb的事务
事务的ACID特性:
A(Atomicity:原子性):要么全部完成,要么全部不完成,不可能停滞在中间某个环节。 通过commit, rollback机制实现。使用undo log实现,该log用于回滚事务,不用于数据恢复.
C(Consistency:一致性):(官方文档:The consistency aspect of the ACID model mainly involves internal InnoDB processing to protect data from crashes.) 事务保证数据不会被破坏,不会存在写了一半崩溃的情况。使用double write buffer实现,解决的是向磁盘文件写入时,写到一半掉电的问题。
I(Isolation:隔离性):事务的隔离级别。
D(Durability:持久性):指的是将数据持久化写入磁盘,采用了double write buffer,日志记录(redo log,binlog)以及fsync()调用写入磁盘。redo log是存储引擎级别的,写数据之前先写redo log,binlog是mysql级别的,持久化在,redo log之后,在存储引擎commit之前。
为了提高文件写入效率,现代操作系统中,用户调用write函数将数据写入文件时,操作系统通常会把数据暂存在一个内存缓冲区中,等到填满或者一段时间后再真正写入磁盘。如果计算机发生停机,那么内存缓冲区内的数据将丢失,所以操作系统提供了fsync函数强制将操作系统缓冲区中的数据立即写入磁盘。
2.3.1 事务隔离级别
1、 read-uncommitted
首先最低级的是读未提交,(read-uncommitted)
读未提交的意思就是我在事务A中可以读取到事务B未提交的变更值。这样会导致的问题是,如果B最终未提交该事务,回滚了,那么A读取到B变更的值就是一个错误的值。 我们把这种现象叫做脏读。
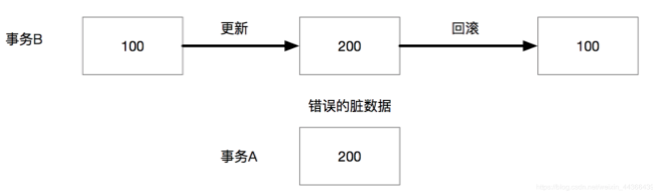
为了解决这个问题,我们必须要读取已经提交的修改才行,不能读那些还没有提交的随时可能被回滚的脏数据。于是升级为读已提交(read-committed)
2、 read-committed
读已提交就是会仅读取那些已经提交的变更,已经提交的变更都是有效的变更。所以不会出现读无效的脏数据的情况。但是随之而来的是另外一个问题,就是不可重复读的问题。意思很简单,就是A事务第一次读取变量X的值为100,第二次读取X的值变为200,这中途B事务提交了修改将X变为200.这种情况下,A事务对B事务有所感知,受到了B事务的影响,两次读到的值不一样,我们称之为不可重复读问题。
3、 repeatable-read
repeatable-read,可重复读。为了解决读已经提交级别中的不可重复读问题,我们升级到了可重复读级别。然后存在的问题就是幻读了,幻读指的是通过Insert后新增了记录,两次相同的查询条件而查询到的记录数不一样。 幻读会带来的一个影响主要是我们进行分页查询时,查询总数的sql和查询页数据的sql查询到不同的结论,会导致分页异常。 但是mysql的innodb存储引擎使用gap锁的机制来在可重复读的隔离级别下就解决了幻读问题。 具体原理可以参考MVCC机制和gap锁或者next-key锁。
4、 serializable
所有操作都上排它锁。串行化执行。一般不会使用。
2.3.2 可重复读隔离级别的实现原理
这里介绍可重复读的实现原理。在这之前需要了解Innodb有两种读模式,分别是一致性非锁定读(Consistent Nonlocking Reads)和锁定读(Locking Read)。通常也有人叫快照读和直接读。快照的建立是在事务启动后第一次执行查询操作时开始。参考MYSQL官方文档:
https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html
需要详细了解的可以参考:
https://blog.csdn.net/weixin_44366439/article/details/87297352#Consistent_Nonlocking_Reads_76。
要了解这一块的实现原理,需要了解Innodb的各种锁机制。
-
一致性非锁定读
一致性非锁定读采用了一种多版本控制的机制,来实现快照机制的读。
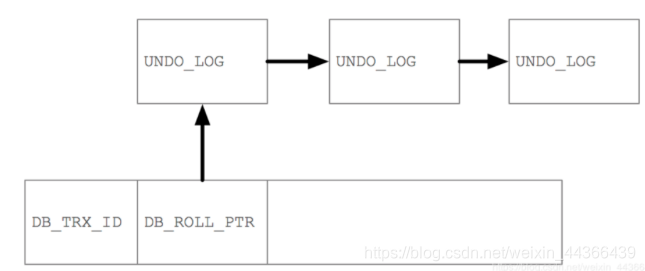
InndoDB的每行记录有一个6字节的事务编号DB_TRX_ID,存储了最近更新此记录的事务ID。还有8字节的DB_ROLL_PTR指针,指向事务的undo log。
事务ID在执行了第一次select时(不管是读的哪个表)产生,是主键增长的。对于可重复读级别,当发现记录的事务ID大于当前事务ID,则会根据undo log获取小于等于当前事务ID的记录版本。对于读已提交级别,则一直会读取最新已提交数据。
-
锁定读
不管在何种隔离级别下,如果我们使用select … for update 或者使用update 语句时,都会读到最新的数据,同时给这行数据上record行锁。在可重复读级别下,可能还会给相应的索引位加上GAP间隙锁。
举个例子,比如我们在一个可重复读的事务中,我们使用select * from t_user where user_id = 1 返回空,但是我们执行update t_user set user_name = “张三” where user_id = 1时,会成功更新这条记录。这里select操作是一致性非锁定读,update是锁定读。
三、Spring事务介绍
BeanFactoryTransactionAttributeSourceAdvisor
TransactionInterceptor
之前说到,Spring采用了AOP和ThreadLocal的方式来解决DAO层事务控制语句与业务层代码耦合的问题。
我们来看一下它是如何利用AOP功能和ThreadLocal来实现的。
3.1 传播级别
Spring事务的传播级别描述的是多个使用了@Transactional注解的方法互相调用时,Spring对事务的处理。
- REQUIRED, 如果当前线程已经在一个事务中,则加入该事务,否则新建一个事务。
- SUPPORT, 如果当前线程已经在一个事务中,则加入该事务,否则不使用事务。
- MANDATORY(强制的),如果当前线程已经在一个事务中,则加入该事务,否则抛出异常。
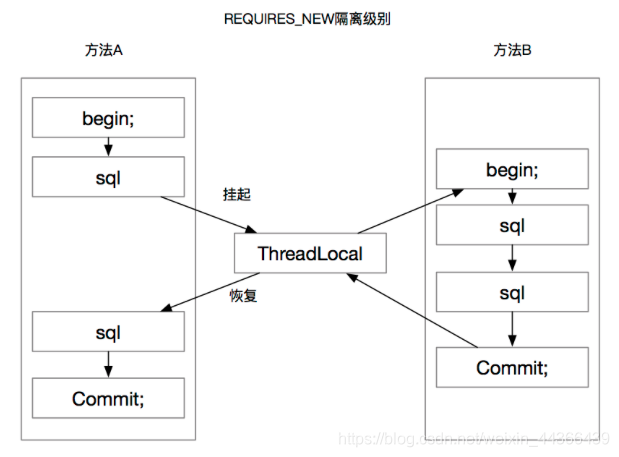
- REQUIRES_NEW,无论如何都会创建一个新的事务,如果当前线程已经在一个事务中,则挂起当前事务,创建一个新的事务。
- NOT_SUPPORTED,如果当前线程在一个事务中,则挂起事务。
- NEVER,如果当前线程在一个事务中则抛出异常。
- NESTED, 执行一个嵌套事务,有点像REQUIRED,但是有些区别,在Mysql中是采用SAVEPOINT来实现的。
Spirng默认的传播级别是REQUIRED, 我们常用的有REQUIRED和REQUIRES_NEW这两个,这里重点介绍一下REQUIRED和REQUIRES_NEW的区别。
REQUIRED表示当前方法必须在一个事务中,如果当前线程已经在一个事务中,则它会加入该事务,不会开启新的事务。比如方法A调用方法B时,方法A和方法B都有@Transactional注解。
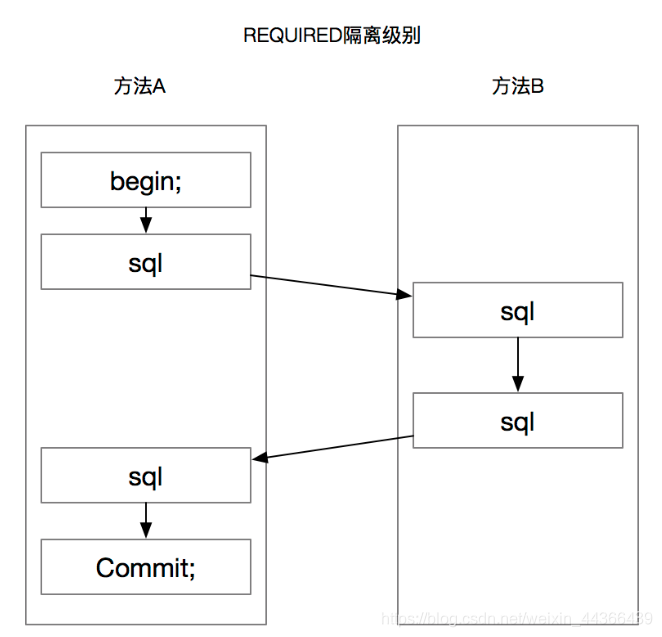
REQUIRES_NEW表示当前方法无论如何都会起一个新的事务。
3.2 主流程
前面AOP说到,AOP所有对方法拦截都会封装成一个MethodInterceptor放到一个责任链中执行。它对应的Advisor是BeanFactoryTransactionAttributeSourceAdvisor。
下面主要来分析TransactionInterceptor这个拦截方法的全景。
看TransactionInterceptor这个类的invoke方法
@Override
@Nullable
public Object invoke(MethodInvocation invocation) throws Throwable {
// 获取到被代理的类
Class<?> targetClass = (invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null);
// Adapt to TransactionAspectSupport's invokeWithinTransaction...
//使用事务执行
return invokeWithinTransaction(invocation.getMethod(), targetClass, invocation::proceed);
}
然后定位到TransactionAspectSupport类的invokeWithinTransaction方法中。我们可以在这个方法中看到Spring处理流程的:
- 获取事务属性,即解析@Transactional注解中的相关参数。
- 获取事务管理器,就是我们需要在@Transactional注解中的transactionManager参数。
- 收集事务信息,当前线程的事务状态,开启事务,并在当前线程中设置事务相关参数,标注了当前线程是运行在事务中的。
- 执行被拦截的方法业务代码,即被@Transactional注解标注的那个方法。
- 如果方法执行出现异常,做一些处理,可能会执行回滚操作或者设置回滚标志位。
- 清理事务环境,将设置到Threadlocal中的相关变量清除,就好像没有开启过事务一样。
- 提交事务
@Nullable
protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,
final InvocationCallback invocation) throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
// 1. 获取事务的属性
TransactionAttributeSource tas = getTransactionAttributeSource();
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
// 2. 获取事务管理器
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
// 如果是声明式事务
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// Standard transaction demarcation with getTransaction and commit/rollback calls.
// 3. 收集事务信息,状态,开启事务,在Threadlocal中设置相关变量
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// This is an around advice: Invoke the next interceptor in the chain.
// This will normally result in a target object being invoked.
// 4. 执行业务代码,即被@Transactional注解标注的方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// target invocation exception
// 5. 如果允许出现异常,执行处理,如回滚操作
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
// 6.清理事务环境,将3.中ThreadLocal中设置的变量清除
cleanupTransactionInfo(txInfo);
}
// 7.提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
// 如果是编程事务处理(省略)
else {
}
}
}
spring支持编程式事务管理和声明式事务管理两种方式。
-
编程式事务使用TransactionTemplate或者直接使用底层的PlatformTransactionManager。对于编程式事务管理,spring推荐使用TransactionTemplate。
声明式事务是建立在AOP之上的。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。 -
声明式事务最大的优点就是不需要通过编程的方式管理事务,这样就不需要在业务逻辑代码中掺杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过基于@Transactional注解的方式),便可以将事务规则应用到业务逻辑中。
这里我们仅讨论声明式事务,所以后面的代码省略
3.3 获取事务属性
这里method和targetClass是被@Transactional注解标注的方法和类。这里首先会从缓存里取,这样不用每次调用这个方法时都去解析一遍。根据通常情况下,这里的第一次创建都是在Bean创建的时候,就会扫描@Transactional,然后把属性存到缓存中。
这里我列了一下事务属性的相关字段:
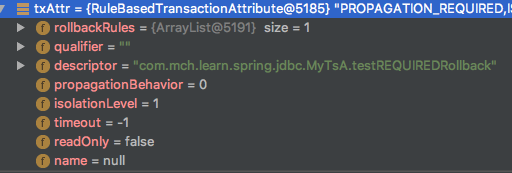
我们关心的字段:
- rollbackRules:rollbackFor参数,指定根据什么异常来回滚
- propagationBehavior:传播级别
- isolationLevel:隔离级别
public TransactionAttribute getTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
if (method.getDeclaringClass() == Object.class) {
return null;
}
// First, see if we have a cached value.
Object cacheKey = getCacheKey(method, targetClass);
TransactionAttribute cached = this.attributeCache.get(cacheKey);
if (cached != null) {
// Value will either be canonical value indicating there is no transaction attribute,
// or an actual transaction attribute.
if (cached == NULL_TRANSACTION_ATTRIBUTE) {
return null;
}
else {
return cached;
}
}
else {
// We need to work it out.
// 根据@Transactional注解找到事务属性
TransactionAttribute txAttr = computeTransactionAttribute(method, targetClass);
// Put it in the cache.
if (txAttr == null) {
this.attributeCache.put(cacheKey, NULL_TRANSACTION_ATTRIBUTE);
}
else {
String methodIdentification = ClassUtils.getQualifiedMethodName(method, targetClass);
if (txAttr instanceof DefaultTransactionAttribute) {
((DefaultTransactionAttribute) txAttr).setDescriptor(methodIdentification);
}
if (logger.isDebugEnabled()) {
logger.debug("Adding transactional method '" + methodIdentification + "' with attribute: " + txAttr);
}
this.attributeCache.put(cacheKey, txAttr);
}
return txAttr;
}
}
3.4 获取事务管理器TransactionManager
首先介绍一下什么是TransactionManager。
它保存着当前的数据源连接,对外提供对该数据源的事务提交回滚操作接口,同时实现了事务相关操作的方法。一个数据源DataSource需要一个事务管理器。
核心属性:
DataSource
内部核心方法:
public commit 提交事务
public rollback 回滚事务
public getTransaction 获得当前事务状态
protected doSuspend 挂起事务
protected doBegin 开始事务
protected doCommit 提交事务
protected doRollback 回滚事务
protected doGetTransaction() 获取事务信息
final getTransaction 获取事务状态
再介绍一下TransactionManager是如何获取的:
1、从注解中解析获得。
2、如果注解中没有标明,则从容器中找到一个实现了PlatformTransactionManager接口的Bean。如果这种接口的bean有多个,同时没有使用@Primary标注的话,就会报错。
所以我们尽量在写@Transactional注解时指定transactionManager参数,以指定开启的是哪个库的事务。否则当程序中有多个数据库连接时,如果使用了错误的事务管理器,会导致事务不生效。
3.5 开启事务,获取事务状态
处理流程:
- 获得事务对象DataSourceTransactionObject。
- 判断当前线程是否已经在事务中。
- 如果不在一个事务中,则获取事务的状态,并开启事务。
- 如果已经在一个事务中,则调用handleExistingTransaction,根据不同的传播级别进行不同的操作。
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException {
// 1. 获取事务对象
Object transaction = doGetTransaction();
// 2. 判断当前线程是否已经开启事务
if (isExistingTransaction(transaction)) {
// Existing transaction found -> check propagation behavior to find out how to behave.
// 4. 已经开启事务,根据不同传播级别执行不同操作
return handleExistingTransaction(definition, transaction, debugEnabled);
}
// ......省略部分代码......
// 空挂起操作
SuspendedResourcesHolder suspendedResources = suspend(null);
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
// 3.获取事务状态
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
//3. 开启事务
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException | Error ex) {
resume(null, suspendedResources);
throw ex;
}
}
下面一步一步进行分析
3.5.1 获取事务对象
@Override
protected Object doGetTransaction() {
// 新建了一个事务对象
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
txObject.setSavepointAllowed(isNestedTransactionAllowed());
// 根据事务管理器中的数据源获取当前线程的事务数据库连接,如果当前线程不存在线程的话,这里返回的连接是空。
ConnectionHolder conHolder =
(ConnectionHolder) TransactionSynchronizationManager.getResource(obtainDataSource());
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
注意到这里的TransactionSynchronizationManager这个类,这个类中记录了很多Threadlocal变量。文档说明是:
- Central delegate that manages resources and transaction synchronizations per thread.
- To be used by resource management code but not by typical application code.
是每个线程事务同步管理的代理中心,用来管理事务用到的相关资源。这个类中我们可以看到很多Threadlocal变量:
// 记录了当前线程中的一些事务资源,已知的有根据DataSource作为key,数据库链接作为value,在执行doBegin操作时会写入新的键值对。
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations =
new NamedThreadLocal<>("Transaction synchronizations");
private static final ThreadLocal<String> currentTransactionName =
new NamedThreadLocal<>("Current transaction name");
private static final ThreadLocal<Boolean> currentTransactionReadOnly =
new NamedThreadLocal<>("Current transaction read-only status");
private static final ThreadLocal<Integer> currentTransactionIsolationLevel =
new NamedThreadLocal<>("Current transaction isolation level");
private static final ThreadLocal<Boolean> actualTransactionActive =
new NamedThreadLocal<>("Actual transaction active");
3.5.2 判断当前线程是否已经开启事务
判断规则有两个,即当前线程的事务对象是否有connectionHolder,并且connectionHolder是否是事务激活状态。第一次进入事务方法时,connectionHolder是为空的。
那么什么时候会不为空呢?connectionHolder什么时候激活事务呢?
@Override
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
return (txObject.hasConnectionHolder() &&
txObject.getConnectionHolder().isTransactionActive());
}
3.5.3 如果当前线程不存在事务则开启新事务
首先要介绍一下事务状态TransactionStatus对象。
TransactionStatus被用来做什么:TransactionManager对事务进行提交或回滚时需要用到该对象,记录了当前事务的上下文,主要包括:
- 当前事务是否是一个新的事务还是加入别人的事务,事务传播级别REQUIRED和REQUIRE_NEW有用到。
- 是否有savepoint。
- 是否已经被设置了回滚标志位。回滚标志位的用途是子事务回滚时并不会真正回滚事务,而是设置一个回滚标志位,会根据相关事务的传播级别来决定何时回滚以及是否真正回滚。
- 事务是否已经完成。
开启事务主要存在下面几步
- 获得事务状态对象TransactionStatus
- 执行doBegin操作
- 然后将当前事务的相关属性如隔离级别设置到Threadlocal中。
首先看获取的事务状态对象,它的构造函数:
构造函数这里文档写的很清楚
- transaction是保存了内部事务实现的对象,这里通常是一个DataSourceTransactionObject类。
- newTransaction:事务是否是新建的,否则加入到一个已经存在的事务。
- newSynchronization:是否是新的同步器,这里通常是false,相当于有多少个Threadlocal管理的环境,通常都是一个。
- 是否只读
- suspendedResources:上一个被挂起的事务的相关信息,用于后面恢复挂起的事务。
/**
* Create a new {@code DefaultTransactionStatus} instance.
* @param transaction underlying transaction object that can hold state
* for the internal transaction implementation
* @param newTransaction if the transaction is new, otherwise participating
* in an existing transaction
* @param newSynchronization if a new transaction synchronization has been
* opened for the given transaction
* @param readOnly whether the transaction is marked as read-only
* @param debug should debug logging be enabled for the handling of this transaction?
* Caching it in here can prevent repeated calls to ask the logging system whether
* debug logging should be enabled.
* @param suspendedResources a holder for resources that have been suspended
* for this transaction, if any
*/
public DefaultTransactionStatus(
@Nullable Object transaction, boolean newTransaction, boolean newSynchronization,
boolean readOnly, boolean debug, @Nullable Object suspendedResources) {
this.transaction = transaction;
this.newTransaction = newTransaction;
this.newSynchronization = newSynchronization;
this.readOnly = readOnly;
this.debug = debug;
this.suspendedResources = suspendedResources;
}
在获取事务状态后,transactionManager会执行doBegin操作。doBegin操作主要做了4个事情: 1. 根据当前transactionManager保存的DataSource对象获取一个数据库连接con。 2. 设置隔离级别。 3. 执行con.setAutoCommit(false),表示开启事务。 4. 将这个数据库连接con绑定到当前线程,绑定方式是将DataSource为key,数据库连接con为value,将这个键值对保存到Threadlocal中的一个Map中,即上面介绍的resource对象中。
这里要思考,为什么Spring要以这种方式将数据库连接绑定到当前线程呢?为什么key是DataSource对象呢?
主要是了事务管理与数据访问服务的解耦,同时也保证了多线程环境下connection的线程安全问题。比如我们在写事务的时候,只需要指定@Transactional中的事务管理器transactionManager,这个事务管理器是一个单例对象,它的属性DataSource也是单例的,那么如何在多线程的情况下,如何让每个线程拥有自己的数据库连接呢?
所以这里使用Threadlocal的方式,每个线程中存一份,同时业务代码里不需要关心数据库连接的创建问题。同时由于存在多个事务上下文切换的情况,我们需要有一个地方来安全地保留这些数据库连接。
执行完doBegin操作后,会将事务状态TransactionStatus,事务管理器transactionManager,事务属性transactionAttrabute,封装成一个TransactionInfo对象,同时这个对象还包含了上一个事务的事务信息。它会把当前这个事务的事务信息存入Threadlocal中。
3.5.4 如果当前线程已经存在事务
我们这里主要讨论常用的REQUIRES_NEW和REQUIRED的区别
/**
* Create a TransactionStatus for an existing transaction.
*/
private TransactionStatus handleExistingTransaction(
TransactionDefinition definition, Object transaction, boolean debugEnabled)
throws TransactionException {
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
if (debugEnabled) {
logger.debug("Suspending current transaction, creating new transaction with name [" +
definition.getName() + "]");
}
// 挂起事务
SuspendedResourcesHolder suspendedResources = suspend(transaction);
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
doBegin(transaction, definition);
prepareSynchronization(status, definition);
return status;
}
catch (RuntimeException | Error beginEx) {
resumeAfterBeginException(transaction, suspendedResources, beginEx);
throw beginEx;
}
}
//*****省略NESTED传播级别的部分代码,这里主要讨论PROPAGATION_REQUIRES_NEW和PROPAGATION_REQUIRED的区别
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
}
从上面代码可以看到,当是REQUIREDS_NEW传播级别时,Spring会执行一个suspend操作,然后来创建一个新的TransactionStatus对象。即挂起当前事务开启一个新事务。然后对于REQUIRED的传播级别,则是直接返回,没有挂起和doBegin的操作。
这里有个问题请大家思考,A事务调用B事务,B事务的传播级别是REQUIRED,B事务会加入A事务,那么此时事务的隔离级别是B事务设置的隔离级别还是A事务设置的隔离级别呢?为什么呢?
我们可以看到,REQUIRED传播级别时,会执行到prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);第三个参数newTransaction和第四个参数都是false,然后运行到下面的地方时,可以看到并不会进入将新的隔离级别设置到Threadlocal的操作。
protected void prepareSynchronization(DefaultTransactionStatus status, TransactionDefinition definition) {
// 第一次开启事务时会进入这里,Synchronization可以理解为一个同步作用域,
// 后面就不会再进入了
if (status.isNewSynchronization()) {
TransactionSynchronizationManager.setActualTransactionActive(status.hasTransaction());
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(
definition.getIsolationLevel() != TransactionDefinition.ISOLATION_DEFAULT ?
definition.getIsolationLevel() : null);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(definition.isReadOnly());
TransactionSynchronizationManager.setCurrentTransactionName(definition.getName());
TransactionSynchronizationManager.initSynchronization();
}
}
同时,我们知道是在doBegin方法中执行了begin操作,由于REQUIRED传播级别是同一个事务,并没有执行额外的doBegin方法,一个事务在运行过程中是无法改变隔离级别的。
再做一个实验来验证,事务A的隔离级别是读未提交,事务B的隔离级别是读已提交。执行A事务,允许到第一次断点时,我们输出了用户列表userList为空,然后此时,我在命令行mysql中开启事务,并插入一条记录,insert into user values (77777, ‘未提交呢’,33); 然后代码允许到断点2时,userList2打印出了我新插入的这条记录,而我命令行的那个事务还未提交,所以可以说明代码运行到事务B时,隔离级别是读未提交,而不是事务B方法声明的读已提交。
// 事务A
@Transactional(rollbackFor = Exception.class, isolation = Isolation.READ_UNCOMMITTED)
public void A(){
myTsB.testREQUIRED();
}
//事务B
@Transactional(rollbackFor = RuntimeException.class, propagation = Propagation.REQUIRED, isolation = Isolation.READ_COMMITTED)
public void B(){
List<User> userList = userService.getUsers();
// 第一次断点
System.out.println(userList);
List<User> userList2 = userService.getUsers();
// 第一次断点
System.out.println(userList2);
user.setId(Long.valueOf(System.currentTimeMillis()/1000L).intValue() +1);
user.setName("REQUIRED_SON" + user.getId());
user.setAge(12);
userService.save(user);
}
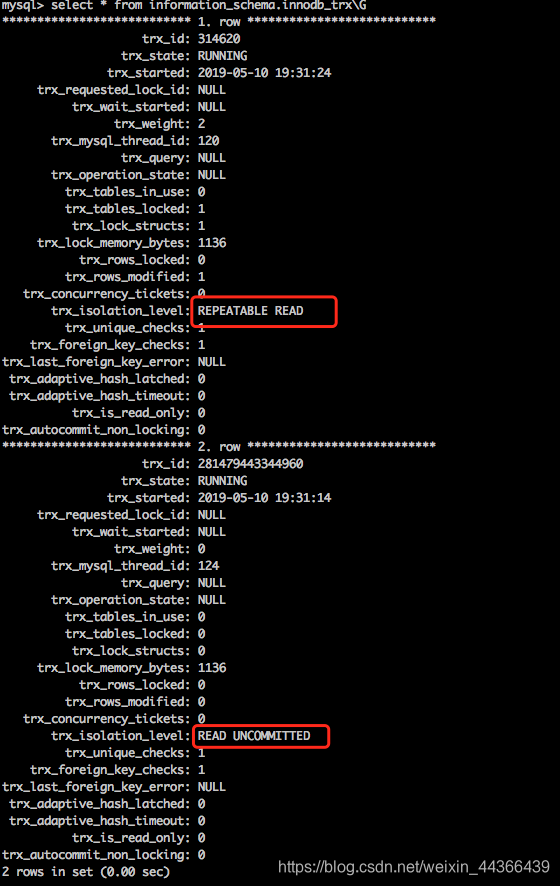
同时,我们可以在mysql中使用select * from information_schema.innodb_trx\G命令来查询当前mysql开启的事务。如下图:从图中可以看到,我们这里有两个事务,隔离级别分别是可重复读和读未提交,对应着命令行开启的事务和我代码断点的一个事务。虽然代码里写了两个方法A和B,但是它们是一个事务,B加入了A的事务,在DB中并没有发现读已提交的事务。
我们也可以找到数据库连接对象,执行 con.getTransactionIsolation();方法来查询这个连接的隔离级别。
设置隔离级别的方法在ConnectionImpl类中的setTransactionIsolation方法。
下面我们来看在REQUIRED_NEW的传播级别中,挂起事务这个操作具体做了什么。
@Nullable
protected final SuspendedResourcesHolder suspend(@Nullable Object transaction) throws TransactionException {
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List<TransactionSynchronization> suspendedSynchronizations = doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
//1. 执行挂起操作
suspendedResources = doSuspend(transaction);
}
// 2. 清空当前线程的事务配置
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName(null);
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(null);
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
return new SuspendedResourcesHolder(
suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
}
catch (RuntimeException | Error ex) {
// doSuspend failed - original transaction is still active...
doResumeSynchronization(suspendedSynchronizations);
throw ex;
}
}
else if (transaction != null) {
// Transaction active but no synchronization active.
Object suspendedResources = doSuspend(transaction);
return new SuspendedResourcesHolder(suspendedResources);
}
else {
// Neither transaction nor synchronization active.
return null;
}
}
@Override
protected Object doSuspend(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
txObject.setConnectionHolder(null);
// 这个就是将DataSource-Connection这个键值对从Threadlocal中移除
return TransactionSynchronizationManager.unbindResource(obtainDataSource());
}
从代码层面我们可以看到,suspend挂起事务,做的内容好像就是doBegin的逆向操作,清理当前线程绑定的一些信息,就像当前线程好像从来没有开启过事务一样。
所以在REQUIRES_NEW传播级别下,它挂起了上一个事务,并开启了自己的新事务,同时执行了新的doBegin操作,开启了另外一个完全新的事务,在Mysql层面也是两个事务。具体验证方法可以和前面验证REQUIRED传播级别类似。
3.6 传播级别对事务的影响
3.6.1 开始事务时的处理
其实开启事务我们在前面3.5章节讲过,对于当前线程已经存在事务的情况下,REQUIRED和REQUIRES_NEW传播级别的不同处理方式。REQUIRED是直接加入当前事务,不会执行新的doBegin操作,而REQUIRES_NEW会挂起当前事务,并执行doBegin操作开启一个新的事务。
3.6.2 提交事务的处理
前面我们看到,假如被拦截方法没有抛出异常,则会执行commitTransactionAfterReturning方法并最终进入到事务管理器中的commit方法。我们可以看到,当代码进入这里时,并不意味着事务会提交,可能会执行回滚。
如果事务状态被设置了回滚标志位,则执行回滚操作,那么问题来了,什么情况下会设置回滚标志位呢?
@Override
public final void commit(TransactionStatus status) throws TransactionException {
if (status.isCompleted()) {
throw new IllegalTransactionStateException(
"Transaction is already completed - do not call commit or rollback more than once per transaction");
}
DefaultTransactionStatus defStatus = (DefaultTransactionStatus) status;
// 如果事务状态被设置了回滚标志位,则执行回滚操作,那么问题来了,什么情况下会设置回滚标志位呢?
if (defStatus.isLocalRollbackOnly()) {
if (defStatus.isDebug()) {
logger.debug("Transactional code has requested rollback");
}
processRollback(defStatus, false);
return;
}
if (!shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
if (defStatus.isDebug()) {
logger.debug("Global transaction is marked as rollback-only but transactional code requested commit");
}
processRollback(defStatus, true);
return;
}
// 执行提交
processCommit(defStatus);
}
真正到了执行提交的地方,也并不一定会执行提交操作,会判断是否有savepoint保存点,还会判断是否是一个新的事务,如果不是一个新的事务比如传播为REQUIRED时,子事务并不是一个新的事务,所以子事务提交并不会真正提交mysql事务。
*/
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
boolean unexpectedRollback = false;
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Releasing transaction savepoint");
}
unexpectedRollback = status.isGlobalRollbackOnly();
status.releaseHeldSavepoint();
}
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction commit");
}
unexpectedRollback = status.isGlobalRollbackOnly();
doCommit(status);
}
else if (isFailEarlyOnGlobalRollbackOnly()) {
unexpectedRollback = status.isGlobalRollbackOnly();
}
//*****省略部分代码******//
3.6.3 回滚事务的处理
上一小节讲到,事务提交时可能会根据回滚标志位的设置,进行回滚或者提交。所以这里就介绍什么时候会设置回滚标志位,下面看一段代码:
这里是当执行回滚操作时执行的代码。也是在事务管理器中实现的:
可以看到:有三种情况,
1、如果有保存点会回滚到保存点,这种对应着NESTED传播级别,这里不详细介绍,主要是利用了mysql的savepoint来实现的。
2、如果是一个新的事务,则真正执行回滚操作。当是子事务是REQUIRES_NEW传播级别时,子事务也是一个新的事务,和父事务完全不关联,会直接回滚。
3、否则如果是加入一个其他事务的话,则设置回滚标志位。 这对应了子事务是REQUIRED传播级别时,不会真正回滚,而是设置回滚标志位,交由父事务执行回滚操作。
private void processRollback(DefaultTransactionStatus status, boolean unexpected) {
try {
boolean unexpectedRollback = unexpected;
try {
// 如果有保存点,则回滚到保存点
if (status.hasSavepoint()) {
if (status.isDebug()) {
logger.debug("Rolling back transaction to savepoint");
}
status.rollbackToHeldSavepoint();
}
// 如果是新事务,则直接执行回滚操作
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug("Initiating transaction rollback");
}
doRollback(status);
}
// 否则,是加入了其他的事务,这时候不会执行回滚操作,而是设置回滚标志位
else {
// Participating in larger transaction
if (status.hasTransaction()) {
if (status.isLocalRollbackOnly() || isGlobalRollbackOnParticipationFailure()) {
if (status.isDebug()) {
logger.debug("Participating transaction failed - marking existing transaction as rollback-only");
}
doSetRollbackOnly(status);
}
else {
if (status.isDebug()) {
logger.debug("Participating transaction failed - letting transaction originator decide on rollback");
}
}
}
}
}
}
小结:不同的传播级别,影响着事务方法直接的互相调用。主要体现在事务开启和事务结束时会根据不同传播级别进行不同的操作。
3.7 Spring如何使用Threadlocal管理连接
下面有一个新的问题:Spring为什么要用这些Threadlocal变量,我们目前只看到设置和清空,没看到在哪用呀??
初步设想:我们每次执行一条SQL时,都需要一个connection对象,隔离级别等配置都是配置在一个指定的connection连接上的。就算我们使用mybatis,底层也是jdbc,也需要一个connection对象,那它具体用哪个对象呢?肯定不能从连接池里随便拿一个。Spring框架不应该干扰业务,所以这里Spring应该是通过Threadlocal来指定用哪一个连接来执行方法里的SQL的。下一步需要看一下mybatis执行sql时是如何获取数据库连接的,是否与spring之间有一定的交互。
首先定位到mybatis的获取连接的地方,BaseExecutor类中,通过transaction对象获取连接,然后我们再定位transaction是如何获得的。
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) {
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
return connection;
}
}
最终定位到SpringManagedTransactionFactory类中,这个类是在org.mybatis.spring.transaction;包里,说明这是mybatis专门为了接入Spring来做的一个功能。
@Override
public Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit) {
return new SpringManagedTransaction(dataSource);
}
所以获取连接的方法就在SpringManagedTransaction类中。所以我们可以猜想,mybatis-spring获取数据库连接的方式,可能是我们之前讨论的从Threadlocal里面获取的!然后我们定位到获取设置连接的方法:
这里使用了DataSourceUtils类,这个是org.springframework.jdbc.datasource;的一个类,是spring对jdbc的一个封装。
private void openConnection() throws SQLException {
this.connection = DataSourceUtils.getConnection(this.dataSource);
this.autoCommit = this.connection.getAutoCommit();
this.isConnectionTransactional = DataSourceUtils.isConnectionTransactional(this.connection, this.dataSource);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug(
"JDBC Connection ["
+ this.connection
+ "] will"
+ (this.isConnectionTransactional ? " " : " not ")
+ "be managed by Spring");
}
}
下面看到真正获取数据库连接的地方DataSourceUtils类,这时候已经进入了Spring相关的代码:
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
// 从当前线程中获取数据库连接
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && (conHolder.hasConnection() || conHolder.isSynchronizedWithTransaction())) {
conHolder.requested();
if (!conHolder.hasConnection()) {
logger.debug("Fetching resumed JDBC Connection from DataSource");
conHolder.setConnection(dataSource.getConnection());
}
return conHolder.getConnection();
}
// Else we either got no holder or an empty thread-bound holder here.
logger.debug("Fetching JDBC Connection from DataSource");
Connection con = dataSource.getConnection();
// 如果当前线程支持同步,已经开启了一个事务
if (TransactionSynchronizationManager.isSynchronizationActive()) {
logger.debug("Registering transaction synchronization for JDBC Connection");
// Use same Connection for further JDBC actions within the transaction.
// Thread-bound object will get removed by synchronization at transaction completion.
ConnectionHolder holderToUse = conHolder;
if (holderToUse == null) {
holderToUse = new ConnectionHolder(con);
}
else {
holderToUse.setConnection(con);
}
holderToUse.requested();
TransactionSynchronizationManager.registerSynchronization(
new ConnectionSynchronization(holderToUse, dataSource));
holderToUse.setSynchronizedWithTransaction(true);
if (holderToUse != conHolder) {
//绑定到当前线程
TransactionSynchronizationManager.bindResource(dataSource, holderToUse);
}
}
return con;
}
果然,到最后还是看到了我们的老朋友TransactionSynchronizationManager类(3.1.5章节有介绍),它将一个以DataSource为key,Connection为value的一个Map存放到Threadlocal中,也就意味着同一个线程的同一个DataSource一定会取到同一个连接。所以如果我们想写一个类似mybatis的框架来接入spring事务管理,是需要在获取数据库连接这一块使用Spring的数据库连接管理的,也就是这种采用Threadlocal的方式。
综上所述, Spring采用Threadlocal的方式,来保证线程中的数据库操作使用的是同一个数据库连接。同时,采用这种方式可以使业务层使用事务时不需要感知并管理connection对象。通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
3.8 Spring事务使用的注意事项
3.8.1 为什么事务不生效
- 没有指定rollbackFor参数默认只会捕获RuntimeException来进行回滚。
- 没指定transactionManager参数,默认的transactionManager可能并不是你期望的,以及一个事务中涉及到了多个数据库。
- 对象内部方法互相调用不会被Spring的AOP拦截,@Transactional注解无效,可以使用AopContext.currentProxy()获取代理对象,然后用代理对象调用内部方法来解决。
- 如果AOP使用了CGLIB代理,事务方法或者类不是public,无法被外部包访问到,或者是final无法继承,@transactional注解无效。
如果一定要解决3的问题,可以使用AopContext.currentProxy()方法获取当前的代理对象,然后执行代理对象的方法。并且要把expose-proxy配置置为true,表示暴露代理对象到当前Threadlocal变量中。 不过通常还是不建议这么用,除非不得已而为之。因为这样很不’AOP’,业务代码感知到AOP的存在还要去感知代理对象的存在。
3.8.2 事务执行异常
- 采用了不恰当的传播级别,不会造成事务不生效,但是会造成事务的回滚和提交出乎意料,隔离级别可能会被父事务覆盖。
- 采用了不恰当的隔离级别,导致数据访问出乎意料,如循环cas操作却使用默认隔离级别(可重复读),导致每次cas读取一样无法更新记录。